angewandte multivariate statistik · angewandte multivariate statistikcomparison of ... wir wollen...
TRANSCRIPT

Angewandte Multivariate Statistik
Angewandte Multivariate Statistik
Prof. Dr. Ostap Okhrin
Ostap Okhrin 1 of 52

Angewandte Multivariate Statistik Comparison of Batches Boxplots
Explorative Datenanalyse
Eine alte 1000 Schweizer Franken Banknote.
Ostap Okhrin 2 of 52

Angewandte Multivariate Statistik Comparison of Batches Boxplots
Beispiel: Daten von der Schweizer Bank
Folgende Merkmalsvariablen einer 1000 Schweizer Franken
Banknote sind bekannt:
X1 = Länge der Banknote
X2 = Länge der Banknote auf der linken kurzen Seite
X3 = Länge der Banknote auf der rechten kurzen Seite
X4 = Abstand vom innen liegenden Bilderrahmen zur unteren Grenze
X5 = Abstand vom innen liegenden Bilderrahmen zur oberen Grenze
X6 = Länge der diagonalen Linie innerhalb des Bildes
Ostap Okhrin 3 of 52

Angewandte Multivariate Statistik Comparison of Batches Boxplots
Fortsetzung des Beispiels:
Ein Datensatz enthält Merkmale von 200 Schweizer Banknoten. DieHälfte der betrachteten Banknoten ist echt, die andere gefälscht.Es ist wichtig zwischen echten und gefälschten Banknotenunterscheiden zu können.Wir wollen Verfahren entwickeln, mit denen wir zwischen den echtenund den gefälschten Banknoten di�erenzieren können.Welche Werkzeuge können uns dabei helfen? Wie können wirUnterschiede visualisieren?
Ostap Okhrin 4 of 52

Angewandte Multivariate Statistik Comparison of Batches Boxplots
Boxplots
Boxplot
� ist eine Technik zur Visualisierung von Variablen-Verteilungen.
� hilft uns die Lage, Schiefe, Streuung, Spannweite und Ausreiÿerzu bestimmen.
� ist besonders nützlich beim Vergleich von Streu- und Lagemaÿe
� wird auch gra�sche Five Number Summary (Fünf PunkteZusammenfassung) genannt: Median, zwei Quartile und zweiExtremwerte
Ostap Okhrin 5 of 52
Angewandte Multivariate Statistik Comparison of Batches Boxplots
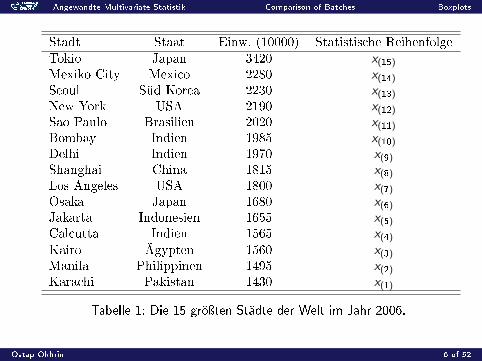
Stadt Staat Einw. (10000) Statistische ReihenfolgeTokio Japan 3420 x(15)Mexiko City Mexico 2280 x(14)Seoul Süd Korea 2230 x(13)New York USA 2190 x(12)Sao Paulo Brasilien 2020 x(11)Bombay Indien 1985 x(10)Delhi Indien 1970 x(9)Shanghai China 1815 x(8)Los Angeles USA 1800 x(7)Osaka Japan 1680 x(6)Jakarta Indonesien 1655 x(5)Calcutta Indien 1565 x(4)Kairo Ägypten 1560 x(3)Manila Philippinen 1495 x(2)Karachi Pakistan 1430 x(1)
Tabelle 1: Die 15 gröÿten Städte der Welt im Jahr 2006.
Ostap Okhrin 6 of 52

Angewandte Multivariate Statistik Comparison of Batches Boxplots
Five Number Summary
� Oberes Quartil FU� Unteres Quartil FL� Median = tiefster Punkt (Zentralwert)
� Extremwerte
Berücksichtigung der Order Statistics (statistischen Reihenfolge)→ Tiefe eines Datenwerts x(i): min{i , n − i + 1}
Tiefe eines Viertels =[Tiefe des Medians] + 1
2
Ostap Okhrin 7 of 52

Angewandte Multivariate Statistik Comparison of Batches Boxplots
Median
Order Statistics (Statistische Reihenfolge) {x(1), x(2), . . . , x(n)} ist einSet von geordneten Messwerten x1, x2, . . . , xndabei sei x(1) der kleinste und x(n) der gröÿte Messwert.Median M
M =
x( n+12 ) wenn n ungerade
1
2
{x( n
2)+ x( n
2+1)
}wenn n gerade
Ostap Okhrin 8 of 52

Angewandte Multivariate Statistik Comparison of Batches Boxplots
Aufbau des Boxplots
Median: 1815 (Wert von Datenpunkt 8)Quartile (Tiefe = 4.5): 1610=FL, 2105=FUExtremwerte (Tiefe = 1): 1430, 3420Interquartilsabstand: FU − FL = dFAntennen (Whisker) auÿerhalb der Box: FU + 1.5dF , FL − 1.5dF
1. Konstruiere die Box mit den Quartilen FU und FL
2. Kennzeichne den Median mit | und den Mittelwert mit...
3. Zeichne die Antennen (Whisker) mit a4. Markiere Ausreiÿer mit •, wenn sie auÿerhalb von
[FL − 1.5dF ,FU + 1.5dF ] liegen und mit ?, wenn sie auÿerhalbvon [FL − 3dF ,FU + 3dF ] liegen
Ostap Okhrin 9 of 52
●
1500
2000
2500
3000
World Cities
Val
ues
Boxplot
Population
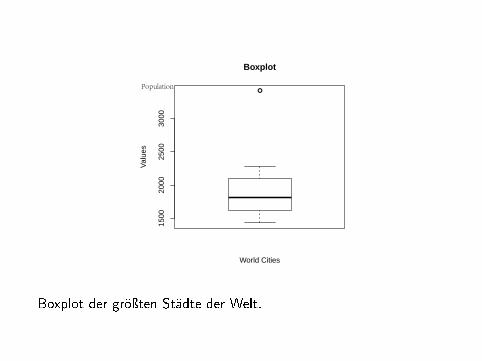
Boxplot der gröÿten Städte der Welt.
●
●
US JAPAN EU
1520
2530
3540
Car Datamileage
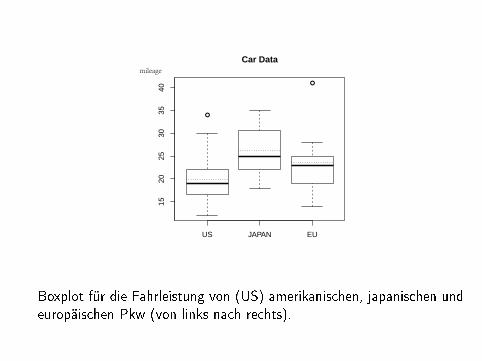
Boxplot für die Fahrleistung von (US) amerikanischen, japanischen undeuropäischen Pkw (von links nach rechts).
●
●
●
●
●●
GENUINE COUNTERFEIT
138
139
140
141
142
Swiss Bank Notes
X6
mm
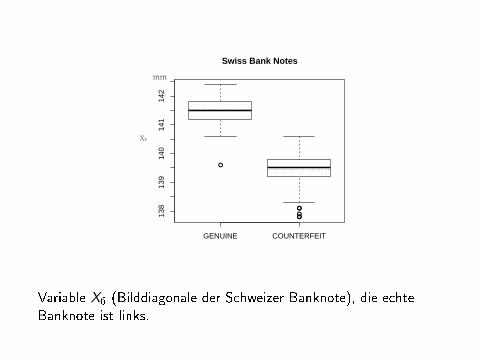
Variable X6 (Bilddiagonale der Schweizer Banknote), die echteBanknote ist links.
●●
●
●
GENUINE COUNTERFEIT
214
214.
521
521
5.5
216
Swiss Bank Notes
X1
mm
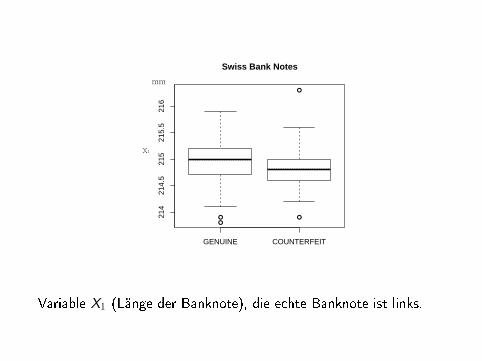
Variable X1 (Länge der Banknote), die echte Banknote ist links.

Angewandte Multivariate Statistik Comparison of Batches Boxplots
Zusammenfassung: Boxplots
� Median und Mittelwert sind Zentralwerte.
� Die relative Lage von Median (und Mittelwert) in der Box gilt alsMaÿwert für die Schiefe der Verteilung.
� Die Länge der Box ist ein Maÿwert für die Streuung der Daten(Interquartilsabstand).
� Die Länge der Antennen (Whisker) markiert die Spannweite derVerteilung.
Ostap Okhrin 14 of 52

Angewandte Multivariate Statistik Comparison of Batches Boxplots
Zusammenfassung: Boxplots
� Die Ausreiÿer werden mit • dargestellt, wenn sie auÿerhalb[FL − 1.5dF ,FU + 1.5dF ] liegen und mit ?, wenn sie auÿerhalb[FL − 3dF ,FU + 3dF ] liegen
� Durch Boxplots kann man nicht auf Multimodalitäten oderCluster schlieÿen.
� Vergleicht man die relativen Gröÿen und Lagen der Boxplots,vergleicht man Verteilungen miteinander.
Ostap Okhrin 15 of 52

Angewandte Multivariate Statistik Comparison of Batches Histogramme
Histogramme
f̂h(x) = n−1h−1∑j∈Z
n∑i=1
I{xi ∈ Bj(x0, h)}I{x ∈ Bj(x0, h)}
� Bj(x0, h) = [x0 + (j − 1)h, x0 + jh), j ∈ Z.� [., .) bezeichnet ein links geschlossenes, rechts geö�netes Intervall.
� I{•} bezeichnet die Indikator Funktion.� h ist ein Glättungsparameter und kontrolliert die Klassenbreite im
Histogramm.
Ostap Okhrin 16 of 52
Swiss Bank Notes
h = 0.1
Dia
gona
l
138 139 140 141
04
8
Swiss Bank Notes
h = 0.3
Dia
gona
l
138 139 140 141
010
2030
Swiss Bank Notes
h = 0.2
Dia
gona
l
138 139 140 141
05
15
Swiss Bank Notes
h = 0.4
Dia
gona
l
138 139 140 141
020
40
mm
mm
mm
mm
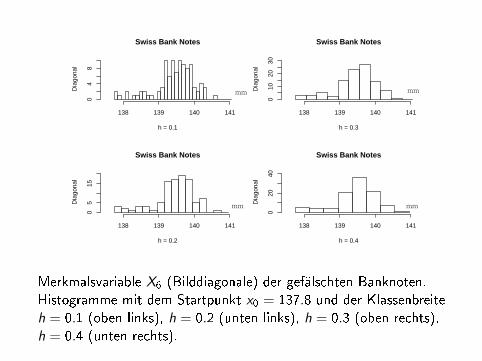
Merkmalsvariable X6 (Bilddiagonale) der gefälschten Banknoten.Histogramme mit dem Startpunkt x0 = 137.8 und der Klassenbreiteh = 0.1 (oben links), h = 0.2 (unten links), h = 0.3 (oben rechts),h = 0.4 (unten rechts).
Swiss Bank Notes
x_0 = 137.65
Dia
gona
l
138 139 140 141
020
40
Swiss Bank Notes
x_0 = 137.85
Dia
gona
l
138 139 140 141
020
40
Swiss Bank Notes
x_0 = 137.75
Dia
gona
l
138 139 140 141
020
40
Swiss Bank Notes
x_0 = 137.95
Dia
gona
l
138 139 140 141
020
40
mm mm
mm mm
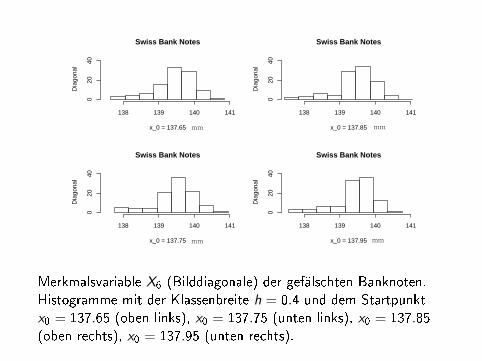
Merkmalsvariable X6 (Bilddiagonale) der gefälschten Banknoten.Histogramme mit der Klassenbreite h = 0.4 und dem Startpunktx0 = 137.65 (oben links), x0 = 137.75 (unten links), x0 = 137.85(oben rechts), x0 = 137.95 (unten rechts).

Angewandte Multivariate Statistik Comparison of Batches Histogramme
Zusammenfassung: Histogramme
� Die Modalklasse lässt sich aus einem Histogramm ablesen.
� Die Modalklasse entspricht dem gröÿten Viereck im Histogramm.Das ist jene Klasse mit der gröÿten Häu�gkeitsdichte.
� Histogramme mit der selben Klassenbreite h müssen nichtidentisch sein. Ihr Aussehen sind abhängig vom Startpunkt x0.
� Der Ein�uss des Startpunktes x0 ist enorm. Eine Änderung von x0kann das Aussehen des Histogramms drastisch beein�ussen.
Ostap Okhrin 19 of 52

Angewandte Multivariate Statistik Comparison of Batches Histogramme
Zusammenfassung: Histogramme
� Wird die Klassenbreite h zu groÿ gewählt, ist das Histogramm zu�ach und unstrukturiert.
� Eine zu kleine Klassenbreite h lässt das Histogramm instabilwerden.
� Die optimale Klassenbreite kann mit hopt =(24√π
n
) 13geschätzt
werden.
� Es wird empfohlen stetige Dichtefunktionen zu schätzen, wie zumBeispiel kernel densities (Kerndichte).
Ostap Okhrin 20 of 52

Angewandte Multivariate Statistik Comparison of Batches Kerndichteschätzer
Kernel densities (Kerndichte)
Die Dichte kann wie folgt geschätzt werden
f̂h(x) = n−1(2h)−1n∑
i=1
I(|x − xi | ≤ h)
Des Weiteren ist K (u) = I (|u| ≤ 1/2)
f̂h(x) = n−1h−1n∑
i=1
K
(x − xi
h
)K ist der Kern (kernel).
Ostap Okhrin 21 of 52

Angewandte Multivariate Statistik Comparison of Batches Kerndichteschätzer
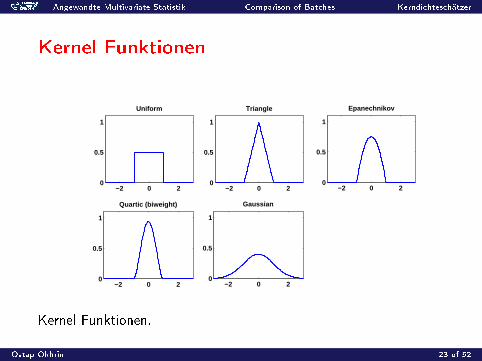
Kernel Funktionen
K (•) Kernel
K (u) = 1
2I(|u| ≤ 1) Uniform
K (u) = (1− |u|)I(|u| ≤ 1) TriangleK (u) = 3
4(1− u2)I(|u| ≤ 1) Epanechnikov
K (u) = 15
16(1− u2)2I(|u| ≤ 1) Quartic (Biweight)
K (u) = 1√2π
exp(−u2
2) = ϕ(u) Gaussian
Tabelle 2: Kernel Funktionen.
Ostap Okhrin 22 of 52
Angewandte Multivariate Statistik Comparison of Batches Kerndichteschätzer
Kernel Funktionen
−2 0 20
0.5
1
Uniform
−2 0 20
0.5
1
Triangle
−2 0 20
0.5
1
Epanechnikov
−2 0 20
0.5
1
Quartic (biweight)
−2 0 20
0.5
1
Gaussian
Kernel Funktionen.
Ostap Okhrin 23 of 52
137 138 139 140 141 142 143
0.0
0.2
0.4
0.6
0.8
Swiss bank notes
Counterfeit / Genuine
Den
sity
est
imat
es fo
r di
agon
als
mm
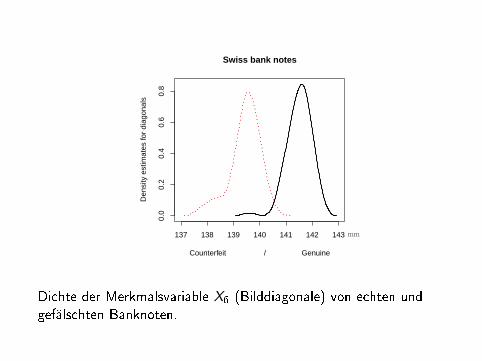
Dichte der Merkmalsvariable X6 (Bilddiagonale) von echten undgefälschten Banknoten.

Angewandte Multivariate Statistik Comparison of Batches Kerndichteschätzer
Festlegen der Bandbreite h
Silvermans Daumenregel
Gaussian kernel
K (u) =1√2π
exp(−u2
2)
hG = 1.06σ̂n−15
Quartic kernel
K (u) =15
16(1− u2)2I(|u| ≤ 1)
hQ = 2.62hG
Standardabweichung der Stichprobe: σ̂ =
√n−1
n∑i=1
(xi − x̄)2
Ostap Okhrin 25 of 52
0.02 0.04 0.06
0.08
0.1
0.1
0.12
0.12
0.14
0.14
0.16
0.16
0.18
9 10 11
138
139
140
141
142
143
12
X6
X5
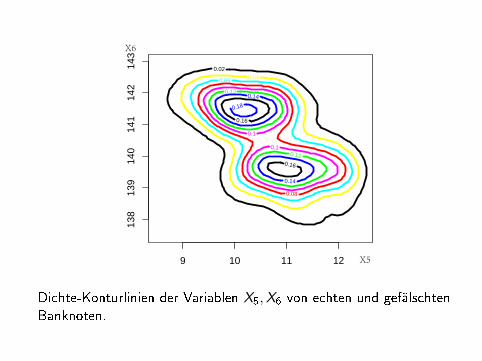
Dichte-Konturlinien der Variablen X5,X6 von echten und gefälschtenBanknoten.

Dichte (Umrisse) der Variablen X4,X5,X6 von echten und gefälschtenBanknoten.

Angewandte Multivariate Statistik Comparison of Batches Kerndichteschätzer
Zusammenfassung: Kernel densities
� Die Kerneldichte schätzt die Verteilungsdichte mit dersogenannten Kernel Methode.
� Die Bandbreite h bestimmt über den Glättungsgrad desgeschätzten f̂ .
� Kernel densities sind Glättungsfunktionen. Mit ihnen könnenVerteilungen gra�sch dargestellt werden (ab 3 Dimensionen).
Ostap Okhrin 28 of 52

Angewandte Multivariate Statistik Comparison of Batches Kerndichteschätzer
Zusammenfassung: Kernel densities
� Die Bandbreite kann mit der Hilfe der einfachen DaumenregelhG = 1.06σ̂n−1/5. berechnet werden, sollte aber nur zusammenmit dem Kernel ϕ angewendet werden.
� Kerneldichteschätzer sind explorative Werkzeuge zur Bestimmungvon Modi, Lage, Schiefe, Ausläufer der Verteilung, Asymmetrien,etc.
Ostap Okhrin 29 of 52

Angewandte Multivariate Statistik Comparison of Batches Streudiagramme
Scatterplots (Streudiagramme)
Streudiagramme - bivariate oder trivariate Gegenüberstellung vonVariablen
� (3D)-Datenrotation
� Trennlinien
� Draftman's Plot (Paarweise Streudiagrammmatrix)
� Koordinatensysteme mit parallelen Achsen
Ostap Okhrin 30 of 52
●
●
●●
●
●●
●●
●
●
●
●
●●
●●
●
●
●
●●
●●
●
●●
●●
●●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●●
●●
●●●
●●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●
● ●
●
●
●●
●
●
7 8 9 10 11 12 13
138
139
140
141
142
Swiss bank notes
upper inner frame (X5)
diag
onal
(X
6)
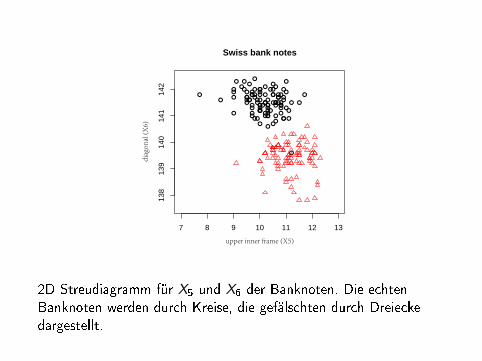
2D Streudiagramm für X5 und X6 der Banknoten. Die echtenBanknoten werden durch Kreise, die gefälschten durch Dreieckedargestellt.
Swiss bank notes
●●
●●●
●
●
●
●
●
● ●
●
●
●
●●
●
●●
●●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●●
●
●
●●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
8 10 11 13 14 8 9 10 11 12
139
140
140
141
142
Lower inner frame (X4) Upper inner frame (X5)
Dia
gona
l (X
6)
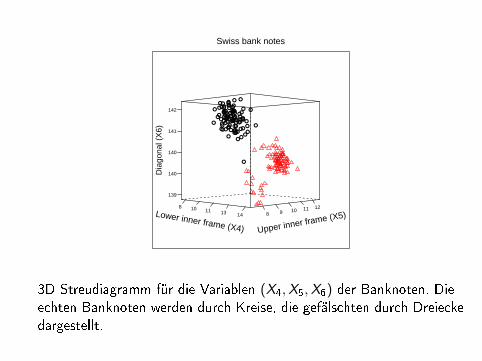
3D Streudiagramm für die Variablen (X4,X5,X6) der Banknoten. Dieechten Banknoten werden durch Kreise, die gefälschten durch Dreieckedargestellt.

3
X
Y
128.5 129.0 129.5 130.0 130.5 131.0 131.5
78
910
1112
13
X
Y
128.5 129.0 129.5 130.0 130.5 131.0 131.5
78
910
1112
13
X
Y
128.5 129.0 129.5 130.0 130.5 131.0 131.5
137
138
139
140
141
142
143
●●
●
●
●●
●
●
●
●
● ●
●
●●●
●●●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●
●●
●
●●
●
●●
●
●●●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
● ●
●●
●
●●
●
●
●
●
●●●
●
● ●
●
●
●●
●
●
●
●
●
●
7 8 9 10 11 12
129.
012
9.5
130.
013
0.5
131.
0
X
Y
4
X
Y
7 8 9 10 11 12 13
78
910
1112
13
X
Y
7 8 9 10 11 12 13
137
138
139
140
141
142
143
●●
●
●
●●
●
●
●
●
●●
●
●● ●
●●●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●●●
●
●●
●
● ●
●
●●●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●●
●●
●
●●
●
●
●
●
●● ●
●
●●
●
●
●●
●
●
●
●
●
●
8 9 10 11 12
129.
012
9.5
130.
013
0.5
131.
0
X
Y
●
●
●
●
●
●
●● ●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●●●
●
●
● ●●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
● ●●
●●
● ●
●
●
● ●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
8 9 10 11 12
78
910
1112
X
Y
5
X
Y
7 8 9 10 11 12 13
137
138
139
140
141
142
143
●●
●
●
●●
●
●
●
●
● ●
●
●●●●●
●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●
●●
●
●●
●
●●
●
●●●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
● ●
●●
●
●●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●
●
●
●
138 139 140 141 142
129.
012
9.5
130.
013
0.5
131.
0
X
Y
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●
●●
●
● ●●
●
●
●●●
●
●
●
●●
●●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●● ●
●●
● ●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
138 139 140 141 142
78
910
1112
X
Y
●●
●
●●●
●
●●
●● ●
●
●●
●
●●
●
● ●
●●
●
●
●●
●
●
●
●
●●
●
●●●●●
●
●
●●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●●
●
●
●
●
●
●
●●
●
●●
●
●●●
●
● ●●●
●
●
●
●
●
●
● ●●●
●
●●●
●
138 139 140 141 142
89
1011
12
X
Y
6
X
X
X
X
Draftman's Plot der Banknoten. Die Bilder in der linken Spalte zeigendie Variablenpaare (X3,X4), (X3,X5) und (X3,X6), in der Mittewerden (X4,X5) sowie (X4,X6) und unten rechts (X5,X6) dargestellt.Die obere rechte Hälfte stellt die korrespondierendenDichte-Konturlinien-Plots dar (density contour plots).

Angewandte Multivariate Statistik Comparison of Batches Streudiagramme
Zusammenfassung: Scatterplots
� 2D- und 3D-Streudiagramme machen einzelne Punkte, ganzeWolken oder Subcluster sichtbar.
� Sie zeigen positive oder negative Abhängigkeiten zwischenVariablen.
� Draftman's Plot (Streudiagramm-Matrix) wird zum Erkennen vonStrukturen verwendet, die durch die Werte der Variablen bedingtsind.
Ostap Okhrin 34 of 52

Angewandte Multivariate Statistik Comparison of Batches Cherno�-Flury Gesichter
Cherno�-Flury Faces (Cherno�-Gesichter)
Index
91
Index
92
Index
93
Index
94
Index
95
Index
96
Index
97
Index
98
Index
99
Index
100
Index
101
Index
102
Index
103
Index
104
Index
105
Index
106
Index
107
Index
108
Index
109
Index
110
Cherno�-Flury faces für die 91. bis 110. beobachtete Banknote imDatensatz.
Ostap Okhrin 35 of 52

Angewandte Multivariate Statistik Comparison of Batches Cherno�-Flury Gesichter
Sechs Variablen - Gesichtseigenschaften
X1 = 1, 19 (Augengröÿe)
X2 = 2, 20 (Pupillengröÿe)
X3 = 4, 22 (Stellung der Augen)
X4 = 11, 29 (oberer Haaransatz)
X5 = 12, 30 (unterer Haaransatz)
X6 = 13, 14, 31, 32 (Gesichtsfalten und Haarfarbe)
Ostap Okhrin 36 of 52

Index
1
Index
2
Index
3
Index
4
Index
5
Index
6
Index
7
Index
8
Index
9
Index
10
Index
11
Index
12
Index
13
Index
14
Index
15
Index
16
Index
17
Index
18
Index
19
Index
20
Index
21
Index
22
Index
23
Index
24
Index
25
Index
26
Index
27
Index
28
Index
29
Index
30
Index
31
Index
32
Index
33
Index
34
Index
35
Index
36
Index
37
Index
38
Index
39
Index
40
Index
41
Index
42
Index
43
Index
44
Index
45
Index
46
Index
47
Index
48
Index
49
Index
50
Observations 1 to 50
Flury faces der 1.-50. beobachteten Banknote im Datensatz.

Index
51
Index
52
Index
53
Index
54
Index
55
Index
56
Index
57
Index
58
Index
59
Index
60
Index
61
Index
62
Index
63
Index
64
Index
65
Index
66
Index
67
Index
68
Index
69
Index
70
Index
71
Index
72
Index
73
Index
74
Index
75
Index
76
Index
77
Index
78
Index
79
Index
80
Index
81
Index
82
Index
83
Index
84
Index
85
Index
86
Index
87
Index
88
Index
89
Index
90
Index
91
Index
92
Index
93
Index
94
Index
95
Index
96
Index
97
Index
98
Index
99
Index
100
Observations 51 to 100
Flury faces der 51.-100. beobachteten Banknote im Datensatz.
Index
101
Index
102
Index
103
Index
104
Index
105
Index
106
Index
107
Index
108
Index
109
Index
110
Index
111
Index
112
Index
113
Index
114
Index
115
Index
116
Index
117
Index
118
Index
119
Index
120
Index
121
Index
122
Index
123
Index
124
Index
125
Index
126
Index
127
Index
128
Index
129
Index
130
Index
131
Index
132
Index
133
Index
134
Index
135
Index
136
Index
137
Index
138
Index
139
Index
140
Index
141
Index
142
Index
143
Index
144
Index
145
Index
146
Index
147
Index
148
Index
149
Index
150
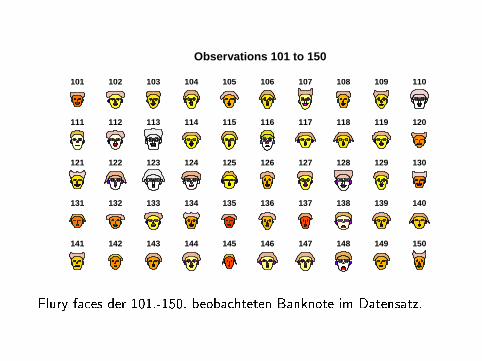
Observations 101 to 150
Flury faces der 101.-150. beobachteten Banknote im Datensatz.
Index
151
Index
152
Index
153
Index
154
Index
155
Index
156
Index
157
Index
158
Index
159
Index
160
Index
161
Index
162
Index
163
Index
164
Index
165
Index
166
Index
167
Index
168
Index
169
Index
170
Index
171
Index
172
Index
173
Index
174
Index
175
Index
176
Index
177
Index
178
Index
179
Index
180
Index
181
Index
182
Index
183
Index
184
Index
185
Index
186
Index
187
Index
188
Index
189
Index
190
Index
191
Index
192
Index
193
Index
194
Index
195
Index
196
Index
197
Index
198
Index
199
Index
200
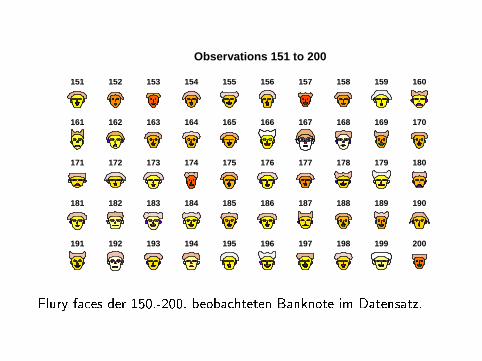
Observations 151 to 200
Flury faces der 150.-200. beobachteten Banknote im Datensatz.

Angewandte Multivariate Statistik Comparison of Batches Cherno�-Flury Gesichter
Zusammenfassung: Cherno�-FluryFaces
� Gesichter (Faces) können genutzt werden, um Untergruppen ineinem multivariaten Datensatz aufzudecken.
� Beobachtungen innerhalb einer Untergruppen haben ähnlicheGesichter.
� Ausreiÿer können durch extrem di�erenzierte Gesichteridenti�ziert werden (z.B. dunkles Haar, lächelndes oderglückliches Gesicht).
� Ist ein Element von X unüblich, wird sich das korrespondierendeGesichtselement in seiner Gestalt signi�kant von anderenunterscheiden.
Ostap Okhrin 41 of 52

Angewandte Multivariate Statistik Comparison of Batches Andrews Kurven
Andrews Kurven
Jede multivariate Beobachtung Xi = (Xi ,1, ..,Xi ,p) ∈ Rp kann, wiefolgt, in eine Kurve transformiert werden
� p ist ungerade
fi (t) =Xi,1√
2+Xi,2 sin(t)+Xi,3 cos(t)+. . .+Xi,p−1 sin
(p − 1
2t
)+Xi,p cos
(p − 1
2t
)
� p ist gerade
fi (t) =Xi,1√
2+ Xi,2 sin(t) + Xi,3 cos(t) + . . .+ Xi,p sin
(p2t)
Die Beobachtung entspricht den Koe�zienten einer sogenanntenFourier Reihe, t ∈ [−π, π].
Ostap Okhrin 42 of 52

Angewandte Multivariate Statistik Comparison of Batches Andrews Kurven
Andrews Kurven
� Untergruppen werden charakterisiert durch ähnliche Kurven.
� Ausreiÿer entsprechen einzelnen Kurven, die sich stark vonanderen Kurven abheben.
� Die Reihenfolge der Variablen spielt bei der Interpretation einewichtige Rolle.
Ostap Okhrin 43 of 52
Angewandte Multivariate Statistik Comparison of Batches Andrews Kurven
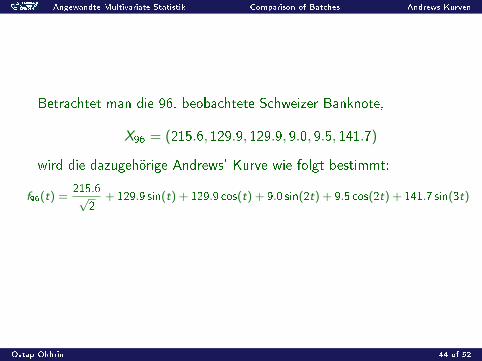
Betrachtet man die 96. beobachtete Schweizer Banknote,
X96 = (215.6, 129.9, 129.9, 9.0, 9.5, 141.7)
wird die dazugehörige Andrews' Kurve wie folgt bestimmt:
f96(t) =215.6√
2+ 129.9 sin(t) + 129.9 cos(t) + 9.0 sin(2t) + 9.5 cos(2t) + 141.7 sin(3t)
Ostap Okhrin 44 of 52
Andrews curves (Bank data)
−0.
250
0.25
0.5
0 1 2 3 4 5 6
t
f96-
f105
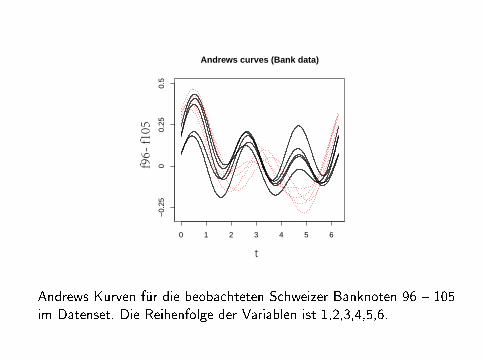
Andrews Kurven für die beobachteten Schweizer Banknoten 96 � 105im Datenset. Die Reihenfolge der Variablen ist 1,2,3,4,5,6.
Angewandte Multivariate Statistik Comparison of Batches Andrews Kurven
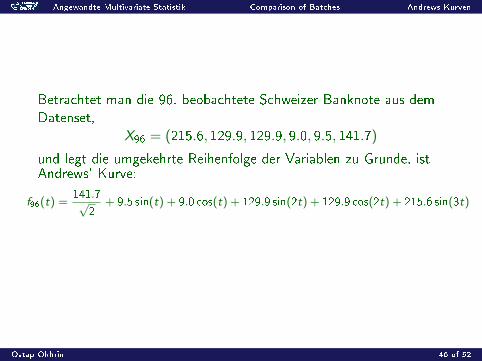
Betrachtet man die 96. beobachtete Schweizer Banknote aus demDatenset,
X96 = (215.6, 129.9, 129.9, 9.0, 9.5, 141.7)
und legt die umgekehrte Reihenfolge der Variablen zu Grunde, istAndrews' Kurve:
f96(t) =141.7√
2+ 9.5 sin(t) + 9.0 cos(t) + 129.9 sin(2t) + 129.9 cos(2t) + 215.6 sin(3t)
Ostap Okhrin 46 of 52
Andrews curves (Bank data)
−0.
250
0.25
0.5
0 1 2 3 4 5 6
t
f96-
f105
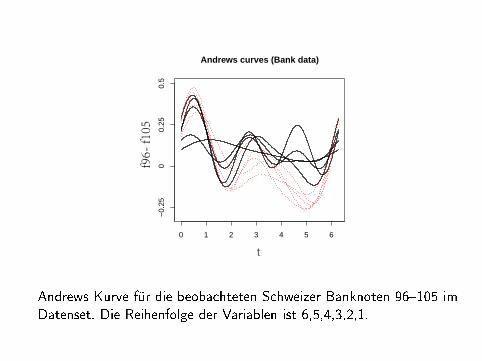
Andrews Kurve für die beobachteten Schweizer Banknoten 96�105 imDatenset. Die Reihenfolge der Variablen ist 6,5,4,3,2,1.

Angewandte Multivariate Statistik Comparison of Batches Andrews Kurven
Zusammenfassung: Andrews Kurve
� Ausreiÿer erscheinen als einzelne Andrews Kurven, die sichdeutlich von den anderen Kurven abheben.
� Eine Untergruppe besteht charakteristisch aus einem Set vonähnlichen Kurven.
� Die Reihenfolge der Variablen spielt eine wichtige Rolle bei derInterpretation der Kurven.
� Die Reihenfolge der Variablen kann mit Hilfe der PrincipalComponent Analyse optimiert werden.
� Bei mehr als 20 Beobachtungen erhält man ein sogenanntes�signal-to-ink-ratio�, d.h. die Kurven lassen sich schlechtinterpretieren.
Ostap Okhrin 48 of 52

Angewandte Multivariate Statistik Comparison of Batches Koordinatensysteme mit parallelen Achsen
Koordinatensysteme mit parallelen Achsen
� Basieren nicht auf das orthogonale Koordinatensystem.
� Erlaubt die Darstellung von mehr als vier Dimensionen.
Idee
Anstatt Beobachtungen in ein orthogonales Koordinatensystem zuplotten, werden deren Koordinaten in ein System mit parallelen Achsengezeichnet.Diese Darstellungsmethode ist jedoch emp�ndlich gegenüber derReihenfolge der Variablen.
Ostap Okhrin 49 of 52
Parallel coordinates plot (Bank data)
V1 V2 V3 V4 V5 V6
00.
20.
40.
60.
81
t
f96-
f105
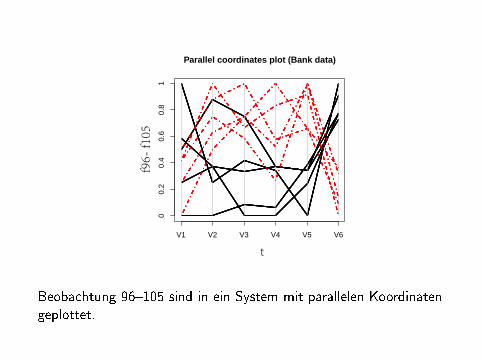
Beobachtung 96�105 sind in ein System mit parallelen Koordinatengeplottet.
Parallel coordinates plot (Bank data)
V1 V2 V3 V4 V5 V6
00.
20.
40.
60.
81
t
f1-f200
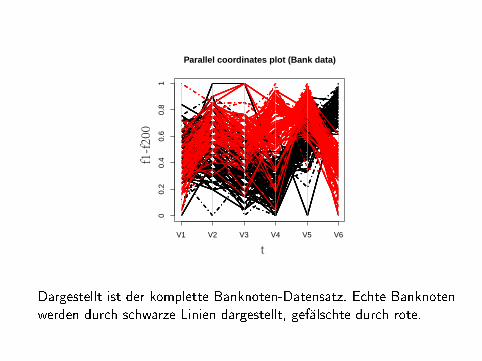
Dargestellt ist der komplette Banknoten-Datensatz. Echte Banknotenwerden durch schwarze Linien dargestellt, gefälschte durch rote.

Angewandte Multivariate Statistik Comparison of Batches Koordinatensysteme mit parallelen Achsen
Zusammenfassung: Koordinatensystememit parallen Achsen
� Werden Variablen in einem System mit parallelen Koordinatengeplottet, können im Gegensatz zu kartesischenKoordinatensystemen, mehr als vier Dimensionen dargestelltwerden.
� Ausreiÿer entsprechen Polygonenkurven, die sich deutlich vonanderen Kurven abheben.
� Die Reihenfolge der Variablen muss bei der Bestimmung vonUntergruppen beachtet werden.
� Untergruppen können durch unterschiedliche Farben kenntlichgemacht werden.
Ostap Okhrin 52 of 52