
Fakultät Technik und Informatik Department Informatik
Faculty of Engineering and Computer Science Department of Computer Science
Stefan Zinke
Einsatz ausgewählter Data Mining-Verfahren zur Optimierung des After Sales Marketing
Bachelorarbeit

Stefan Zinke
Einsatz ausgewählter Data Mining-Verfahren zur Optimierung des After Sales Marketing
Bachelorarbeit eingereicht im Rahmen der Bachelorprüfung im Studiengang Wirtschaftsinformatik am Department Informatik der Fakultät Technik und Informatik der Hochschule für Angewandte Wissenschaften Hamburg Betreuender Prüfer: Prof. Dr. Klaus-Peter Schoeneberg Zweitgutachter: Prof. Dr. Ulrike Steffens Abgegeben am 23.08.2016

Stefan Zinke Thema der Bachelorarbeit
Einsatz ausgewählter Data Mining-Verfahren zur Optimierung des After Sales Marketing Stichworte
Data Mining, After Sales Marketing, Ensemble-Methoden, Datentransformation, Ungleiche Klassenverteilung, Prädiktorenselektion, KNIME
Kurzzusammenfassung
In der vorliegenden Arbeit besteht die Aufgabenstellung darin, Kunden eines Online-Shops anhand der vorhandenen Merkmale ihrer Erstbestellung zu klassifizieren. Es wird nur den Kunden, die ohne Incentivierung keinen Folgekauf tätigen, ein Gutschein in Höhe von 5 Euro zugesendet. Das betriebswirtschaftliche Ziel liegt in einer Maximierung des Umsatzes in Bezug auf diese After Sales Marketing-Maßnahme. Die seitens eines Online-Medienhändlers zur Verfügung gestellten Datensätze weisen fehlende und inkonsistente Werte auf und sind hinsichtlich des Klassifikationsmerkmals sehr ungleich verteilt. Somit wird durch Datenvorverarbeitungsprozesse die Datenqualität erhöht und eine gleichmäßigere Verteilung der Klassen hergestellt. Die angewendeten Verfahren werden darüber hinaus durch eine Selektion relevanter Prädiktoren und Parameteranalysen optimiert. Die besten Ergebnisse werden mit dem Gradient Boosted Trees-Verfahren erzielt, das zu den Ensemble-Methoden gehört.
Stefan Zinke Title of the paper
Application of selected data mining techniques for the optimization of After Sales Marketing
Keywords
Data Mining, After Sales Marketing, Ensemble Methods, Data Transformation, Unbalanced Data Sets, Feature Elimination, KNIME
Abstract
This work tries to classify customers of an online-shop based on the existing features of their first order. A coupon of 5 euros is send only to those customers, who do not order again without further incentive. The business objective is to maximize the revenue relating to this after-sales campaign. The records made available by an online media retailer contain missing and inconsistent values and are distributed very unevenly with regard to the classification feature. Thus the data quality is increased and a more even distribution of classes is achieved by applying data preprocessing steps. Additionally, the used procedures are optimized by a selection of relevant predictors and a parameter analysis. The best results are obtained with the Gradient Boosted Trees method, which belongs to the ensemble methods.

Inhaltsverzeichnis
Abbildungsverzeichnis ......................................................... vi
Tabellenverzeichnis ........................................................... viii
1 Einleitung ...................................................................... 10
1.1 Themenbeschreibung .................................................................................. 10
1.2 Ziel der Arbeit .............................................................................................. 11
1.3 Struktur der Arbeit ...................................................................................... 12
1.4 Bezugsrahmen ............................................................................................. 13
2 Grundlagen ................................................................... 14
2.1 Data Mining ................................................................................................. 15
2.2 Data Mining-Prozess .................................................................................... 16
2.2.1 Knowledge Discovery in Databases (KDD) ......................................................16
2.2.2 Cross-Industry Standard Process for Data-Mining (CRISP-DM) ......................17
2.3 Data Mining – Lernarten ............................................................................. 19
2.3.1 Unüberwachtes Lernen ...................................................................................19
2.3.2 Überwachtes Lernen .......................................................................................21
2.4 Datenvorverarbeitung ................................................................................. 23
2.4.1 Behandlung fehlender und inkonsistenter Werte ..........................................24
2.4.2 Datentransformation ......................................................................................27
2.4.3 Selektion der Prädiktoren ...............................................................................28
2.5 Klassifikationsverfahren .............................................................................. 32
2.5.1 Entscheidungsbäume ......................................................................................32

2.5.2 Künstliche Neuronale Netze ...........................................................................35
2.5.3 Naiver Bayes Klassifikator ...............................................................................40
2.5.4 Support Vector Machine .................................................................................42
2.5.5 k-Nächster-Nachbar-Klassifikator ...................................................................45
2.5.6 Logistische Regression ....................................................................................46
2.5.7 Ensemble-Methoden ......................................................................................47
2.6 Modellbewertung ........................................................................................ 50
2.6.1 Gütemaße .......................................................................................................51
2.6.2 Fehlerkosten ...................................................................................................55
2.6.3 Trainings- und Testmenge ...............................................................................56
2.7 KNIME .......................................................................................................... 60
2.8 After Sales Marketing .................................................................................. 63
3 Empirischer Teil ............................................................. 66
3.1 Geschäftsmodell und Datenerhebung ........................................................ 66
3.2 Datenvorverarbeitung ................................................................................. 70
3.2.1 Fehlende und irrelevante Werte .....................................................................70
3.2.2 Inkonsistente Werte........................................................................................74
3.2.3 Datentransformation ......................................................................................80
3.3 Modellierung und Evaluation ...................................................................... 84
3.3.1 Bestimmung der Trainingsmenge ...................................................................85
3.3.2 Selektion der Prädiktoren ...............................................................................91
3.3.3 Parameteroptimierung ...................................................................................97
3.4 Ergebnisse .................................................................................................. 100
4 Abschlussbetrachtung ................................................. 102
4.1 Fazit ........................................................................................................... 103
4.2 Ausblick ...................................................................................................... 104
Literaturverzeichnis .......................................................... 106

Abbildungsverzeichnis
Abbildung 1 - Bezugsrahmen ...................................................................................................... 14 Abbildung 2 - KDD-Prozess .......................................................................................................... 16 Abbildung 3 - CRISP-DM .............................................................................................................. 17 Abbildung 4 - Übersicht der Lernarten ....................................................................................... 19 Abbildung 5 - Scatterplots mit unterschiedlichen Korrelationskoeffizienten............................. 29 Abbildung 6 - Hauptkomponentenanalyse mit den Hauptkomponenten v1 und v2 ................. 31 Abbildung 7 - Entscheidungsbaum zur Ermittlung eines Zahlungsausfalls ................................. 35 Abbildung 8 - Aufbau eines mehrschichtigen Perzeptrons ......................................................... 36 Abbildung 9 - Vereinfachter Aufbau eines Neurons ................................................................... 37 Abbildung 10 - Sprungfunktion ................................................................................................... 38 Abbildung 11 - Tangens hyperbolicus als Aktivierungsfunktion ................................................. 38 Abbildung 12 - Logistische Funktion als Aktivierungsfunktion ................................................... 39 Abbildung 13 - Support Vector Machine mit linear separierbaren Daten .................................. 42 Abbildung 14 - Klassen mit nichtlinearen Klassengrenzen ......................................................... 44 Abbildung 15 - k-Nächster-Nachbar-Klassifikator ....................................................................... 45 Abbildung 16 - Konfusionsmatrix ................................................................................................ 52 Abbildung 17 - ROC-Diagramm ................................................................................................... 54 Abbildung 18 - Kostenmatrix ...................................................................................................... 56 Abbildung 19 - Ausschnitt aus einem KNIME Workflow ............................................................. 61 Abbildung 20 - Darstellung eines Metanodes ............................................................................. 62 Abbildung 21 - Ausschnitt aus dem Workflows des Metanodes aus Abb. 20 ............................ 63 Abbildung 22 - Customer Lifetime Value .................................................................................... 65 Abbildung 23 - Auszug aus den advertisingdatacode-Werten der Trainingsmenge .................. 73 Abbildung 24 - Java Snippet zur Umwandlung der advertisingdatacode-Werte ....................... 73 Abbildung 25 - Übersicht der inkonsistenten deliverydatepromised Werte der Trainingsmenge
............................................................................................................................................ 76 Abbildung 26 - Anzahl unterschiedlicher Werte des Merkmals deliverydatereal ...................... 77 Abbildung 27 - Untersuchung stornierter Artikel ....................................................................... 78 Abbildung 28 - Statistische Auswertung zeitlicher Abstände ..................................................... 79 Abbildung 29 - Korrelation zwischen den Merkmalen date und deliverydatereal ..................... 79 Abbildung 30 - Korrelation zwischen den Merkmalen deliverydatepromised und deliverydatereal
............................................................................................................................................ 79 Abbildung 31 - Ersetzen der inkorrekten deliverydatereal-Werte ............................................. 80

Abbildung 32 - Java Snippet zur Erstellung der Kostenmatrix .................................................... 84 Abbildung 33 - Konfusionsmatrix des Random Forest-Modells bei unveränderter Trainingsmenge
............................................................................................................................................ 88 Abbildung 34 - Under-Sampling zur Reduktion der ungleichen Verteilung der Klassen ............ 89 Abbildung 35 - Korrelationsmatrix der Prädiktoren ................................................................... 92 Abbildung 36 - Backward Feature Elimination ........................................................................... 95 Abbildung 37 - Ausschnitt der Ergebnisse der Rückwärtsselektion der Trainingsmenge mit 1,5:1
Klassenverteilung ................................................................................................................ 96 Abbildung 38 - Backward Feature Elimination Filter mit manueller Selektion ........................... 97 Abbildung 39 - Schleife zur Parameteroptimierung ................................................................... 98 Abbildung 40 - Parameterselektion MultiLayerPerceptron ........................................................ 98 Abbildung 41 - Zuweisen der dynamischen Variablen beim MultiLayerPerceptron .................. 99 Abbildung 42 - Ausschnitt der Ergebnisse der Parameteroptimierung beim MultiLayerPerceptron
............................................................................................................................................ 99 Abbildung 43 - Umsatzsteigerungen durch Modelloptimierung (Beträge in Euro) .................. 101
Tabellenverzeichnis
Tabelle 1 - Erläuterung der Spaltenattribute ............................................................................. 68 Tabelle 2 - Verteilung des Klassifikationsmerkmals target90 ..................................................... 68 Tabelle 3 - Fehlende Werte der Trainingsmenge ........................................................................ 71 Tabelle 4 - Fehlende Werte der Testmenge ............................................................................... 71 Tabelle 5 - Inkonsistente Werte der Trainingsmenge ................................................................. 75 Tabelle 6 - Inkonsistente Werte der Testmenge......................................................................... 75 Tabelle 7 - Standardparameter der Modelle .............................................................................. 86 Tabelle 8 - Erzielte Umsätze auf den Testdaten mit vollständiger Trainingsmenge ................... 87 Tabelle 9 - Erzielte Umsätze auf den Testdaten nach Anwendung von Equal Size Sampling..... 87 Tabelle 10 - Erzielte Umsätze mit einem Verhältnis von 1,5:1 (Klasse 0: Klasse 1) .................... 90 Tabelle 11 - Umsätze mit unterschiedlichen correlation threshold Schwellenwerten ............... 94 Tabelle 12 - Maximaler Umsatz der Verfahren nach der Parameteroptimierung .................... 100 Tabelle 13 - Prozentuale Umsatzsteigerung bezogen auf den Basisumsatz ............................. 102


1 Einleitung
Im Folgenden wird ein Überblick über das Thema, die Problemstellungen und die
Struktur der Arbeit gegeben.
1.1 Themenbeschreibung
Die vorliegende Arbeit befasst sich mit der Problemstellung, Kunden eines Online-Shops
in Bezug auf After Sales Marketing-Maßnahmen zu klassifizieren. Konkret geht es darum,
die Kunden herauszufiltern, die ohne zusätzlichen Anreiz seitens des Online-Händlers
nach ihrer Erstbestellung keine weitere Folgebestellung aufgeben. Diese Klassifikation
ist für das After Sales Marketing der Händler sehr wichtig, da ein Wechsel der Kunden
zu anderen Anbietern verhindert wird und zusätzliche Bestellungen generiert werden.
Darüber hinaus sind im Regelfall die Kosten für Kundenbindungs- und
Rückgewinnungsmaßnahmen deutlich geringer als die Kosten für eine
Neukundenakquise (vgl. Günter, Neu 2015, S. 28). Die Fragestellung und die
Datenquellen, die im Rahmen der Arbeit untersucht werden, ergeben sich aus einer
Aufgabenstellung des Data Mining Cups von 2010 (vgl. DMC 2010). Dort hat ein
Medienhändler, der neben Büchern und CDs auch eBooks, Hörbücher und Downloads
anbietet, Kundendaten aus seinem Shop zur Verfügung gestellt, aus denen auf einen
möglichen Folgekauf geschlossen wird. In der Aufgabenstellung wird davon

Einleitung 11
ausgegangen, dass ein Folgekauf innerhalb einer Frist von 90 Tagen nach der
Erstbestellung erfolgt.
Eine korrekte Klassifikation ermöglicht es, genau denjenigen Kunden einen Gutschein in
Höhe von 5 Euro zuzusenden, die ohne Incentivierung keine weitere Bestellung
aufgeben. Erfahrungswerten zufolge wird davon ausgegangen, dass eine
Folgebestellung, die durch Zusenden des Gutscheins erreicht wird, in 10% der Fälle
erfolgt. Der durchschnittliche Warenwert einer derart erzielten Bestellung soll dabei 20
Euro betragen. Somit ergibt sich bei einem korrekt zugesendeten Gutschein eine
Umsatzsteigerung von 1,50 Euro.
In dem Fall, in dem einem Kunden ein Gutschein zugeschickt wird, der auch ohne diesen
Gutschein eine weitere Bestellung aufgibt, schlägt gemäß der Aufgabenstellung eine
Umsatzeinbuße von 5 Euro zu Buche. Eine weiterführende Umsatzanalyse wird in Kapitel
2.5.2 mit Hilfe einer Kostenmatrix vorgenommen.
1.2 Ziel der Arbeit
Ziel dieser Arbeit ist es, die After Sales Marketing-Maßnahme des Online-
Medienhändlers durch den Einsatz ausgewählter Data Mining-Verfahren effektiver und
profitabler zu gestalten. Es werden unterschiedliche Modelle entwickelt, die
anschließend anhand der durch sie generierten Umsatzsteigerung verglichen werden.
Die Modelle mit den besten Ergebnissen werden im Detail optimiert, um einen
zusätzlichen positiven Effekt auf die Modellgüte zu erreichen. Durch diese
Vorgehensweise wird der Nutzen von Data Mining in Bezug auf erfolgreiche
Kundenbindungsmaßnahmen und damit den Unternehmenserfolg verdeutlicht.
Als Datenquellen liegen Tabellen mit Kundendaten vor, die zahlreiche Merkmale
bezüglich der Kundenbestellung betreffen. Vor der Anwendung der Data Mining-
Verfahren auf die Daten wird durch systematische Vorverarbeitungsprozesse eine hohe
Datenqualität sichergestellt. Die im Verlauf der Arbeit gebildeten Modelle werden
anhand von unterschiedlichen Trainingsmengen und Prädiktoren, sowie unter

Einleitung 12
Verwendung verschiedener Modell-Parameter getestet und optimiert. Eine
Herausforderung stellt dabei die Ungleichverteilung der Daten hinsichtlich des
Klassifikationsmerkmals dar. Es werden mehrere Methoden untersucht, um ein
ausgewogenes Klassenverhältnis herzustellen und somit eine aussagekräftige
Modellbildung zu erleichtern.
Das Klassifikationsmerkmal target90 bestimmt, ob seitens des Kunden ein Folgekauf
innerhalb von 90 Tagen erfolgt oder nicht.
Die vorliegenden Klassen für das Merkmal target90 sind:
Klasse 0: Kein Folgekäufer (Kunde tätigt keinen Folgekauf innerhalb von 90 Tagen, somit wird ein Gutschein zugesendet).
Klasse 1: Folgekäufer (Kunde tätigt einen Folgekauf innerhalb von 90 Tagen, somit wird kein Gutschein zugesendet).
Für diese Arbeit wird wie beschrieben als Erfolgskriterium der einzelnen Modelle die
Umsatzsteigerung betrachtet, die in Bezug auf die After Sales Marketing-Maßnahme
erreicht wird. In diesem Zusammenhang ist zu beachten, dass die Auswirkungen der
korrekt und inkorrekt klassifizierten Datenobjekte auf den Gesamtumsatz
unterschiedlich hoch sind und anhand einer Kostenmatrix berechnet werden. Wird ein
Kunde fälschlicherweise der Klasse 0 zugeordnet, bedeutet das eine Umsatzeinbuße von
5 Euro, während eine fehlerhafte Zuordnung in Klasse 1 eine Umsatzsteigerung um 1,50
Euro verhindert.
1.3 Struktur der Arbeit
Die Arbeit ist in einen Grundlagenteil und einen empirischen Teil gegliedert. Zu Beginn
wird auf die Grundlagen von Data Mining eingegangen und es werden die für die
vorliegende Arbeit relevanten Begrifflichkeiten und Prozesse erläutert. Es folgt eine
Darstellung der für den gesamten Data Mining-Prozess notwendigen theoretischen
Kenntnisse nach dem aktuellen Stand der Forschung.

Einleitung 13
Anschließend wird die verwendete Software, mit der die ausgewählten statistischen
Modelle erstellt und angewendet werden, in Grundzügen dargestellt. Im Folgenden wird
der Bezug zum After Sales Marketing hergestellt, wodurch der Wert von Data Mining-
Verfahren für den E-Commerce deutlich wird.
Darauf folgt der empirische Teil der Arbeit, wobei die einzelnen Schritte des Data
Mining-Prozesses in Bezug auf die Aufgabenstellung durchlaufen werden um das Modell
zu ermitteln, das die höchste Umsatzsteigerung erzielt.
Abschließend folgt ein Fazit mit Bezug auf die angewendeten Methoden, sowie die
erreichten Ergebnisse und es wird ein Ausblick auf weitere Untersuchungsmöglichkeiten
gegeben.
1.4 Bezugsrahmen
Der Bezugsrahmen stellt die Zusammenhänge der einzelnen Kapitel grafisch dar. Es wird
veranschaulicht, welche theoretischen Grundlagen für die jeweiligen Punkte des
empirischen Teils relevant sind. Somit wird ein Überblick über die gesamte Struktur der
Arbeit ermöglicht (siehe Abb. 1).

Grundlagen 14
Abbildung 1 - Bezugsrahmen
2 Grundlagen
Im Folgenden wird zunächst der Begriff Data Mining vorgestellt, sowie eine Abgrenzung
zum Begriff Knowledge Discovery in Databases vorgenommen. Anschließend werden
der Data Mining-Prozess, die Lernarten, die Datenvorverarbeitung und die
theoretischen Grundlagen der wichtigsten Klassifikationsverfahren erläutert.

Grundlagen 15
Darüber hinaus werden die relevanten Modellbewertungskriterien erläutert, um die
effektivsten Data Mining-Verfahren für die vorliegende Aufgabenstellung zu ermitteln.
Des Weiteren wird die für diese Arbeit verwendete Data Mining-Software vorgestellt.
Es folgt eine Darstellung des Begriffs After Sales Marketing, sowie ein Überblick über die
Vorteile, die sich aus einer Optimierung in diesem Bereich ergebt.
2.1 Data Mining
Data Mining kann mit Datenmustererkennung übersetzt werden (vgl. Bissantz,
Hagedorn 1993, S. 481). Es gibt unterschiedliche Definitionen, die sich in Feinheiten
unterscheiden (vgl. Bankhofer, Vogel 2008, S. 253; Eibe, Hall, Witten 2011, S. 4; Runkler
2010, S. 2). Für diese Arbeit wird die vorliegende Definition verwendet:
„Data Mining ist das semi-automatische Aufdecken von Mustern mittels Datenanalyse-
Verfahren in meist sehr großen und hochdimensionalen Datenbeständen“ (Lenz, Müller
2013, S. 75). Data Mining hat also das Ziel neues Wissen und neue Querverbindungen
aus den vorhandenen Daten zu extrahieren (vgl. Runkler 2010, S. 2).
Ein verwandter Begriff zum Data Mining ist Knowledge Discovery in Databases (KDD).
Die grundlegende Definition von KDD ist: „Wissensentdeckung in Datenbanken ist der
nichttriviale Prozess der Identifikation gültiger, neuer, potentiell nützlicher und
schlussendlich verständlicher Muster in (großen) Datenbeständen“ (Fayyad, Piatetsky-
Shapiro, Smyth 1996, S. 40).
Es gibt Autoren, die diesen Begriff synonym zum Data Mining verwenden, andere sehen
Data Mining als Kernprozess des KDD im Rahmen der Wissensidentifikation (vgl. Sharafi
2013, S. 51).

Grundlagen 16
2.2 Data Mining-Prozess
Im Folgenden werden die beiden gängigsten Data Mining-Prozesse beschrieben (vgl.
Elder, Miner, Nisbet 2009, S. 35). Dabei handelt es sich einerseits um den bereits
erwähnten Prozess Knowledge Discovery in Databases und zum anderen um den Cross-
Industry Standard Process for Data-Mining (CRISP-DM).
2.2.1 Knowledge Discovery in Databases (KDD)
Der KDD-Prozess ist nicht linear, sondern iterativ und interaktiv im gesamten Prozess
der Wissensentdeckung zu verstehen, so dass bei Bedarf zu einem vorhergehenden
Schritt zurückgegehrt wird (vgl. Bankhofer, Vogel 2008, S. 254).
Abbildung 2 - KDD-Prozess Quelle: Lenz, Müller 2013, S. 77.
Es folgt eine Erläuterung der Prozessabläufe, die in Abb. 2 veranschaulicht sind:
1. Selektion: Es werden die Daten ausgewählt, die für die Aufgabenstellung relevant sind.
2. Vorverarbeitung: Die Rohdaten werden vorverarbeitet, d.h. Fehler werden erkannt und behandelt, Dubletten identifiziert und fehlende Werte ermittelt (vgl. Runkler 2010, S. 21).
3. Transformation: Die Daten werden bei Bedarf in einen für die Analyse geeigneteren Datentyp umgewandelt.

Grundlagen 17
4. Data Mining: Die Daten werden mit Hilfe von Data Mining-Methoden analysiert um Muster und Beziehungen innerhalb der Daten zu entdecken, sowie weiterführendes Wissen in Bezug auf den Untersuchungsgegenstand zu ermitteln (vgl. Bankhofer 2008, S. 254).
5. Interpretation und Evaluation: Es findet eine Interpretation der gefundenen Muster und des angewendeten Modells statt. Die Muster werden dabei in der Regel für die Entscheidungsfindung visuell aufbereitet. Das Modell wird hinsichtlich der Einsetzbarkeit und der erarbeiteten Ergebnisse evaluiert (vgl. Lenz, Müller 2013, S.76).
2.2.2 Cross-Industry Standard Process for Data-Mining (CRISP-DM)
CRISP-DM stellt einen industrie- und softwareunabhängigen Standardprozess für das
Data Mining dar, der 1996 von einem Zusammenschluss mehrerer Unternehmen
entwickelt wurde (vgl. Chapman, Clinton, Kerber 1999, S. 1).
Abbildung 3 - CRISP-DM Quelle: Chapman 1999, S. 10.

Grundlagen 18
Dieser Prozess wird in folgende sechs Phasen unterteilt (siehe Abb. 3):
1. Geschäftsmodell verstehen: Die Geschäftsziele werden erfasst und es erfolgt eine Festlegung der Data Mining-Aufgabe, der Erfolgskriterien und eines Projektplans. Betriebswirtschaftliche Betrachtungen stehen bei der Zielsetzung im Vordergrund.
2. Daten verstehen: Die Datenquellen werden bestimmt und bezüglich der Datenqualität untersucht. Es werden erste Zusammenhänge der Daten über visuelle und statistische Aufbereitungen erkannt.
3. Daten aufbereiten: Diese Phase umfasst alle Schritte, die nötig sind um die Rohdaten in einen Datensatz zu überführen, auf den die Data Mining-Methoden sinnvoll angewendet werden Es erfolgt eine Bereinigung der Daten, in der Ausreißer, fehlende Werte und fehlerhafte Daten behandelt werden. Weiterhin findet eventuell eine Konvertierung der Daten statt und es werden für die Untersuchung irrelevante oder stark voneinander abhängige Daten herausgefiltert.
4. Modellierung: In dieser Phase erfolgt die Auswahl der Data Mining-Verfahren, der passenden Algorithmen und der dazugehörigen Parameter. Das Ergebnis resultiert in einem Modell zur Datenanalyse. In dieser Phase kommt es häufig vor, dass ein Rücksprung in eine vorhergehende Phase erfolgt, beispielsweise wenn sich die Erfordernisse an die Datenaufbereitung ändern (vgl. Sharafi 2013, S. 67).
5. Evaluation: Das ausgewählte Data Mining-Verfahren wird angewendet und im Anschluss wird die Modellanpassungsgüte bestimmt (vgl. Lenz, Müller 2013, S. 78). Es wird geprüft, ob die Erfolgskriterien und wirtschaftlichen Ziele, die in der ersten Phase entwickelt wurden, mit dem Modell erreicht werden.
6. Einsatz: Nachdem das Modell zum Einsatz gekommen ist, werden die Ergebnisse und das Wissen präsentiert und nutzbar gemacht. Es wird festgelegt, wie das Modell im Unternehmensalltag verwendet wird und wie lange es gültig ist.
In der vorliegenden Arbeit wird nicht strikt nach einem der beiden aufgeführten Data
Mining-Prozesse vorgegangen. CRISP-DM orientiert sich stark an Data Mining-Verfahren
innerhalb eines Unternehmensumfeldes. Aspekte wie beispielsweise der Einsatz des
Modells im Unternehmensalltag sind innerhalb dieser Arbeit nicht abschließend zu
beurteilen. Der Online-Händler, der die Daten zur Verfügung stellt, ist nicht bekannt. Es
werden im Vorfeld der Arbeit auch keine exakten betriebswirtschaftlichen Vorgaben
und Erfolgskriterien als Geschäftsziel festgelegt, wie es häufig im Unternehmensumfeld
der Fall ist. Es wird versucht, den Umsatz des Online-Händlers unter Bezugnahme auf
die Kostenmatrix in Kapitel 2.5.2 zu maximieren. Zudem gehen in dieser Arbeit die
Modellierungs- und die Evaluationsphase ineinander über, da beispielsweise nach einer

Grundlagen 19
Parameteroptimierung eines Modells sofort die Auswirkungen der Änderungen auf den
Umsatz untersucht werden.
Der Data Mining-Prozess innerhalb dieser Arbeit orientiert sich somit am CRISP-DM,
weicht in Teilaspekten aber davon ab.
2.3 Data Mining – Lernarten
Grundsätzlich wird beim Data Mining das überwachte und das unüberwachte Lernen
unterschieden. Für jede dieser Lernarten gibt es spezifische Verfahrensarten. Eine
Übersicht über die relevanten Verfahrensarten ist in Abb. 4 dargestellt.
Abbildung 4 - Übersicht der Lernarten
2.3.1 Unüberwachtes Lernen
Beim unüberwachten Lernen sind die zu entdeckenden Muster nicht bekannt, es sind
weder Gruppierungen noch Klassifikationen vorgegeben. Die Lösungen, die durch
entsprechende Algorithmen entwickelt werden, werden folglich nicht mit vorliegenden

Grundlagen 20
Lösungen abgeglichen (vgl. Cleve, Lämmel 2014, S. 55). Beispiele für das unüberwachte
Lernen sind die Cluster-Analyse und die Assoziationsanalyse, die im Folgenden kurz
dargestellt werden.
Cluster-Analyse
Die Cluster-Analyse hat das Ziel, gleichartige Objekte anhand von
Ähnlichkeitsmerkmalen in Gruppen zu unterteilen. Innerhalb der einzelnen Cluster wird
eine hohe Homogenität der Objekte angestrebt. Objekte verschiedener Cluster dagegen
sind möglichst heterogen (vgl. Baars, Kemper, Mehanna 2010, S. 116). Anwendung in
der Praxis findet die Clusteranalyse beispielsweise bei der Zeichenerkennung (engl.
optical character recognition) oder der Einteilung eines Kundenstammes in homogene
Kundengruppen. Die Quantifizierung der Ähnlichkeit der Objekte innerhalb der
einzelnen Cluster erfolgt über Distanz- oder Abstandsfunktionen. Zusätzlich wird eine
Qualitätsfunktion benötigt, die einen Vergleich von unterschiedlichen Clusterbildungen
zulässt.
Hinsichtlich der Qualitätsfunktionen gibt es zwei Herangehensweisen. Es existiert die
Methode, die Kompaktheit der einzelnen Cluster anhand der Summe der Abweichungen
der Objekte eines Clusters vom Clusterrepräsentanten zu messen. Die Summe der
Abweichungen über alle Cluster wird anschließend summiert. Je kleiner die Summe ist,
desto besser ist die Güte der Clusterbildung. Der zweite Ansatz untersucht, wie weit die
einzelnen Cluster voneinander entfernt liegen, wobei eine größere Entfernung
voneinander ein höheres Gütemaß zur Folge hat (vgl. Cleve, Lämmel 2014, S. 235).
Assoziationsanalyse
Die Assoziationsanalyse zielt darauf ab, Abhängigkeiten zwischen Objekten oder
Attributen zu ermitteln. Die bekannteste Anwendung in der Praxis ist die
Warenkorbanalyse. Dort wird analysiert, welche Artikel häufig zusammengekauft
werden. Im Anschluss an die Analyse werden dann Maßnahmen zur Verbesserung des

Grundlagen 21
Cross-Marketing oder der Artikelpositionierung ergriffen. Innerhalb der
Assoziationsanalyse werden Assoziationsregeln aufgestellt, die Korrelationen zwischen
gemeinsam auftretenden Dingen beschreiben. Die Assoziationsregeln werden in der
Form 𝐴 → 𝐵 (wenn Item-Menge 𝐴, dann Item-Menge 𝐵) dargestellt. Die wichtigsten
Kenngrößen der Assoziationsregeln sind Support und Konfidenz (vgl. Han, Kamber, Pei
2012, S. 246).
Sei 𝐷 eine Menge von Itemmengen. Eine Transaktion 𝑡 𝜖 𝐷 unterstützt eine Regel 𝐴 →
𝐵, wenn (𝐴 ∪ 𝐵) ⊆ 𝑡 gilt. Der Support einer Assoziationsregel berechnet sich dadurch,
dass die Anzahl der Transaktionen, die die Regel unterstützen, ins Verhältnis zur
Gesamtzahl aller Transaktionen gesetzt wird (vgl. Formel 1).
Support(𝐴 → 𝐵) =|{𝑡 𝜖 𝐷|(𝐴 ∪ 𝐵) ⊆ 𝑡}|
|𝐷|
(1)
Die Konfidenz beschreibt das Verhältnis zwischen den Transaktionen, die sowohl
Prämisse als auch Konklusion enthalten und den Transaktionen, die nur die Prämisse
enthalten (vgl. Formel 2).
Konfidenz(𝐴 → 𝐵) = |{𝑡 𝜖 𝐷|(𝐴 ∪ 𝐵) ⊆ 𝑡}|
|{𝑡 𝜖 𝐷|𝐴 ⊆ 𝑡}|=
Support (𝐴→𝐵)
Support 𝐴
(2)
Je nach Zielsetzung werden Schwellwerte für den Support und die Konfidenz festgelegt,
die nicht unterschritten werden dürfen. Dadurch werden die wichtigen
Assoziationsregeln herausgefiltert, die im Regelfall einen hohen Support, sowie eine
hohe Konfidenz haben.
2.3.2 Überwachtes Lernen
Beim überwachten Lernen wird das Verfahren anhand von Trainingsdaten hinsichtlich
der zu erledigenden Aufgabe trainiert. Die Klassenzugehörigkeit sowohl der Trainings-
als auch der Testdaten ist dabei bekannt (vgl. Krishna 2013, S. 37). Beim überwachten
Lernen sticht besonders die grundsätzliche Annahme heraus, dass die Beispieldaten
repräsentativ sind. Es wird davon ausgegangen, dass sich zukünftige Daten ähnlich

Grundlagen 22
verhalten wie die vorliegenden Beispieldaten (vgl. Cleve, Lämmel 2014, S. 55). Zu den
Verfahren des überwachten Lernens zählen beispielsweise die Klassifikation und die
Regression.
Regression
Die Regression stellt ein Vorhersagemodell für numerische kontinuierliche und
geordnete Werte dar. Dabei wird der Zusammenhang zwischen einer Zielgröße 𝑌 und
einer oder mehrerer Ausgangs-Variablen 𝑋(𝑖) untersucht. Ein Beispiel aus der Praxis ist
die Veränderung der Absatzmenge eines Produktes in Abhängigkeit vom Produktpreis
und dem zur Verfügung gestellten Werbeetat. Darüber hinaus wird durch die
Anwendung von Regressionsverfahren die Stärke des Zusammenhangs der
unabhängigen Variablen auf die Zielgröße quantifiziert. Es werden die folgenden
Verfahren unterschieden:
1. Lineare Regression: Bei der linearen Einfachregression wird untersucht, welchen Einfluss eine unabhängige Variable 𝑋 auf die von 𝑋 abhängige Variable 𝑌 ausübt. Das Ziel ist es vorherzusagen, was mit 𝑌 passiert, wenn sich 𝑋 verändert (vgl. Kronthaler 2014, S. 193). Die Regressionsgerade wird unter Anwendung der Methode der kleinsten Quadrate ermittelt, die den Abstand zwischen beobachteten Werten und der gesuchten Geraden minimiert. In der Praxis reicht eine Variable zur Vorhersage der abhängigen Zielgröße aber meist nicht aus.
2. Multiple Regression: Im Gegensatz zur linearen Regression wird bei der multiplen Regression der Einfluss mehrerer unabhängiger Variablen auf eine abhängige Variable untersucht.
3. Nichtlineare Regression: Die Funktionen der nichtlinearen Regression lassen sich nicht als lineare Funktionen in den Parametern beschreiben. Hier bestehen grundsätzlich unbeschränkte Möglichkeiten, den deterministischen Teil zu entwickeln. Meist werden die Funktionen der nichtlinearen Regression aus der Theorie abgeleitet und eventuell weiterentwickelt (vgl. Ruckstuhl 2008, S. 9).

Grundlagen 23
Klassifikation
Im Rahmen der Klassifikation werden Datenobjekte mit unbekannter
Klassenzugehörigkeit vorgegebenen Klassen zugeordnet. Es ist für die Klassifikation
essentiell, dass in den zu analysierenden Daten bereits Objekte vorhanden sind, für die
die zugehörige Klasse bereits bekannt ist. Anhand dieser Datenobjekte wird ein Modell
entwickelt, das eine allgemeingültige Klassifizierung ermöglicht (vgl. Spehling 2007, S.
26). Dieses Modell wird als Klassifikator bezeichnet. Zunächst werden die klassifizierten
Daten in Trainings- und Testdatenmenge aufgeteilt. Anhand der Trainingsdatenmenge
wird ein Modell entwickelt um neue unklassifizierte Datensätze anhand ihrer Attribute
möglichst genau den entsprechenden Klassen zuzuordnen. Die Modellgüte des
entwickelten Modells wird anhand der Testdaten überprüft. Es wird weiterhin zwischen
binärer (zwei Klassen) und mehrwertiger Klassifikation unterschieden.
In der Praxis werden Klassifikationsverfahren beispielsweise auf dem Versicherungs-
und Bankensektor angewendet, um Kunden nach Kreditwürdigkeit oder der
Wahrscheinlichkeit einer Vertragsstornierung einzuordnen.
2.4 Datenvorverarbeitung
Es ist notwendig, die Daten vor der Anwendung der Data Mining-Verfahren
aufzubereiten, damit die entwickelten Modelle qualitativ hochwertige und
aussagekräftige Ergebnisse erzielen. Es werden fehlende Werte und Inkonsistenzen
innerhalb der Daten behoben, sowie Transformationen der Daten durchgeführt. In
diesem Kapitel werden die für die vorliegende Arbeit relevanten Methoden vorgestellt.

Grundlagen 24
2.4.1 Behandlung fehlender und inkonsistenter Werte
Fehlende Werte haben unterschiedliche Ursachen. Häufige Gründe sind beispielsweise
(vgl. Refaat 2007, S. 171):
Fehlende Benutzereingaben, die aus Unwissenheit, falscher Benutzung oder einer Antwortverweigerung entstehen
Unvollständigkeit von Sekundärdaten
Software- oder Systemfehler
Fehlerhaftes Untersuchungsdesign
Übertragungsfehler der Daten Zunächst wird untersucht, welcher Ausfallmechanismus für die jeweilige Ausfallursache
greift. Es werden grundsätzlich drei Ausfallmechanismen unterschieden, die im
Folgenden dargestellt werden (vgl. Elder, Miner, Nisbet 2009, S. 60).
MAR (missing at random): Die Ausfallwahrscheinlichkeit ist unabhängig von der Ausprägung des Merkmals selbst.
OAR (observed at random): Die Ausfallwahrscheinlichkeit ist unabhängig von den Ausprägungen anderer Merkmale.
MCAR (missing completely at random): Die Ausfallwahrscheinlichkeit ist weder abhängig von der Ausprägung des Merkmals selbst, noch von den Ausprägungen anderer Merkmale.
Je nach Ausfallmechanismus werden anschließend passende Strategien zur Behandlung
der fehlenden Werte ermittelt. Drei gängige Basisstrategien werden im Folgenden
erläutert (vgl. Refaat 2007, S. 172; Elder, Miner, Nisbet 2009, S. 61).
Eliminierungsverfahren
Es bestehen im Rahmen der Eliminierungsverfahren zwei Möglichkeiten, die fehlenden
Werte zu behandeln:
Die Datenobjekte bei denen die fehlenden Werte auftreten, werden entfernt
Das gesamte Merkmal, bei dem fehlende Werte auftreten, wird entfernt
Ist die Anzahl der fehlenden Werte eines Merkmals gering, werden die Datenobjekte mit
den fehlenden Werten entfernt. Dieses Vorgehen ist geeignet, wenn für die
Modellbildung keine fehlenden Werte erlaubt sind und nach dem Entfernen der

Grundlagen 25
Datenobjekte eine ausreichende Menge an Test- und Trainingsdaten vorhanden ist (vgl.
Refaat 2007, S. 172). Es ist aber zu beachten, dass ein Informationsverlust entsteht, da
auch die übrigen Merkmale der Datenobjekte entfernt werden (vgl. Cleve, Lämmel 2014,
S. 202).
Tritt eine sehr hohe Anzahl (ab ca. 80 %) fehlender Werte bei einem Merkmal auf, ist es
möglich, das komplette Merkmal aus dem Datensatz zu entfernen (vgl. Steinlein 2004,
S. 47). Ein Vorteil der Eliminierungsverfahren ist, dass das statistische Modell nach dem
Entfernen der fehlenden Werte auf einer vollständigen Datenbasis operiert.
Ersetzungsverfahren
Im Rahmen des Ersetzungsverfahrens werden die fehlenden Werte von dem
Datenanalysten durch möglichst sinnvolle Werte ersetzt. Entweder ergeben sich die
Werte aus intuitiven oder heuristischen Gesichtspunkten oder anhand genereller
Eigenschaften der vorhandenen Werte des spezifischen Merkmals (vgl. Refaat 2007, S.
173). Es sind statistische Analysen durchzuführen, um die generellen Eigenschaften der
vorhandenen Werte zu untersuchen.
Häufig verwendete Werte des Ersetzungsverfahrens sind abhängig von der Skalierung
des Merkmals der Modus, der Median, das arithmetisches Mittel oder eine neue
Kategorie, die das Fehlen des Wertes ausdrückt. Es ist zu berücksichtigen, dass durch ein
Ersetzen der Werte eine mögliche Verzerrung der Daten entstehen kann, wenn die
ersetzten Werte inkorrekt sind (vgl. Han, Kamber, Pei 2012, S. 89).
Imputationsverfahren
Anstatt die fehlenden Werte manuell durch möglichst sinnvolle Werte zu ersetzen,
werden beim Imputationsverfahren die übrigen Merkmale als Eingabe für ein
statistisches Modell benutzt, um die fehlenden Werte zu prognostizieren. Es existieren
je nach Ausfallmechanismus unterschiedliche Algorithmen, die zur Vorhersage
verwendet werden. Es ist wichtig, dass das angewendete Imputationsverfahren zur

Grundlagen 26
Prognose der Werte die verteilungsbasierte Zufälligkeit berücksichtigt. Das bekannteste
Verfahren, das dieses Kriterium erfüllt ist die multiple Imputation. Bei der multiplen
Imputation werden die fehlenden Werte durch Schätzwerte ersetzt, die durch das
Anwenden verschiedener Prädiktoren ermittelt werden. Dieser Prozess wird mehrfach
wiederholt und es werden Standardfehler mit einbezogen (vgl. Böwing, Jurczok 2011, S.
5). Anschließend werden die ermittelten Schätzwerte zu einem Wert kombiniert.
Inkonsistente Werte
Die Gründe für inkonsistente, also widersprüchliche Werte decken sich zum Großteil mit
den Faktoren, die fehlende Werte verursachen. Hinzu kommen folgende Punkte (vgl.
Han, Kamber, Pei 2012, S. 91):
Absichtlich falsch eingetragene Werte durch Benutzer
Schlechtes Design von Benutzeroberflächen
Veraltete Daten
Fehler in Messgeräten, die zur Datenerhebung genutzt werden
Fehler bei der Datenintegration Es ist teilweise schwierig, Inkonsistenzen in den Daten aufzudecken, da auffällige Werte
unter anderem durch Ausreißer oder komplexe Zusammenhänge zwischen mehreren
Merkmalen verursacht werden (vgl. Refaat 2007, S. 96). Somit ist es wichtig, eine
statistische Auswertung der Daten durchzuführen und die Dateneigenschaften zu
untersuchen, um ein besseres Datenverständnis zu entwickeln (vgl. Han, Kamber, Pei
2012, S. 92). Inkonsistente Daten liegen zudem vor, wenn Integritätsbedingungen
verletzt werden (vgl. Cleve, Lämmel 2014, S. 205).
Es kommt vor, dass Inkonsistenzen erst nach durchgeführten Transformationsschritten
aufgedeckt werden, beispielsweise nach der Umwandlung eines Merkmals in einen
einheitlichen Datentyp. Die Behandlung inkonsistenter Daten erfolgt je nach der
Ursache und den Dateneigenschaften individuell.

Grundlagen 27
2.4.2 Datentransformation
Die Datentransformation hat das Ziel, die Daten in eine Form umzuwandeln und
zusammenzufassen, die den Data Mining-Verfahren eine effektive Arbeitsweise und ein
leichteres Erkennen von Mustern ermöglicht (vgl. Han, Kamber, Pei 2012, S. 112). Zudem
benötigen einige Verfahren (z.B. neuronale Netze) standardisierte Eingaben und
Datentypen, um sie sinnvoll weiterzuverarbeiten.
Darüber hinaus wird die Datenvorverarbeitung erleichtert, wenn Merkmale in
adäquaten Datentypen vorliegen, um Werte entsprechend auszulesen und zu
manipulieren. Beispielsweise ist es sinnvoll, wenn Datumsangaben nicht im String-
Format sondern im Date-Format vorliegen, um das Errechnen von Zeitspannen zu
erleichtern.
Normierung
Durch Normierung werden die Wertebereiche von Merkmalen mit Hilfe einer
Normierungsfunktion auf einen vordefinierten Wertebereich abgebildet und
vereinheitlicht. Durch diese Vorgehensweise wird eine Unabhängigkeit von
Maßeinheiten und eine bessere Vergleichbarkeit der Merkmale ermöglicht (vgl. Han,
Kamber, Pei 2012, S. 113). Gängige Wertebereiche für die Normierung sind die Intervalle
[−1,1] und [0,1]. Es existieren zahlreiche Normierungsfunktionen wie z.B. die Min-Max-
Normierung, die Z-Score-Normierung und die Skalen-Normierung (vgl. Cleve, Lämmel
2014, S. 212).
Konstruktion neuer Attribute
Die Konstruktion neuer, aussagekräftiger Attribute hilft dem Data Mining-Verfahren,
Gesetzmäßigkeiten und Muster leichter zu erkennen und dadurch die
Vorhersagegenauigkeit zu erhöhen (vgl. Freitas, Nievola, Otero 2003, S. 385). Neue
Attribute werden intuitiv oder anhand von Algorithmen konstruiert. Die Algorithmen

Grundlagen 28
werden in Hypothesen-getriebene und Daten-getriebene Verfahren unterteilt.
Hypothesen-getriebene Verfahren konstruieren neue Attribute anhand von zuvor
aufgestellten Regeln. Die Daten-getriebenen Verfahren erstellen neue Attribute, indem
sie Beziehungen zwischen den einzelnen Merkmalen aufdecken (vgl. Freitas, Nievola,
Otero 2003, S. 385).
2.4.3 Selektion der Prädiktoren
Vor der Anwendung eines Klassifikators auf die Trainingsdaten ist zu ermitteln, ob
irrelevante, redundante oder stark korrelierende Prädiktoren existieren. Diese werden
dann beim Training des Modells ignoriert. Ein Problem, das ansonsten bei großen
Datensätzen mit einer Vielzahl von Prädiktoren auftritt, ist der „Fluch der
Dimensionalität“. Dieser Ausdruck wurde erstmals von Richard Bellman im Jahre 1961
eingeführt (vgl. Elder, Miner, Nisbet 2009, S. 77). Durch eine hohe Dimensionalität
erhöht sich die Komplexität der Daten und die Bildung eines aussagekräftigen
statistischen Modells wird erschwert (vgl. Eibe, Hall, Witten 2011, S. 308). Die Selektion
der wichtigsten Prädiktoren in Bezug auf die Prognosegüte des Modells hat folgende
direkte positive Effekte auf das Erstellen eines Klassifikators (vgl. Elder, Miner, Nisbet
2009, S. 77):
1. Steigerung der Performanz des Algorithmus 2. Erhöhung der Datenqualität 3. Verbesserung des Aufdeckens von Beziehungen zwischen einzelnen Prädiktoren 4. Ergebnisse sind für den Anwender nachvollziehbarer 5. Im Regelfall Erhöhung der Prognosegüte des Modells
Es existieren zahlreiche Verfahren, mit deren Hilfe eine Selektion der relevanten
Prädiktoren vorgenommen wird. Eine Auswahl der häufig verwendeten und für die
vorliegende Arbeit relevanten Verfahren wird im Folgenden vorgestellt.

Grundlagen 29
Bravais-Pearsonscher Korrelationskoeffizient
Der Korrelationskoeffizient ist eine statistische Maßzahl, die das Maß des (positiven oder
negativen) linearen Zusammenhangs zwischen zwei Merkmalen darstellt. Seien (𝑥𝑖, 𝑦𝑖)
mit 𝑖 = 1, … , 𝑛 die 𝑛 beobachteten Wertepaare eines bivariaten Merkmals (𝑋, 𝑌), dann
ist der Korrelationskoeffizient definiert als (vgl. Backhaus, Erichson, Plinke 2016, S. 392;
Gabler 2016):
𝑟𝑥𝑦 =𝑠𝑥𝑦
𝑠𝑥𝑠𝑦
(3)
Dabei ist 𝑠𝑥𝑦 die empirische Kovarianz und 𝑠𝑥, 𝑠𝑦 sind die empirischen
Standartabweichungen der Merkmale 𝑋 und 𝑌. Damit ergibt sich für 𝑟𝑥𝑦:
𝑟𝑥𝑦 =∑ (𝑥𝑖 − �̅�)(𝑦𝑖 − �̅�) 𝑛
𝑖=1
√∑ (𝑥𝑖 − �̅�)2 𝑛𝑖=1 · √∑ (𝑦𝑖 − �̅�)2 𝑛
𝑖=1
(4)
In der Formel bezeichnen �̅� und �̅� die arithmetischen Mittel der einzelnen Werte der
Variablen. Der Korrelationskoeffizient nimmt ausschließlich Werte zwischen -1 und 1
ein. Bei einem Wert von 0 wird von linearer Unabhängigkeit gesprochen. Je näher der
Wert in der Nähe von +1 bzw. -1 liegt, desto stärker ist die lineare (gleichsinnige oder
gegensinnige) Abhängigkeit. In einem Koordinatensystem werden in diesem Fall Punkte
um eine unsichtbare Gerade herum beobachtet (siehe Abb. 5).
Abbildung 5 - Scatterplots mit unterschiedlichen Korrelationskoeffizienten Quelle: Bankhofer, Vogel 2008, S. 53.

Grundlagen 30
Die Korrelationskoeffizienten werden für jedes Merkmalspaar (unter Ausschluss des
Klassifikationsmerkmals) des zu untersuchenden Datensatzes bestimmt. Anschließend
werden über einen festzulegenden Schwellenwert die stark korrelierten Merkmale
herausgefiltert (vgl. Elder, Miner, Nisbet 2009, S. 70).
Hauptkomponentenanalyse
Die Hauptkomponentenanalyse (engl. Principal Component Analysis (PCA)) zielt darauf
ab, eine Vielzahl statistischer Variablen durch eine geringe Zahl von
Linearkombinationen ohne Informationsverlust zu ersetzen. Dies wird durch eine
orthogonale Transformation der ursprünglich vorhandenen Variablen in eine neue
Menge unkorrelierter Variablen erreicht, die als Hauptkomponenten fungieren (vgl.
Wang 1999, S. 32; Eibe, Hall, Witten 2011, S. 324). Die Hauptkomponenten beinhalten
den wesentlichen Teil der in den Originalvariablen enthaltenen Informationen und
Redundanz in Form von Korrelation wird zusammengefasst. Die erstellten
Hauptkomponenten sind dabei absteigend nach ihrem jeweiligen Informationsgehalt
geordnet.
Die Hauptkomponenten entstehen durch eine Hauptachsentransformation. Es entsteht
ein Vektorraum mit neuer Basis (vgl. Abb. 6).
Zur Ermittlung der neuen Basis wird jeweils die Richtung der größten Varianz des
Datensatzes ermittelt (vgl. Backhaus, Erichson, Plinke 2016, S. 412; Elder, Miner, Nisbet
2009, S. 71). Es entsteht demzufolge nach der Transformation eine orthogonale Matrix,
die aus den Eigenvektoren der Kovarianzmatrix gebildet wird. Es ist zu beachten, dass
die Hauptkomponentenanalyse nur für normalverteilte Daten optimal geeignet ist. Nach
der Anwendung dieses Verfahrens sind die Linearkombinationen statistisch unabhängig.
Bei nicht normalverteilten Datensätzen bestehen nach Anwendung der
Hauptkomponentenanalyse weiterhin (reduzierte) statistische Abhängigkeiten (vgl.
Eibe, Hall, Witten 2011, S. 325).
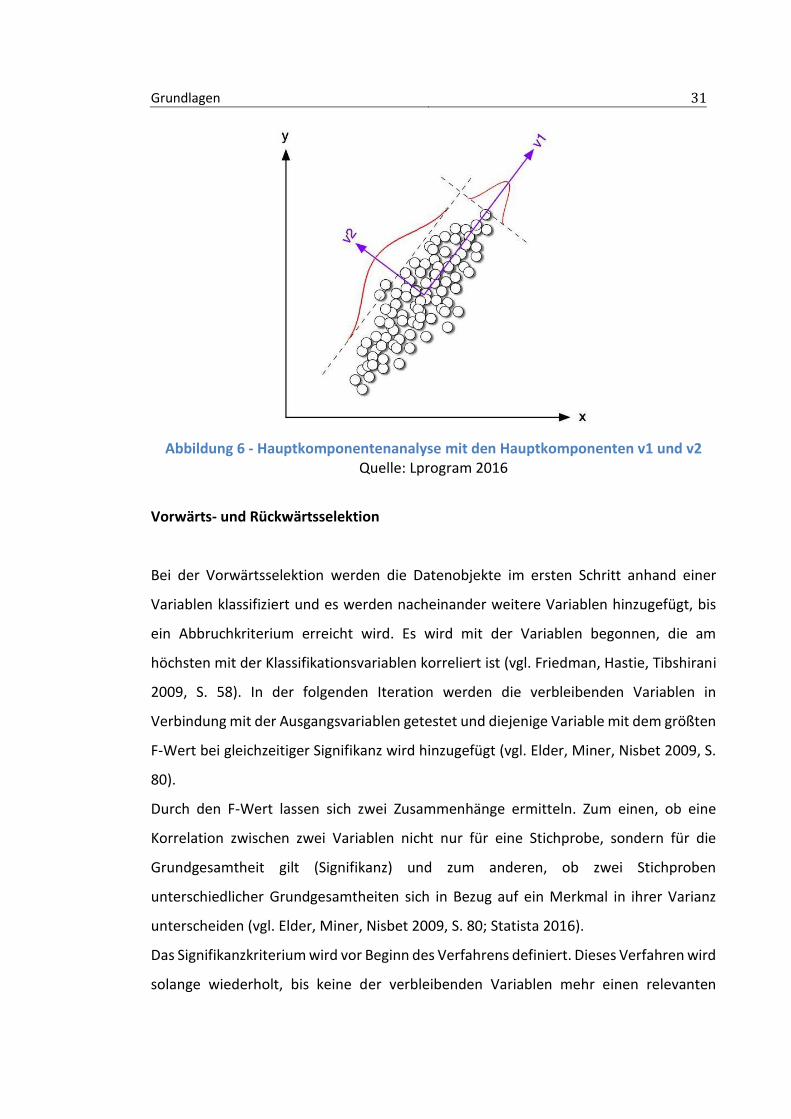
Grundlagen 31
Abbildung 6 - Hauptkomponentenanalyse mit den Hauptkomponenten v1 und v2 Quelle: Lprogram 2016
Vorwärts- und Rückwärtsselektion
Bei der Vorwärtsselektion werden die Datenobjekte im ersten Schritt anhand einer
Variablen klassifiziert und es werden nacheinander weitere Variablen hinzugefügt, bis
ein Abbruchkriterium erreicht wird. Es wird mit der Variablen begonnen, die am
höchsten mit der Klassifikationsvariablen korreliert ist (vgl. Friedman, Hastie, Tibshirani
2009, S. 58). In der folgenden Iteration werden die verbleibenden Variablen in
Verbindung mit der Ausgangsvariablen getestet und diejenige Variable mit dem größten
F-Wert bei gleichzeitiger Signifikanz wird hinzugefügt (vgl. Elder, Miner, Nisbet 2009, S.
80).
Durch den F-Wert lassen sich zwei Zusammenhänge ermitteln. Zum einen, ob eine
Korrelation zwischen zwei Variablen nicht nur für eine Stichprobe, sondern für die
Grundgesamtheit gilt (Signifikanz) und zum anderen, ob zwei Stichproben
unterschiedlicher Grundgesamtheiten sich in Bezug auf ein Merkmal in ihrer Varianz
unterscheiden (vgl. Elder, Miner, Nisbet 2009, S. 80; Statista 2016).
Das Signifikanzkriterium wird vor Beginn des Verfahrens definiert. Dieses Verfahren wird
solange wiederholt, bis keine der verbleibenden Variablen mehr einen relevanten

Grundlagen 32
Beitrag zur Verbesserung des Modells leistet oder die Teilmenge der Variablen eine
zuvor festgelegte Größe erreicht.
Die Rückwärtsselektion arbeitet in umgekehrter Richtung. Zu Beginn werden zur
Klassifikation alle vorhandenen unabhängigen Variablen verwendet. Im nächsten Schritt
wird die Variable mit dem geringsten und dabei nicht signifikanten F-Wert entfernt.
Dieser Schritt wird solange wiederholt, bis keine Variable mehr vorhanden ist, deren F-
Wert nicht signifikant ist (vgl. Friedman, Hastie, Tibshirani 2009, S. 59).
2.5 Klassifikationsverfahren
In der vorliegenden Arbeit geht es um die Klassifikation der Kunden eines Online-Shops
in die folgenden Klassen:
Klasse 0: Kein Folgekäufer (Kunde tätigt keinen Folgekauf innerhalb von 90 Tagen, somit wird ein Gutschein zugesendet).
Klasse 1: Folgekäufer (Kunde tätigt einen Folgekauf innerhalb von 90 Tagen, somit wird kein Gutschein zugesendet).
Es werden im Folgenden die für die Arbeit relevanten Klassifikationsverfahren erläutert.
2.5.1 Entscheidungsbäume
Entscheidungsbäume sind gerichtete Bäume mit Knoten und Kanten. Die Knoten
werden dabei weiter unterteilt in Wurzelknoten, innere Knoten und Blattknoten.
Sowohl der Wurzelknoten als auch die inneren Knoten beinhalten Splitting-Attribute.
Die von ihnen abgehenden Kanten sind mit den entsprechenden Werten der Splitting-
Attribute versehen. Die Blattknoten repräsentieren die Klassenzugehörigkeit der
Objekte. Die Klassifikationsregel dieses Modells wird durch den Pfad ausgehend vom
Wurzelknoten bis zu dem jeweiligen Blattknoten dargestellt. Somit traversieren die zu
klassifizierenden Objekte den Baum vom Wurzelknoten aus, indem die Splitting-

Grundlagen 33
Attribute sukzessiv ausgewertet werden. Dies geschieht solange, bis ein Blattknoten
erreicht wird und damit die Klassifizierung des Objektes vorliegt (vgl. Spehling 2007,
S.28). Der gesamte Entscheidungsbaum enthält somit die Menge aller
Entscheidungsregeln, die unter den festgelegten Kriterien möglich sind. Ein Beispiel für
einen Entscheidungsbaum zur Ermittlung eines Zahlungsausfalls ist in Abb. 7 dargestellt.
Dort wird eine Klassifikation anhand von Kriterien wie beispielsweise Beamtenstatus
und Einkommen vorgenommen.
Der Entscheidungsbaum wird anhand der Trainingsdaten konstruiert, deren
Klassenzugehörigkeit bereits bekannt ist. Die Konstruktion findet rekursiv ausgehend
vom Wurzelnoten statt. Es werden für jeden Knoten Attributwerte gesucht, die die
Objekte in möglichst homogene Partitionen aufteilen, so dass der Klassifikationsfehler
gering ist (vgl. Lenz, Müller 2013, S. 103).
Der rekursive Algorithmus endet, falls keine weiteren Attribute mehr vorliegen oder die
Klassenzugehörigkeit der Objekte eindeutig festgelegt wurde. Die Auswahl der
geeigneten Attribute für den jeweils nächsten Split hängt von der Homogenität der
erzeugten Untermengen, also der Gleichartigkeit der in den Untermengen enthaltenen
Objekte ab.
Die zwei am weitesten verbreiteten Verfahren für das Quantifizieren der Inhomogenität
sind die Entropie und der Gini-Index (vgl. Lenz, Müller 2013, S. 103; Cleve, Lämmel 2014,
S. 106).
Entropie
Die Entropie ist ein Maß für die Konzentration einer Objektmenge. Dabei ist die Entropie
einer Partition 𝑃 mit 𝑘 Klassen definiert als
Entropie(𝑃) = − ∑(𝑝𝑖 · log2 𝑝𝑖)
𝑘
𝑖 =1
(5)
Wobei 𝑝i die relative Häufigkeit der Klasse 𝑖 in der Partition 𝑃 darstellt. Je kleiner also
die Entropie, desto größer ist die Reinheit der Partition. Wichtig ist es, herauszufinden

Grundlagen 34
welcher Informationsgewinn durch einen Split erreicht wird, inwieweit also eine
Reduktion der Entropie durch die Attributauswahl erzielt wird.
Der Informationsgewinn des Attributes 𝐴 mit der Partition 𝑃1, 𝑃2, … , 𝑃𝑚 bezüglich der
Startpartition 𝑃 ist definiert als (vgl. Lenz, Müller 2013, S. 104):
InfGain(𝑃, 𝐴) = Entropie(𝑃) ∑ (|𝑃𝑖|
|𝑃|· Entropie (𝑃𝑖))
𝑚
𝑖 =1
(6)
Somit wird jeweils das Attribut für den nächsten Split ausgewählt, das den höchsten
Informationsgewinn zur Folge hat.
Gini-Index
Der Gini-Index basiert auf der Lorenzkurve. Er beschreibt die Abweichung von der
vollkommenen Gleichverteilung. Beträgt der Gini-Index 0 ist keine Unreinheit gegeben,
nimmt er den Wert 0,5 an, ist die Unreinheit sehr groß. Das Ziel ist somit, einen
möglichst kleinen Wert zu erreichen. Die Definition des Gini-Index einer Partition 𝑃
unter den oben getroffenen Definitionen lautet
Gini(𝑃) = 1 − ∑( 𝑝𝑖2)
𝑘
𝑖 =1
(7)
Relevant ist wieder die Bewertung der Aufteilung des Baumes durch das Split-Attribut.
Der Gini-Index des Split-Attributes in Bezug auf die Start-Partitionierung definiert sich
durch den gewichteten Durchschnitt der Gini-Indizes der m Teilmengen.
Gini(𝑃, 𝐴) = ∑ (|𝑃𝑖|
|𝑃|· Gini(𝑃𝑖))
𝑚
𝑖 =1
(8)
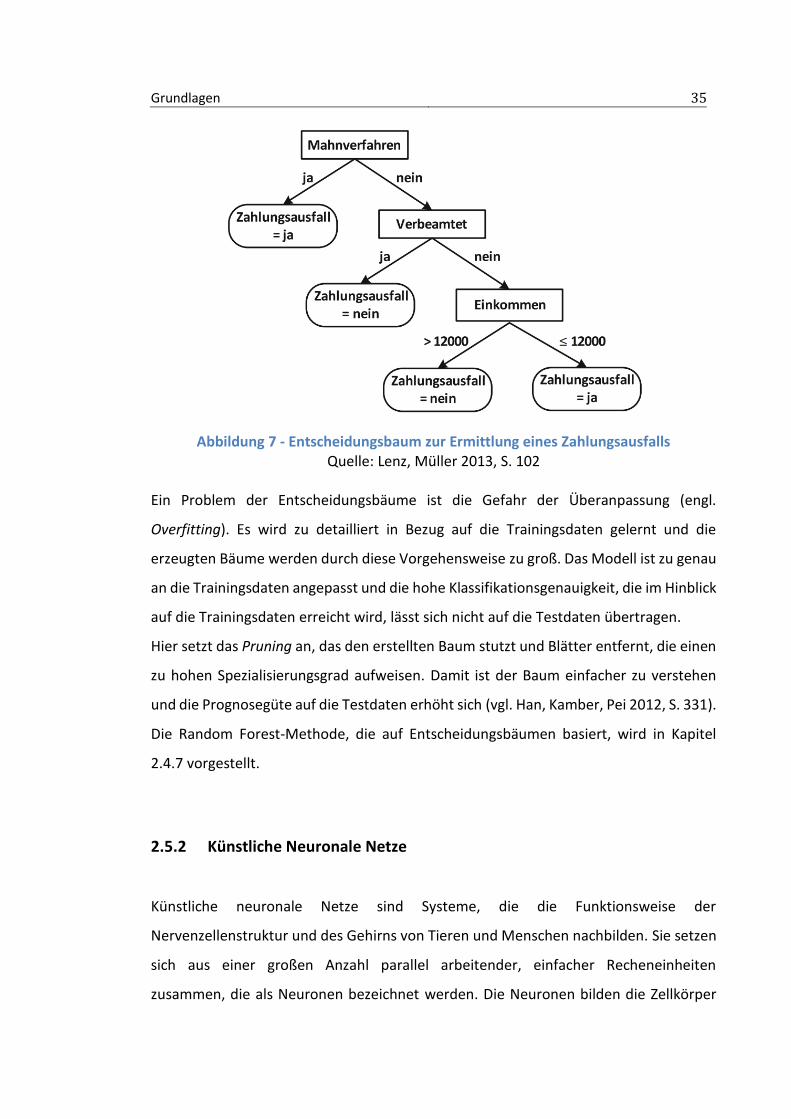
Grundlagen 35
Abbildung 7 - Entscheidungsbaum zur Ermittlung eines Zahlungsausfalls Quelle: Lenz, Müller 2013, S. 102
Ein Problem der Entscheidungsbäume ist die Gefahr der Überanpassung (engl.
Overfitting). Es wird zu detailliert in Bezug auf die Trainingsdaten gelernt und die
erzeugten Bäume werden durch diese Vorgehensweise zu groß. Das Modell ist zu genau
an die Trainingsdaten angepasst und die hohe Klassifikationsgenauigkeit, die im Hinblick
auf die Trainingsdaten erreicht wird, lässt sich nicht auf die Testdaten übertragen.
Hier setzt das Pruning an, das den erstellten Baum stutzt und Blätter entfernt, die einen
zu hohen Spezialisierungsgrad aufweisen. Damit ist der Baum einfacher zu verstehen
und die Prognosegüte auf die Testdaten erhöht sich (vgl. Han, Kamber, Pei 2012, S. 331).
Die Random Forest-Methode, die auf Entscheidungsbäumen basiert, wird in Kapitel
2.4.7 vorgestellt.
2.5.2 Künstliche Neuronale Netze
Künstliche neuronale Netze sind Systeme, die die Funktionsweise der
Nervenzellenstruktur und des Gehirns von Tieren und Menschen nachbilden. Sie setzen
sich aus einer großen Anzahl parallel arbeitender, einfacher Recheneinheiten
zusammen, die als Neuronen bezeichnet werden. Die Neuronen bilden die Zellkörper

Grundlagen 36
des Nervensystems nach. Zwischen den Neuronen findet über gerichtete Verbindungen
(in der Natur Axone) ein Informationsfluss statt. Grundsätzlich stellen neuronale Netze
eine Alternative für multivariate Analysemethoden dar, soweit großzahlige
Untersuchungen vorliegen. Dabei werden die Zusammenhänge zwischen den
Einflussgrößen selbständig durch den Lernprozess des Netzes ermittelt.
Neuronale Netze werden häufig unter Zuhilfenahme der Graphentheorie beschrieben,
die eine mathematische Definition der Struktur des Netzes ermöglicht (vgl. Borgelt,
Braune, Klawonn 2015, S. 33).
Für diese Arbeit wird folgende Definition übernommen: „Ein (künstliches) neuronales
Netz ist ein (gerichteter) Graph 𝐺 = (𝑈, 𝐶), dessen Knoten 𝑢 ∈ 𝑈 Neuronen (engl.
neurons, units) und dessen Kanten 𝑐 ∈ 𝐶 Verbindungen (engl. connections) heißen. Die
Menge der Knoten ist unterteilt in die Menge 𝑈𝑖𝑛 der Eingabeneuronen (engl. input
neurons), die Menge 𝑈𝑜𝑢𝑡 der Ausgabeneuronen (engl. output neurons) und die Menge
𝑈ℎ𝑖𝑑𝑑𝑒𝑛 der versteckten Neuronen (engl. hidden neurons) (Borgelt, Braune, Klawonn
2015, S. 34).“
Abbildung 8 - Aufbau eines mehrschichtigen Perzeptrons Quelle: Borgelt, Braune, Klawonn 2015, S. 44
In der vorliegenden Arbeit wird mit mehrschichtigen Perzeptren gearbeitet, die für das
Verarbeiten komplexer Informationen geeignet sind (siehe Abb. 8). Daneben gibt es

Grundlagen 37
auch einschichtige Perzeptren, die nur linear separierbare Zusammenhänge darstellen
können.
Die mehrschichtigen Perzeptren bestehen aus einer Eingabeschicht, einer
Ausgabeschicht und keiner, einer oder mehrerer versteckten Schichten (vgl. Borgelt,
Braune, Klawonn 2015, S. 44).
Die Eingabeschicht ist für die Informationsaufnahme zuständig und die Informationen
werden unverändert an die nachfolgende Schicht weiterleitet (vgl. Strecker 1997, S. 14).
Die versteckten Schichten, die von außen nicht beeinflussbar sind, übernehmen die
eigentlichen Informationsverarbeitungsprozesse. Es hängt von der Komplexität der zu
bearbeitenden Aufgabenstellung ab, wie viele verdeckte Schichten verwendet werden.
Die Ausgabeschicht ist abschließend für eine einfach zu interpretierende Netzausgabe
zuständig.
Die gewichteten Verbindungen innerhalb des neuronalen Netzes bestehen jeweils nur
zwischen Neuronen aufeinanderfolgender Schichten. Jedem Neuron sind drei
Zustandsfunktionen zugeordnet: Netzeingabefunktion (Propagierungsfunktion),
Aktivierungsfunktion und Ausgabefunktion. Der Informationsverarbeitungsprozess
eines aktiven Neurons wird in Abb. 9 veranschaulicht.
Abbildung 9 - Vereinfachter Aufbau eines Neurons Quelle: Klüver, Schmidt, Stoica-Klüver 2009, S. 105.
Die Eingabe- bzw. Propagierungsfunktion berechnet die gewichtete Summe der
Eingangssignale, die den Nettoeingabewert für das Neuron darstellen (vgl. Backhaus,
Erichson, Plinke 2016, S. 302). Die Aktivierungsfunktion berechnet daraufhin den
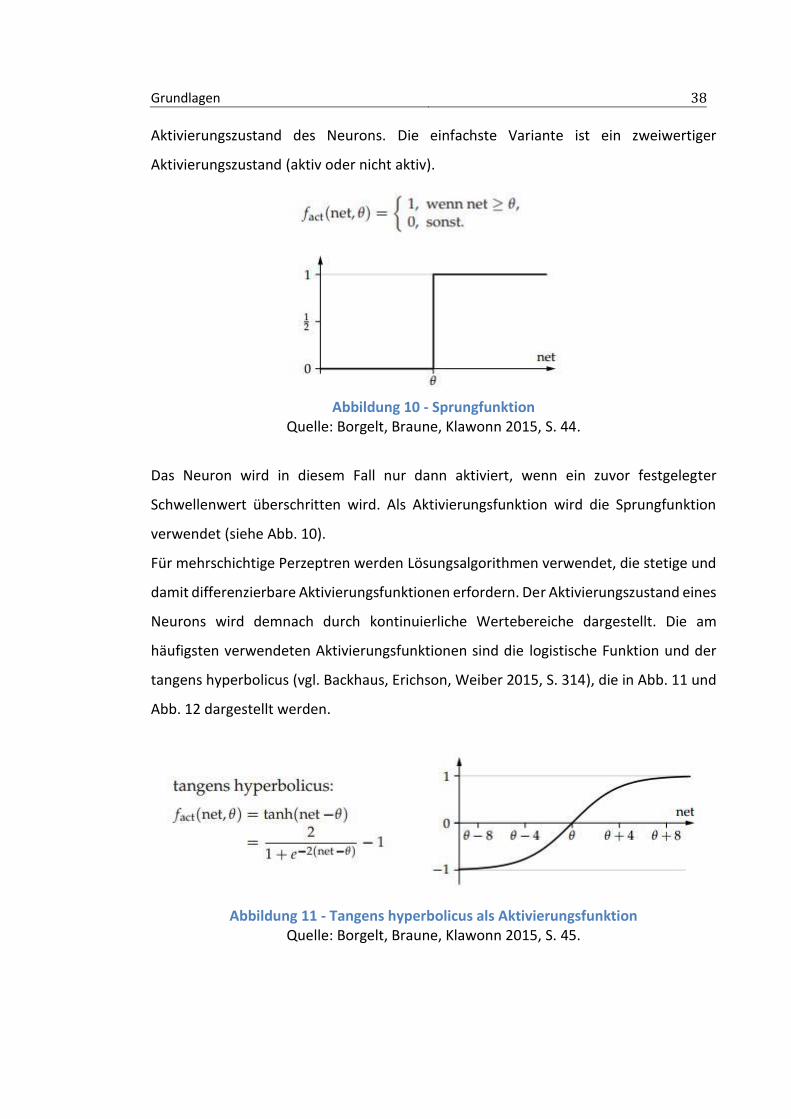
Grundlagen 38
Aktivierungszustand des Neurons. Die einfachste Variante ist ein zweiwertiger
Aktivierungszustand (aktiv oder nicht aktiv).
Abbildung 10 - Sprungfunktion Quelle: Borgelt, Braune, Klawonn 2015, S. 44.
Das Neuron wird in diesem Fall nur dann aktiviert, wenn ein zuvor festgelegter
Schwellenwert überschritten wird. Als Aktivierungsfunktion wird die Sprungfunktion
verwendet (siehe Abb. 10).
Für mehrschichtige Perzeptren werden Lösungsalgorithmen verwendet, die stetige und
damit differenzierbare Aktivierungsfunktionen erfordern. Der Aktivierungszustand eines
Neurons wird demnach durch kontinuierliche Wertebereiche dargestellt. Die am
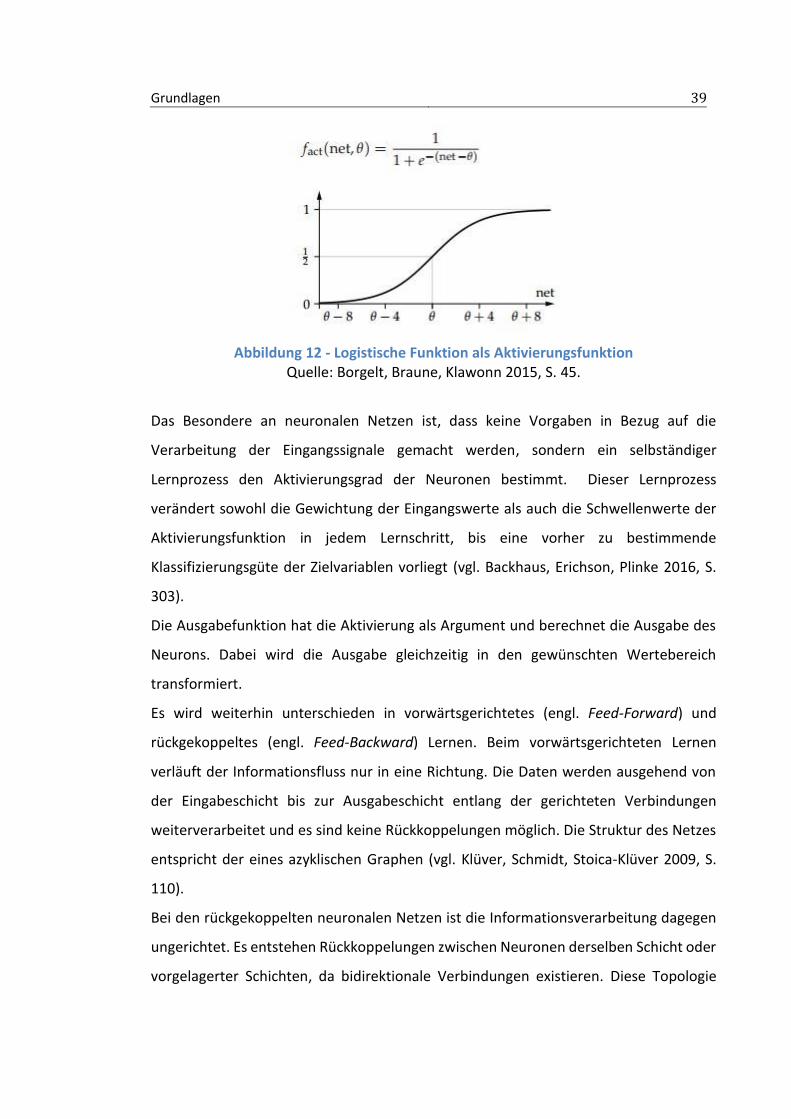
häufigsten verwendeten Aktivierungsfunktionen sind die logistische Funktion und der
tangens hyperbolicus (vgl. Backhaus, Erichson, Weiber 2015, S. 314), die in Abb. 11 und
Abb. 12 dargestellt werden.
Abbildung 11 - Tangens hyperbolicus als Aktivierungsfunktion Quelle: Borgelt, Braune, Klawonn 2015, S. 45.
Grundlagen 39
Abbildung 12 - Logistische Funktion als Aktivierungsfunktion Quelle: Borgelt, Braune, Klawonn 2015, S. 45.
Das Besondere an neuronalen Netzen ist, dass keine Vorgaben in Bezug auf die
Verarbeitung der Eingangssignale gemacht werden, sondern ein selbständiger
Lernprozess den Aktivierungsgrad der Neuronen bestimmt. Dieser Lernprozess
verändert sowohl die Gewichtung der Eingangswerte als auch die Schwellenwerte der
Aktivierungsfunktion in jedem Lernschritt, bis eine vorher zu bestimmende
Klassifizierungsgüte der Zielvariablen vorliegt (vgl. Backhaus, Erichson, Plinke 2016, S.
303).
Die Ausgabefunktion hat die Aktivierung als Argument und berechnet die Ausgabe des
Neurons. Dabei wird die Ausgabe gleichzeitig in den gewünschten Wertebereich
transformiert.
Es wird weiterhin unterschieden in vorwärtsgerichtetes (engl. Feed-Forward) und
rückgekoppeltes (engl. Feed-Backward) Lernen. Beim vorwärtsgerichteten Lernen
verläuft der Informationsfluss nur in eine Richtung. Die Daten werden ausgehend von
der Eingabeschicht bis zur Ausgabeschicht entlang der gerichteten Verbindungen
weiterverarbeitet und es sind keine Rückkoppelungen möglich. Die Struktur des Netzes
entspricht der eines azyklischen Graphen (vgl. Klüver, Schmidt, Stoica-Klüver 2009, S.
110).
Bei den rückgekoppelten neuronalen Netzen ist die Informationsverarbeitung dagegen
ungerichtet. Es entstehen Rückkoppelungen zwischen Neuronen derselben Schicht oder
vorgelagerter Schichten, da bidirektionale Verbindungen existieren. Diese Topologie

Grundlagen 40
führt zu einer Schleifenbildung, in der sich die Neuronen untereinander gegenseitig
beeinflussen (vgl. Strecker 1997, S. 16).
Der momentan wirksamste Lernalgorithmus für mehrschichtige neuronale Netze bei
überwachtem Lernen ist der Backpropagation Algorithmus (vgl. Klüver, Schmidt, Stoica-
Klüver 2009, S. 126; Backhaus, Erichson, Weiber 2015, S. 317; Oberhofer 1996, S. 17).
Der Algorithmus folgt dem Feed-Forward Prinzip, allerdings verläuft die
Fehlerpropagierung entgegengesetzt zum Informationsfluss. Die Fehlerbestimmung
setzt auf der Ausgabeschicht an, die für die Klassifizierung zuständig ist. Die
Verbindungsgewichte werden anschließend durch das Rückwärtspropagieren des
Fehlersignals ausgehend von der Ausgabeschicht durch alle Schichten hindurch bis zur
Eingabeschicht angepasst (vgl. Oberhofer 1996, S. 17).
In der Praxis werden neuronale Netze beispielsweise zur Spracherkennung,
Robotersteuerung und Schadensdiagnostik verwendet.
2.5.3 Naiver Bayes Klassifikator
Der Naive Bayes Klassifikator ist ein wahrscheinlichkeitsbasiertes
Klassifikationsverfahren, dessen Grundlage der Satz von Bayes ist. Die Zugehörigkeit
eines Objekts zu einer Klasse wird anhand der bedingten Wahrscheinlichkeit bestimmt.
Sei 𝑥 = (𝑥1, … , 𝑥𝑑) ein Datenobjekt und 𝑐 ∈ 𝐶 die Klassenzugehörigkeit, dann wird die
Klasse 𝑐 gesucht, für die die bedingte Wahrscheinlichkeit 𝑃(𝑐|𝑥) am größten ist. Die
bedingte Wahrscheinlichkeit wird mit Hilfe des Satzes von Bayes berechnet (vgl. Lenz,
Müller 2013, S. 99).
Satz von Bayes
𝑃(𝑐|𝑥) =𝑃(𝑥|𝑐) · 𝑃(𝑐)
𝑃(𝑥)
(9)

Grundlagen 41
Hierbei ist 𝑃(𝑐) die A-Priori-Wahrscheinlichkeit (Ursprungswahrscheinlichkeit) der
Klasse 𝑐.
𝑃(𝑥|𝑐) ist die Wahrscheinlichkeit von 𝑥 = (𝑥1, … , 𝑥𝑑) unter der Bedingung, dass 𝑥 der
Klasse 𝑐 angehört. 𝑃(𝑥) repräsentiert die Wahrscheinlichkeit von 𝑥. 𝑃(𝑥) ist für alle
Klassen identisch, weshalb dieser Term ignoriert werden kann. Das Ziel ist es
demzufolge, die Klasse 𝑐 zu finden, für die der Ausdruck 𝑃(𝑥|𝑐) ∙ 𝑃(𝑐) maximiert wird
(vgl. Lenz, Müller 2013, S. 100).
c* = arg max 𝑃(𝑥1, … , 𝑥𝑑 |𝑐) · 𝑃(𝑐)
(10)
𝑃(𝑐) wird aus der beobachteten Häufigkeit der einzelnen Klassen geschätzt (vgl. Runkler
2008, S. 90). Es wird eine vereinfachende Annahme getroffen um 𝑃(𝑥1, … , 𝑥𝑑|𝑐) zu
berechnen. Dabei wird unterstellt, dass die Merkmale eines Datenobjekts stochastisch
unabhängig voneinander sind. Somit wird 𝑃(𝑥1, … , 𝑥𝑑|𝑐) anhand des Produkts aller
eindimensionalen Randwahrscheinlichkeiten berechnet. Formel 10 wird wie folgt
angepasst:
c* = arg max ∏ 𝑃(𝑥𝑘|𝑐) · 𝑃(𝑐)𝑑𝑘=1 (11)
Mit Hilfe der vereinfachten Formel wird damit die Klasse 𝑐 gefunden, für die die A-
posteriori Klassifikationswahrscheinlichkeit maximal ist.
Ein Vorteil des Naiven Bayes Klassifikators ist die hohe Genauigkeit und Geschwindigkeit
des Algorithmus bei sehr großen Datensätzen. Aufgrund der vereinfachten Annahme,
dass die Attributwerte eines Datenobjekts stochastisch unabhängig voneinander sind,
entstehen in der Praxis teilweise ungenaue Ergebnisse bei der Klassifikation (vgl. Han,
Kamber, Pei 2012, S. 350).
Grundlagen 42
2.5.4 Support Vector Machine
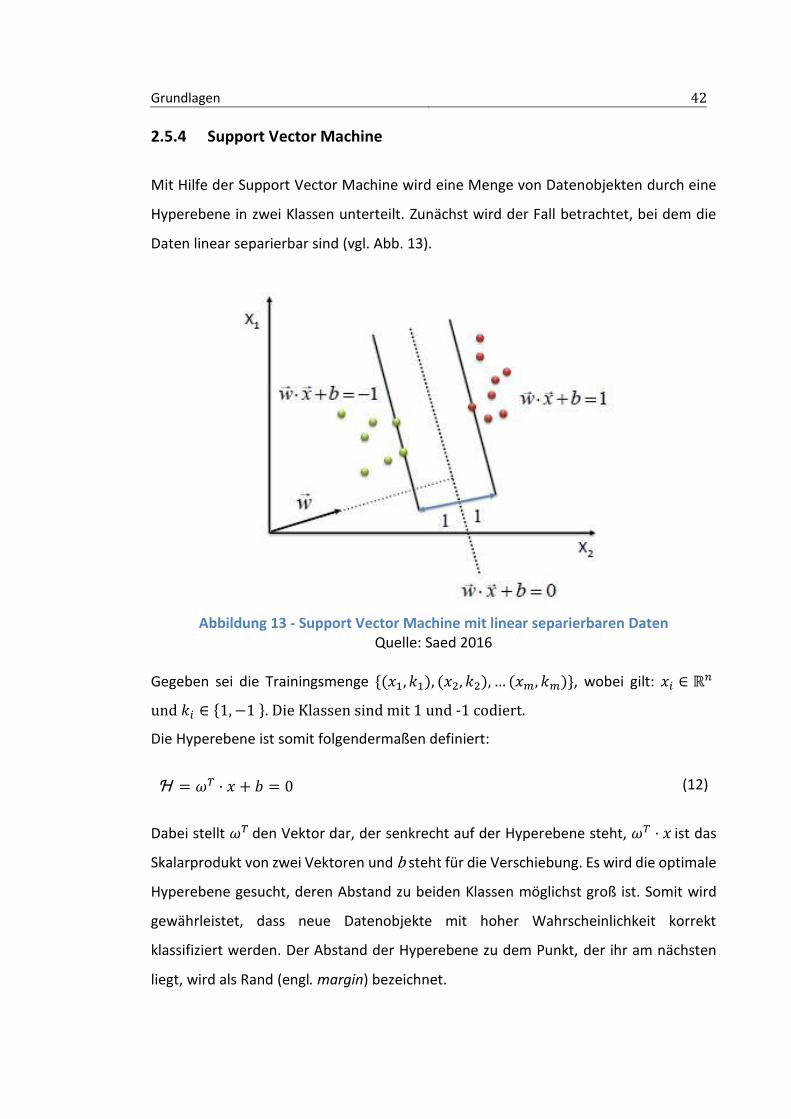
Mit Hilfe der Support Vector Machine wird eine Menge von Datenobjekten durch eine
Hyperebene in zwei Klassen unterteilt. Zunächst wird der Fall betrachtet, bei dem die
Daten linear separierbar sind (vgl. Abb. 13).
Abbildung 13 - Support Vector Machine mit linear separierbaren Daten Quelle: Saed 2016
Gegeben sei die Trainingsmenge {(𝑥1, 𝑘1), (𝑥2, 𝑘2), … (𝑥𝑚, 𝑘𝑚)}, wobei gilt: 𝑥𝑖 ∈ ℝ𝑛
und 𝑘𝑖 ∈ {1, −1 }. Die Klassen sind mit 1 und -1 codiert.
Die Hyperebene ist somit folgendermaßen definiert:
Ɦ = 𝜔𝑇 · 𝑥 + 𝑏 = 0 (12)
Dabei stellt 𝜔𝑇 den Vektor dar, der senkrecht auf der Hyperebene steht, 𝜔𝑇 · 𝑥 ist das
Skalarprodukt von zwei Vektoren und b steht für die Verschiebung. Es wird die optimale
Hyperebene gesucht, deren Abstand zu beiden Klassen möglichst groß ist. Somit wird
gewährleistet, dass neue Datenobjekte mit hoher Wahrscheinlichkeit korrekt
klassifiziert werden. Der Abstand der Hyperebene zu dem Punkt, der ihr am nächsten
liegt, wird als Rand (engl. margin) bezeichnet.

Grundlagen 43
Nach Ermittlung der optimalen Hyperebene erfolgt die Klassifizierung neuer Punkte
durch Bestimmung des Vorzeichens des obigen Terms 𝜔𝑇 · 𝑥 + 𝑏 (vgl. Friedman, Hastie,
Tibshirani 2009, S. 418; Cleve, Lämmel 2014, S. 131). Ist das Vorzeichen negativ, wird
dem Punkt die Klasse -1 zugewiesen, bei positivem Vorzeichen die Klasse 1. Für Punkte,
die auf der Hyperebene liegen, ist es nicht möglich eine Vorhersage zu treffen.
Die Punkte, die der Hyperebene am nächsten und damit direkt auf dem Rand liegen,
werden Stützvektoren (engl. support vector) genannt, woher das Verfahren seinen
Namen hat. Diese Stützvektoren bestimmen die eindeutige Lösung für das Support
Vector Machine-Verfahren. Der Rand lässt sich berechnen zu 1
||𝜔|| (vgl. Friedman, Hastie,
Tibshirani 2009, S. 419). Um den Rand bei linearer Separierbarkeit zu maximieren, wird
versucht die quadratische Norm ||𝜔|| zu minimieren unter folgenden
Nebenbedingungen:
𝑘𝑖 · (𝜔𝑇 · 𝑥𝑖 + 𝑏) ≥ 1 ∀ 𝑖 = 1, … , 𝑛 (13)
Dieses Optimierungsproblem wird mit Hilfe der Lagrange-Funktion und der Karush-
Kuhn-Tucker-Bedingungen gelöst.
Bislang wurde nur der Fall betrachtet, dass die Daten linear separierbar sind. Lassen sich
die Daten nicht linear separieren, wird der vorhandene Merkmalsraum in einen
höherdimensionalen Merkmalsraum überführt. Durch diese Vorgehensweise werden
Daten mit nichtlinearen Klassengrenzen auf Daten mit linearen Klassengrenzen
abgebildet und die Hyperebene kann nach dem oben beschriebenen Verfahren
berechnet werden (vgl. Abb. 14).

Grundlagen 44
Abbildung 14 - Klassen mit nichtlinearen Klassengrenzen Quelle: Imgur 2016
Diese Transformation wird durch die Anwendung einer Kern-Funktion (engl. kernel)
erreicht und als sogenannter Kernel-Trick bezeichnet (vgl. Runkler 2010, S. 99).
Mathematisch gesehen basiert der Kernel-Trick auf dem Satz von Mercer. Es werden
Skalarprodukte im höherdimensionalen Merkmalsraum durch Kernelfunktionen im
ursprünglichen Merkmalsraum ersetzt. Häufig verwendet werden beispielsweise die
Kern-Funktionen polynomieller Kernel, radialer Basisfunktionskernel und Gauß-Kernel
(vgl. Runkler 2010, S. 100).
Die Transformation der Daten in einen höherdimensionalen Raum ist mit einem hohen
Rechenaufwand verbunden. In einigen Fällen ist es zudem trotz dieses Verfahrens nicht
möglich, alle Daten linear zu trennen, z.B. aufgrund von Messfehlern oder Ausreißern.
Somit ist es sinnvoll, eine gewisse Anzahl von Ausreißern zuzulassen. Für diese Fälle wird
eine Schlupfvariable eingeführt. Fehlklassifikationen werden zugelassen, sie werden
allerdings bestraft. Durch Einführung der Schlupfvariable werden die
Nebenbedingungen aus Formel 13 folgendermaßen geändert:
𝑘𝑖 · (𝜔𝑇 · 𝑥𝑖 + 𝑏) ≥ 1 − 𝜉𝑖 ∀ 𝑖 1, … , 𝑛 (14)

Grundlagen 45
Zusätzlich wird ein Fehlergewicht eingeführt, dass je nach Zielsetzung bestimmt wird. Je
größer das Fehlergewicht, desto mehr werden Ausreißer bei der Modellbildung
berücksichtigt und deren Auftreten minimiert.
Die Vorteile der Support Vector Machine liegen in der hohen Klassifikationsgüte bei
korrekt spezifiziertem Kernel und der schnellen Klassifikation neuer Datenobjekte. Die
Nachteile liegen darin, dass für jeden neuen Datensatz ein erneutes Training erforderlich
ist, da die Kern-Funktion spezifiziert wird und deren Parameter geschätzt werden (vgl.
Lenz, Müller 2013, S. 108).
2.5.5 𝒌-Nächster-Nachbar-Klassifikator
Ein einfach strukturiertes Klassifikationsverfahren ist der 𝑘-Nächster-Nachbar-
Klassifikator (engl. 𝑘-nearest neighbor). Es gehört zu den Lazy Learning-Verfahren, bei
denen keine Modellbildung durch Trainieren stattfindet, sondern zur Zeit der Abfrage
jedem zu klassifizierenden Objekt anhand der Trainingsdaten eine Klasse zugewiesen
wird (vgl. Runkler 2010, S. 101).
Für ein neues, zu klassifizierendes Datenobjekt werden die 𝑘-nächstgelegenen
Datenobjekte mit bereits bekannter Klassenzugehörigkeit untersucht (vgl. Abb. 15).
Abbildung 15 - k-Nächster-Nachbar-Klassifikator Quelle: Bde 2016

Grundlagen 46
Für dieses Verfahren wird zunächst ein Abstandsmaß gewählt, beispielsweise der
Euklidische- oder der Mahalanobis-Abstand. Das neue Objekt wird der Klasse
zugeordnet, die die größte Zugehörigkeitswahrscheinlichkeit zu der Klasse hat, der die
𝑘-nächsten-Nachbarn angehören (vgl. Lenz, Müller 2013, S. 105). In der Praxis werden
meist mehrere Varianten mit unterschiedlichem 𝑘 getestet. Die Attribute der
Datenobjekte werden bei Bedarf unterschiedlich gewichtet, je nachdem, welchen
Einfluss sie auf die Klassifikation haben. Die Komplexität des Verfahrens wird durch die
Berechnung der Abstände zwischen dem zu klassifizierenden Datenobjekt und den
Nachbardatenobjekten bestimmt (vgl. Cleve, Lämmel 2014, S. 85).
Für dieses Verfahren spricht, dass ein Hinzufügen neuer Daten jederzeit ohne eine
Neuberechnung des Klassifikators möglich ist. Bei sehr großen Datensätzen ist das
Finden der Nachbardatenobjekte allerdings sehr zeitaufwendig, so dass eine
Optimierung in Form von Index-Strukturen stattfindet.
2.5.6 Logistische Regression
Die logistische Regression ist eine Variante der Regressionsanalyse. Im Rahmen dieser
Arbeit wird die binär-logistische Regressionsanalyse beschrieben, bei der die abhängige
Variable nur zwei Ausprägungen hat, da in der vorliegenden Arbeit eine binäre
Klassifizierung erfolgt. Die Zufallsvariable 𝑌 ist in diesem Fall eine 0,1-Variable.
Die Wahrscheinlichkeiten werden wie folgt berechnet:
𝑃(𝑌 = 0) = 1 – 𝑃(𝑌 = 1)
𝑃(𝑌 = 1) = 1 – 𝑃(𝑌 = 0) (15)
Das Modell der logistischen Regression wird vereinfacht beschrieben durch:
𝜋(𝑥) = 𝑓(𝑥1, … , 𝑥𝑗) (16)

Grundlagen 47
Durch 𝜋(𝑥) = 𝑃(𝑌 = 1|𝑥) wird die bedingte Wahrscheinlichkeit für den Eintritt des
Ereignisses 1 bei gegebenem 𝑥1, … , 𝑥𝑗 ausgedrückt (vgl. Backhaus, Erichson, Plinke 2016,
S. 284).
Dabei werden die unabhängigen Variablen linear kombiniert, um die latente
Zufallsvariable 𝑧(𝑥) zu beschreiben. Diese Zufallsvariable stellt den Prädiktor für die
Wahrscheinlichkeit 𝜋(𝑥) dar.
𝑧(𝑥) = 𝛽0 + 𝛽1𝑥1+. . . + 𝛽𝑗𝑥𝑗 (17)
Die Regressionskoeffizienten 𝛽𝑗 werden nach der Maximum-Likelihood-Methode
geschätzt, so dass die Wahrscheinlichkeit maximiert wird, die beobachteten Daten zu
erhalten.
Es wird eine Wahrscheinlichkeitsfunktion benötigt, um 𝜋(𝑥) bestimmen zu können. Im
Rahmen der logistischen Regression wird auf die logistische Funktion zurückgegriffen,
die bereits in Kapitel 2.4.2 als Aktivierungsfunktion für künstliche neuronale Netze
vorgestellt wurde. Die logistische Funktion als Basis ist geeignet um
Wahrscheinlichkeiten darzustellen, da ihre Werte sich ausschließlich im Intervall [0,1]
befinden (vgl. Backhaus, Erichson, Plinke 2016, S. 285).
Durch Einsetzen der Zufallsvariable 𝑧(𝑥) in die logistische Funktion erhält man die
logistische Regressionsfunktion.
𝜋(𝑥) =1
1 + 𝑒−𝑧(𝑥) (18)
Regressionswerte über 0,5 weisen dem entsprechenden Datenobjekt die Klasse 1 zu,
Werte unter 0,5 die Klasse 0.
2.5.7 Ensemble-Methoden
Ensemble Methoden kombinieren einzelne Modelle zu einem komplexen
Gesamtmodell. Durch diese Vorgehensweise wird versucht, die Stärken der jeweiligen

Grundlagen 48
Modelle auszunutzen und somit für das Gesamtmodell eine höhere Prognosegüte zu
erreichen. Die einzelnen Modelle werden als ein Komitee von Beratern betrachtet, die
sich in ihrem Wissen ergänzen und Fehler der anderen Berater im Dialog aufdecken.
Die Vorhersagen der Basis-Modelle werden gesammelt und das Ensemble-Modell
stimmt darüber ab, welche Vorhersage ausgewählt wird. Bei numerischen
Klassifikationen besteht der einfachste Weg darin, den durchschnittlichen Wert der
Basis-Modelle zu berechnen und anschließend die Klasse auszuwählen, deren Wert die
geringste Abweichung vom Durchschnittswert aufweist (vgl. Eibe, Hall, Witten 2011, S.
352). Es existieren zahlreiche Ensemble Methoden, deren wichtigste Vertreter im
Folgenden erläutert werden.
Bagging
Bagging steht für Bootstrap Aggregation. Beim Bagging wird aus einer Trainingsmenge
durch Ziehen mit Zurücklegen eine Vielzahl von Trainingsmengen generiert. Auf jeder
der erstellten Trainingsmengen wird parallel ein Modell trainiert. Die jeweiligen
Klassifikationen werden anschließend durch Mehrheitsentscheidung festgelegt. Ein
Vorteil des Baggings ist, dass die Varianz deutlich verringert wird (vgl. Elder, Seni 2010,
S. 53). Allerdings wird die Performance durch das Erstellen vieler Trainingsmengen
beeinträchtigt.
Random Forest
Die Random Forest-Methode basiert wie das Bagging auf Bootstrap-Samples. Für jede
Untermenge wird ein eigener Entscheidungsbaum (siehe Kapitel 2.4.1) erstellt, dem
jeweils nur eine Teilmenge der Attribute für die jeweiligen Splits zur Verfügung steht.
Die Teilmenge der Attribute wird für jeden Entscheidungsbaum zufällig generiert. Eine
häufig verwendete Größe für die Attributmenge ist 𝑙𝑜𝑔2(𝑛) + 1, wobei 𝑛 die Anzahl der
gesamten Attribute darstellt (vgl. Elder, Seni 2010, S. 55). Die Entscheidungsbäume
werden bis zur vorgegebenen maximalen Tiefe ausgebaut und jeder der Bäume wertet

Grundlagen 49
ein Beispiel aus. Die am häufigsten gewählte Klasse wird als Gesamtklassifikation
gewählt.
Die Vorteile der Random Forest-Methode sind die schnelle Trainingszeit und die hohe
Effizienz bei sehr großen Datenmengen.
Boosting
Beim Boosting werden iterativ mehrere Modelle desselben Typs erstellt, die
aufeinander aufbauen. Jedes neu erstellte Modell ist von der Prognosegüte seines
Vorgängers abhängig. Den fehlerhaft klassifizierten Datenobjekten des
Vorgängermodells wird ein höheres Gewicht zugewiesen, so dass der Trainingsdatensatz
bei jeder Iteration modifiziert wird (vgl. Friedman, Hastie, Tibshirani 2009, S. 338). Zur
Verbesserung des jeweils folgenden Modells wird eine zuvor aufgestellte
Kostenfunktion minimiert. Beim bekanntesten Boosting-Algorithmus, dem AdaBoost
(adaptive Boosting, deutsch: sich anpassendes Boosting) wird eine exponentielle
Kostenfunktion verwendet (vgl. Elder, Seni 2010, S. 56). Die Prognosegüte des zu Beginn
verwendeten Modells wird zunehmend gesteigert. Abschließend wird wie beim Bagging
per Mehrheitsentscheidung die Klassifikation bestimmt, wobei beim Boosting den
Entscheidungen der einzelnen Modelle unterschiedliches Gewicht beigemessen wird.
Mit Hilfe von Boosting werden im Regelfall schnell gute Ergebnisse in Bezug auf die
Trainingsdaten erzielt. Es besteht aber die Gefahr von Overfitting, das im Kapitel 2.5.3
genauer beschrieben wird.
Gradient Boosted Trees
Ähnlich wie bei der Random Forest-Methode verwendet dieses Verfahren als
Basismodelle Entscheidungsbäume mit sehr geringer Tiefe, so genannte „weak
learners“, die iterativ zu einem komplexen Modell kombiniert werden. Im Gegensatz zu
anderen Boosting-Algorithmen ist es beim Gradient-Boosting möglich, jede
differenzierbare Kostenfunktion zu optimieren (vgl. Elder, Seni 2010, S. 61). Diese

Grundlagen 50
Erweiterung wird durch die Verwendung des Gradientenverfahrens erreicht. Ein
Gradient ist ein Differentialoperator, der einem Skalarfeld ein Vektorfeld zuordnet, das
die Änderungsrate und die Richtung der größten Änderung des Feldes angibt. Das
Gradientenverfahren geht bei Minimierungsproblemen zunächst von einem
Näherungswert aus. Von diesem Näherungswert wird in Richtung des negativen
Gradienten fortgeschritten, bis keine numerische Verbesserung mehr erzielt wird.
Stacking
Beim Stacking wird ein Metalearner erstellt, der das Verfahren der
Mehrheitsentscheidung ersetzt. Dieser Metalearner erhält als Eingabe die
Klassifikationsentscheidungen einzelner Modelle, die im Vorfeld erstellt werden. Der
Metalearner basiert auf einem eigenen Algorithmus, der die Aufgabe hat, die
zuverlässigsten Modelle zu ermitteln und ihre Ergebnisse optimal zu einer finalen
Klassifikation zu kombinieren (vgl. Eibe, Hall, Witten 2011, S. 369). Der Vorteil im
Vergleich zu einem Abstimmungssystem besteht darin, dass ungenaue Modelle
herausgefiltert werden und ihnen bei der finalen Klassifikation kein Gewicht
beigemessen wird.
2.6 Modellbewertung
Das Ziel eines Klassifikationsverfahrens besteht generell darin, unbekannte
Datenobjekte möglichst präzise den jeweiligen Klassen zuzuordnen. Zur
Modellbewertung existieren verschiedene Gütemaße, die als Vergleich die zu
erwartenden Ergebnisse der Datenobjekte benötigen. Abhängig von der genauen
Aufgabenstellung werden zusätzlich die Fehlerkosten berücksichtigt, um die
Klassifikationsgüte eines Modells zu bestimmen.

Grundlagen 51
2.6.1 Gütemaße
Eine erste Einschätzung über die Modellgüte wird anhand der Fehlerrate (engl.
classification error) und der Klassifikationsgenauigkeit (engl. classification accuracy)
vorgenommen.
Fehlerrate =Falsche Klassenzuordnungen
Alle Klassenzuordnungen
(19)
Bei Klassifikationsproblemen bezeichnet die Fehlerrate den relativen Anteil der falsch
klassifizierten Datenobjekte einer Instanzenmenge.
Klassifikationsgenauigkeit =Richtige Klassenzuordnungen
Alle Klassenzuordnungen
(20)
Die Klassifikationsgenauigkeit bestimmt dagegen den relativen Anteil der richtig
klassifizierten Datenobjekte der Instanzenmenge.
In der vorliegenden Arbeit geht es um eine binäre Klassifikation, weshalb die Gütemaße
für binäre Klassifikatoren eingehender betrachtet werden. Es gibt vier mögliche
Kombinationen, die sich aus einem Vergleich der Klassifikationsergebnisse mit den
erwarteten Werten ergeben. Im Folgenden werden die Kombinationen anhand eines
Klassifikators vorgestellt, der Patienten in krank und gesund einteilt. Die
Klassifikationsgüte bezieht sich dabei auf die Klasse der kranken Patienten.
TP (richtig positiv): Ein kranker Patient wird als krank klassifiziert.
TN (richtig negativ): Ein gesunder Patient wird als gesund klassifiziert.
FP (falsch positiv): Ein gesunder Patient wird als krank klassifiziert.
FN (falsch negativ): Ein kranker Patient wird als gesund klassifiziert.
Die Ergebnisse kann man in einer Konfusionsmatrix darstellen (Abb. 16).

Grundlagen 52
Abbildung 16 - Konfusionsmatrix Quelle: Statistics 2016
Die weitere Unterteilung in vier Fälle der richtigen und falschen Klassifikation ist wichtig,
da die verschiedenen Arten der Fehlklassifikation unterschiedliche Konsequenzen und
Kosten haben. Anhand des obigen Beispiels wird dies sehr deutlich. Wird ein Patient
fälschlicherweise als gesund eingestuft und es werden keine weiteren
Behandlungsschritte eingeleitet, hat das fatale Folgen. Wird aber ein gesunder Patient
als krank eingestuft, wird höchstwahrscheinlich im Verlauf weiterer Untersuchungen
festgestellt, dass keine Krankheit vorliegt und die Auswirkungen haben eine geringere
Tragweite als bei der vorherigen Fehlklassifikation.
Auf Basis der beschriebenen Kenngrößen werden weitere abgeleitete Kenngrößen
verwendet, von denen die wichtigsten im Folgenden erläutert werden (vgl. Runkler
2010, S. 87).
Richtig − Positiv − Rate =TP
TP + FN
(21)
Die Richtig-Positiv-Rate (Sensitivität) beschreibt die Wahrscheinlichkeit, dass ein kranker
Patient als krank klassifiziert wird.

Grundlagen 53
Falsch − Positiv − Rate =FP
TN + FP
(22)
Die Falsch-Positiv-Rate beschreibt die Wahrscheinlichkeit, dass ein kranker Patient als
gesund klassifiziert wird.
Richtig − Negativ − Rate =TN
TN + FP
(23)
Die Richtig-Negativ-Rate (Spezifität) beschreibt die Wahrscheinlichkeit, dass ein
gesunder Patient als gesund klassifiziert wird.
Falsch − Negativ − Rate =FN
TP + FN
(24)
Die Falsch-Negativ-Rate beschreibt die Wahrscheinlichkeit, dass ein kranker Patient als
gesund klassifiziert wird.
Positiver Vorhersagewert =TP
TP + FP
(25)
Der positive Vorhersagewert (Präzision) beschreibt die Wahrscheinlichkeit, dass ein
krank klassifizierter Patient krank ist.
Negativer Vorhersagewert =TN
TN + FN
(26)
Der negative Vorhersagewert beschreibt die Wahrscheinlichkeit, dass ein gesund
klassifizierter Patient gesund ist.
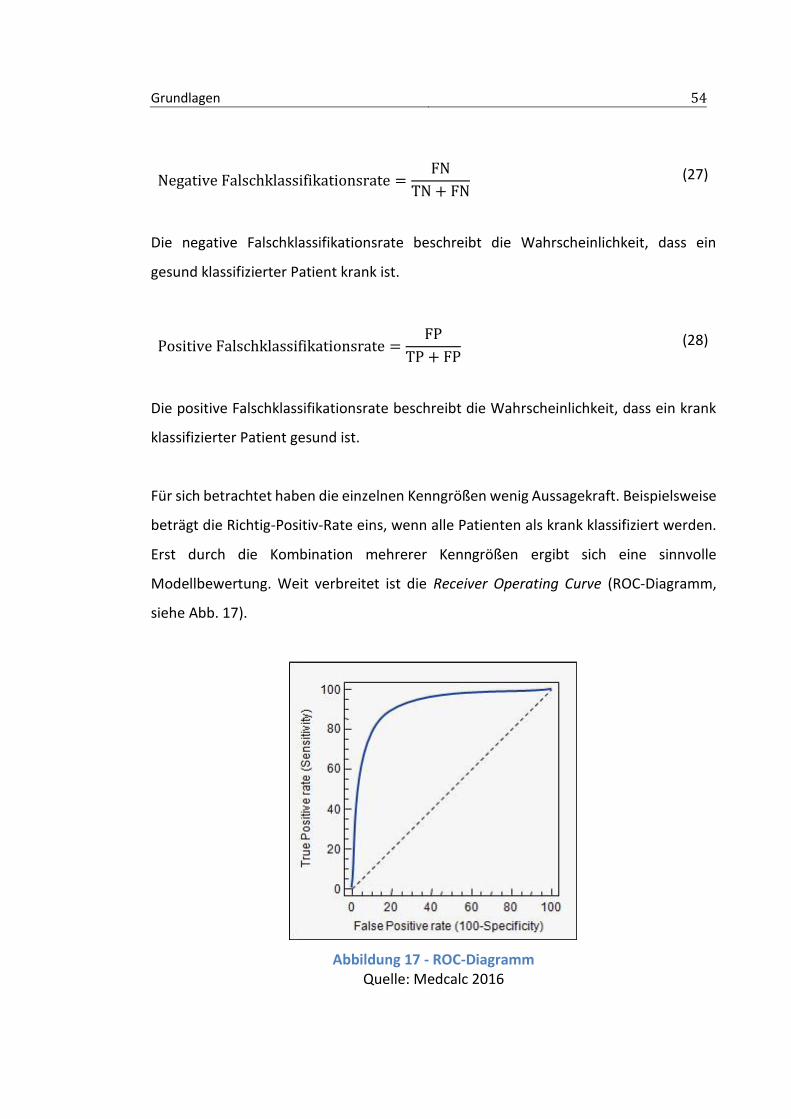
Grundlagen 54
Negative Falschklassifikationsrate =FN
TN + FN
(27)
Die negative Falschklassifikationsrate beschreibt die Wahrscheinlichkeit, dass ein
gesund klassifizierter Patient krank ist.
Positive Falschklassifikationsrate =FP
TP + FP
(28)
Die positive Falschklassifikationsrate beschreibt die Wahrscheinlichkeit, dass ein krank
klassifizierter Patient gesund ist.
Für sich betrachtet haben die einzelnen Kenngrößen wenig Aussagekraft. Beispielsweise
beträgt die Richtig-Positiv-Rate eins, wenn alle Patienten als krank klassifiziert werden.
Erst durch die Kombination mehrerer Kenngrößen ergibt sich eine sinnvolle
Modellbewertung. Weit verbreitet ist die Receiver Operating Curve (ROC-Diagramm,
siehe Abb. 17).
Abbildung 17 - ROC-Diagramm Quelle: Medcalc 2016

Grundlagen 55
In diesem Diagramm werden auf der Ordinate die Richtig-Positiv-Rate und auf der
Abszisse die Falsch-Positiv-Rate gegeneinander aufgetragen (vgl. Cleve, Lämmel 2014, S.
229; Runkler 2010, S. 87).
Das ROC-Diagramm bietet eine gute Möglichkeit, um verschiedene Klassifikatoren oder
einen Klassifikator unter Verwendung unterschiedlicher Parameter zu vergleichen. Die
ROC-Kurven entstehen durch die Variation von Parametern eines Klassifikators (vgl.
Runkler 2010, S. 88). Die Punktmenge, die dabei entsteht, wird als Kurve interpretiert.
Ein perfekter Klassifikator, der eine Richtig-Positiv-Rate von 100 % und eine Falsch-
Positiv-Rate von 0 % hat, befindet sich in einem ROC-Diagramm in der linken oberen
Ecke im Punkt (0/100). Je weiter ein Klassifikator in der Nähe dieses Punktes liegt, desto
besser ist er demzufolge. Liegt die ROC-Kurve eines Klassifikators über der Kurve eines
anderen Klassifikators ist seine Klassifikationsgüte höher. Bei einem Überschneiden der
Kurven wird der Flächeninhalt unter den beiden Kurven verglichen. Je größer der
Flächeninhalt, desto höher ist die Klassifikationsgüte.
Eine Alternative zum ROC-Diagramm bietet beispielsweise das PR-Diagramm (engl.
Precision Recall Diagramm), bei dem auf der Ordinate der positive Vorhersagewert und
auf der Abszisse die Richtig-Positiv-Rate aufgetragen werden. Beim PR-Diagramm wird
die Klassifikationsgüte der Modelle anhand des Schnittpunkts der Kurven mit der
Hauptdiagonalen bestimmt.
2.6.2 Fehlerkosten
Aus betriebswirtschaftlicher Sicht ist für ein Unternehmen besonders interessant, in
welcher Weise sich die getroffenen Klassifikationsentscheidungen auf ihren Umsatz und
Gewinn auswirken. Zu diesem Zweck werden die Fehlerkosten der einzelnen Fehlerarten
berechnet. Treten die unterschiedlichen Fehlerarten mit ihren jeweiligen Kosten
ungleich verteilt auf, ist betriebswirtschaftlich gesehen das Modell mit der
kostengünstigsten Fehlerrate optimal und nicht das Modell mit der minimalen
Fehlerrate. Für das Unternehmen ist es wichtiger, den Gewinn zu maximieren als eine

Grundlagen 56
möglichst hohe Rate an richtig klassifizierten Datenobjekten zu erzielen (vgl. Cleve,
Lämmel 2014, S. 230).
Zur Übersicht über die Fehlerkosten wird eine Kostenmatrix aufgestellt, die jeder
Klassifikationsart Umsatzsteigerungen bzw. Umsatzeinbußen zuordnet. Die für die
vorliegende Arbeit relevante Kostenmatrix ist in Abb. 18 abgebildet.
Abbildung 18 - Kostenmatrix
Die Aufgabenstellung des DMC 2010 gibt vor, dass ein Kunde, der ohne Incentivierung
nicht wiederbestellt und einen Gutschein bekommt, mit 10 % Wahrscheinlichkeit einen
Folgekauf in Höhe von 20 Euro tätigt. Diese Daten wurden laut Aufgabenstellung
empirisch ermittelt. Somit ergibt sich für eine richtige Klassifizierung der Kunden, die
nicht wiederbestellen eine durchschnittliche Umsatzsteigerung von 1,5 Euro (10 % von
15 Euro Umsatz).
Wird ein Kunde, der nicht wiederbestellt, falsch klassifiziert, entstehen dem Online-
Händler keine Umsatzeinbußen. Allerdings entgeht dem Händler eine Umsatzsteigerung
in Höhe von 1,5 Euro. Wird ein Folgekäufer richtig klassifiziert, entstehen weder
Umsatzeinbußen noch Umsatzsteigerungen. Die falsche Klassifizierung eines
Folgekäufers verursacht Umsatzeinbußen in Höhe von 5 Euro, da der Kunde den
Gutschein beim Kauf einlöst und somit 5 Euro weniger zahlt.
2.6.3 Trainings- und Testmenge
Für die Bewertung eines Klassifikators ist es wichtig, dass nicht nur eine hohe
Klassifikationsgüte in Bezug auf die Daten, die bei seinem Lernprozess verwendet
werden (Trainingsdaten), sondern auch bei neuen Datenobjekten besteht. Ansonsten

Grundlagen 57
liegt Overfitting des Klassifikators hinsichtlich der Trainingsdaten vor. Beim Overfitting
ist der Klassifikator zu spezifisch auf die Trainingsmenge ausgerichtet, so dass die
Klassifikationsleistung nicht auf neue Beispiele übertragbar ist. Beispiele für Overfitting
sind wie unter 2.4.1 beschrieben zu große Entscheidungsbäume oder ein Modell mit zu
vielen (irrelevanten) Regressoren. Deshalb ist es wichtig, den vorhandenen Datensatz
prozentual aufzuteilen und nur auf einer Teilmenge der Daten zu lernen. Mit Hilfe der
anderen Teilmenge wird die generelle Aussagekraft des Modells überprüft und es findet
eine objektive Bewertung statt. Die Teilmenge, die zur Überprüfung des Modells
verwendet wird, heißt Testmenge. Es existieren auch Fälle, in denen bereits zwei
getrennte Datensätze vorliegen. Somit ist keine weitere Partitionierung notwendig,
sondern die Datensätze werden unverändert als Trainings- und Testmenge
übernommen. Diese Vorgehensweise findet unter der Grundannahme statt, dass sich
die Daten der Testmenge genau so verhalten wie die Trainingsdaten.
Damit eine objektive Vergleichbarkeit der einzelnen Klassifikatoren möglich ist, wird für
alle angewendeten Verfahren dieselbe Zerlegung der Datenmenge benutzt (vgl. Cleve,
Lämmel 2014, S. 231).
Bipartitionierung
Bei der Bipartitionierung wird die Datenmenge in zwei disjunkte Teilmengen aufgeteilt.
Die Auswahl der Datenobjekte findet dabei zufällig statt. Die Größe der Teilmengen wird
frei bestimmt, wobei keine allgemeingültige Vorschrift zur optimalen Aufteilung
existiert. Die Aufteilung ist abhängig von der Anzahl der Instanzen und der Prädiktoren
(vgl. Friedman, Hastie, Tibshirani 2009, S. 222). Das prozentuale Verhältnis der
Trainingsmenge zur Testmenge bewegt sich in der Praxis anhand heuristischer
Gesichtspunkte zumeist im Bereich von 50/50 bis zu 70/30 (vgl. Han, Kamber, Pei 2012,
S. 370; Cleve, Lämmel 2014, S. 273; Lenz, Müller 2013, S. 97).

Grundlagen 58
Kreuzvalidierung
Bei der Kreuzvalidierung werden die zur Verfügung stehenden Datenobjekte in 𝑚 gleich
große Teilmengen unterteilt. Für das Training des Klassifikators werden 𝑚 − 1
Teilmengen benutzt. Die verbleibende Teilmenge wird als Testmenge verwendet. Dieses
Verfahren wird 𝑚 mal wiederholt, so dass jede Teilmenge genau einmal als Testmenge
benutzt wird. Die Fehlerrate ergibt sich aus dem Mittelwert der einzelnen Fehlerraten
der jeweiligen Testmenge (vgl. Lenz, Müller 2013, S. 97).
Leave-one-out-Kreuzvalidierung
Die Leave-one-out-Kreuzvalidierung stellt einen Spezialfall der Kreuzvalidierung dar. Es
wird die n-elementige Instanzenmenge in 𝑛 Teilmengen unterteilt. Die Trainingsmenge
besteht jeweils aus 𝑛 − 1 Elementen und das verbleibende Datenobjekt wird zum
Testen benutzt. Aus dem Mittelwert der Einzelfehlerwerte ergibt sich wiederum die
Gesamtfehlerrate. Somit wird jedes der Datenobjekte einmal als Testmenge verwendet.
Da bei diesem Verfahren die gesamte Datenmenge durchlaufen wird, ist die Leave-one-
out-Kreuzvalidierung mit einem hohen Rechenaufwand verbunden und somit nur für
kleine Werte von 𝑛 geeignet (vgl. Runkler 2010, S. 78). Vorteile dieser Methode sind zum
einen die optimale Ausnutzung der Daten und zum anderen das Vermeiden einer
zufälligen Stichprobenwahl.
Stratifikation
Bei der Zerlegung der Datenmenge in Teilmengen kommt es vor, dass die
Klassenverteilung der einzelnen Mengen sehr unterschiedlich ist. Die Stichproben sind
somit nicht repräsentativ. Ein Beispiel dafür ist, dass eine Klasse in den Testdaten nicht
vorkommt. Die Testdaten verhalten sich in einem solchen Fall gerade nicht ähnlich wie
die Trainingsdaten und erschweren eine zuverlässige Klassifikation. Das statistische
Modell wird unter diesen Bedingungen wahrscheinlich keine gute Vorhersage liefern.

Grundlagen 59
Im Rahmen der Stratifikation wird die Grundgesamtheit vollständig in
überschneidungsfreie Teilmengen - sogenannte Schichten - zerlegt. Die Stratifikation
zielt darauf ab, dass die Häufigkeit der Klassenverteilung innerhalb der Schichten
möglichst nahe an der Klassenverteilung der Grundgesamtheit liegt. Somit wird erreicht,
dass jede Klasse mit einer ähnlich großen relativen Häufigkeit in Trainings- und
Testmenge vorkommt (vgl. Cleve, Lämmel 2014, S. 231).
Gleichverteilung
Sind die Klassen in einem Datensatz ungleich verteilt, werden die Ergebnisse der
angewendeten Data Mining-Verfahren unter Umständen negativ beeinflusst. Häufig
wird eine Verzerrung des Ergebnisses in Bezug auf die überrepräsentierte Klasse bewirkt
(vgl. Elder, Miner, Nisbet 2009, S. 240). Bei neuronalen Netzen wird das Modell
schrittweise mit jeder Instanz trainiert, so dass die Gewichtung der Eingangssignale
fallbasiert erfolgt. Damit wird der Lernprozess wesentlich stärker von der überwiegend
vertretenen Klasse beeinflusst.
Zwei gängige Verfahren, die eine Gleichverteilung der Klassen herstellen sind das Under-
Sampling und das Over-Sampling. Beim Under-Sampling werden Datenobjekte der
überrepräsentierten Klasse gelöscht, bis beide Klassen ähnlich häufig auftreten. Beim
Over-Sampling werden Kopien der unterrepräsentierten Klasse durch Ziehen mit
Zurücklegen zum Datensatz hinzugefügt, bis eine Gleichverteilung der Klassen vorliegt
(vgl. Chawla 2005, S. 859).
Bei großen Datensätzen wird Under-Sampling verwendet, bei kleinen Datensätzen Over-
Sampling. Ansonsten sind nach dem Sampling zu wenige Datensätze zum Training
vorhanden (vgl. Elder, Miner, Nisbet 2009, S. 240).
Alternativ existieren Verfahren, um synthetische Datenobjekte der
unterrepräsentierten Klasse zu erzeugen. Ein bekannter Algorithmus ist der SMOTE-
Algorithmus (Synthetic Minority Over-Sampling Technique). SMOTE ist eine Over-
Sampling-Methode. Diese Methode benutzt den 𝑘-nächster-Nachbar-Klassifikator um
eine oder mehrere Instanzen zu ermitteln, die einem Datenobjekt der

Grundlagen 60
unterrepräsentierten Klasse am nächsten liegen. Für jedes Merkmal wird die Differenz
zwischen dem Merkmalsvektor des jeweiligen Datenobjekts und einem der
ausgewählten Nachbarn berechnet. Anschließend wird diese Differenz mit einem
zufälligen Wert zwischen 0 und 1 multipliziert und zu dem Merkmalsvektor des
Datenobjekts addiert (vgl. Chawla 2005, S. 860). Somit entstehen neue Datenobjekte
mit Merkmalswerten, die zwischen den Merkmalswerten zweier Nachbarn derselben
Klasse liegen.
Eine andere Option besteht darin, die Klassen unterschiedlich zu gewichten. Den
Objekten der unterrepräsentierten Klasse wird ein höheres Gewicht verliehen, um ihren
Einfluss auf das Klassifikationsergebnis zu erhöhen (vgl. Elder, Miner, Nisbet 2009, S.
240).
2.7 KNIME
Die vorliegende Arbeit verwendet zur Bearbeitung der Aufgabenstellung das Tool
KNIME.
KNIME ist eine modulare Datenexplorationsplattform, die an der Universität Konstanz
unter Leitung von Prof. Berthold entwickelt wurde. Die Abkürzung KNIME steht für
Konstanz Information Miner. Die erste Version wurde 2006 vorgestellt. In dieser Arbeit
wird die aktuelle KNIME Version 3.2.0 für Windows inklusive aller frei verfügbaren
Extensions verwendet. In KNIME werden Datenflüsse durch das Pipelining-Konzept
dargestellt. Die Ausgabe eines Knotens wird vom jeweiligen Nachfolgeknoten als
Eingabe verwendet. KNIME wurde in JAVA entwickelt und wird als Plugin für die
Entwicklungsumgebung Eclipse angeboten.
KNIME bietet Methoden für den kompletten Data-Mining-Prozess an. Es sind Module
für den Datenimport, die Datenvorverarbeitung, die Datenanalyse und die Darstellung
der Ergebnisse vorhanden. KNIME stellt mehr als 1000 Module bereit, die innerhalb der
Software als Nodes (Knoten) bezeichnet werden (vgl. KNIME 2016).

Grundlagen 61
Abbildung 19 - Ausschnitt aus einem KNIME Workflow
Die Knoten werden per Drag&Drop aus dem Node Repository in das Workflow-Fenster
gezogen und anschließend miteinander verknüpft (vgl. Abb. 19). Die Knoten im Node
Repository sind in Kategorien wie beispielsweise Manipulation, Scripting und IO
unterteilt, so dass eine Suche nach bestimmten Knoten erleichtert wird. Im Workflow-
Fenster findet der Modellierungsprozess statt und die Knoten werden verwaltet und
konfiguriert. Die Konfiguration erfolgt über das Kontextmenü der jeweiligen Knoten. Ein
Ampelsystem unter den Knoten teilt den aktuellen Status mit. Ein unkonfigurierter
Knoten ist rot markiert, ein konfigurierter Knoten gelb und ein korrekt ausgeführter
Knoten grün. Bei dem Auftreten von Fehlern oder Besonderheiten während der
Ausführung erscheint unter dem Knoten ein Warndreieck mit der entsprechenden
Meldung.
Im Fenster KNIME Explorer werden die angelegten Projekte verwaltet. Zusätzlich gibt es
noch das Fenster Node Description, das eine detaillierte Beschreibung der einzelnen

Grundlagen 62
Knoten liefert. Der Algorithmus des Knotens wird erläutert, die
Konfigurationsmöglichkeiten werden dargestellt und Input- sowie Output-
Informationen sind ersichtlich.
Eine gute Möglichkeit, umfangreiche Workflows übersichtlicher zu gestalten, bieten die
sogenannten Metanodes. Metanodes enthalten Unter-Workflows mit weiteren Knoten.
Im Haupt-Workflow sehen sie wie Einzelknoten aus. Durch Doppelklick auf einen
Metanode werden alle im Metanode zusammengefassten Knoten „ausgeklappt“. Somit
wird eine Funktion angeboten um inhaltlich stark zusammenhängende
Verarbeitungsprozesse in einen übergeordneten Knoten zu integrieren. In Abb. 20 sieht
man beispielsweise einen Metanode, der für die Transformation inkonsistenter Werte
zuständig ist. In Abb. 21 wird ein Teil des Workflows dargestellt, den der Metanode
enthält.
Dabei ist es auch möglich, in einem Metanode weitere Metanodes zu erstellen und den
Workflow zu „verschachteln“.
Abbildung 20 - Darstellung eines Metanodes
Zusätzlich zu den vorhandenen Knoten besteht die Option, eigene Knoten zu entwickeln.
Beispielsweise gibt es den JAVA Snippet Knoten, der es ermöglicht, eigenen Code zu
implementieren und somit zusätzliche Funktionalität zu schaffen.

Grundlagen 63
Abbildung 21 - Ausschnitt aus dem Workflows des Metanodes aus Abb. 20
2.8 After Sales Marketing
In der heutigen Zeit, in der ein breites Spektrum von Online-Händlern am Markt
vertreten ist, gewinnt ein individuell gestalteter Service nach dem eigentlichen Kauf
immer mehr an Bedeutung um sich von den anderen Wettbewerbern abzugrenzen (vgl.
Hogenschurz, Keuper 2008, S. 294). Durch die sich verändernden Rahmenbedingungen
mit einer erhöhten Wettbewerbsintensität und Marktsättigungserscheinungen, sowie
steigenden Kundenanforderungen verschiebt sich der Fokus im Marketing zunehmend
vom verkaufsorientierten Transaktionsmarketing zum Relationshipmarketing bzw. After
Sales Marketing (vgl. Schnöring 2016, S. 11).
Das After Sales Marketing zielt darauf ab, die Kunden nach ihrer Kaufentscheidung an
die eigenen Produkte bzw. das eigene Geschäft zu binden und eine
Kundenabwanderung zu verhindern. Maßnahmen zur Etablierung einer langfristigen
Kundenbeziehung und zur Kundenrückgewinnung sind schon alleine aus Kostengründen
sinnvoll. Studien haben ergeben, dass die Kosten zur Neukundenakquise deutlich über

Grundlagen 64
den Kosten zur Kundenpflege und Kundenrückgewinnung liegen (vgl. Günter, Neu 2015,
S. 28; Schnöring 2016, S. 12).
In der vorliegenden Arbeit geht es für den Online-Händler primär darum, einen
wirtschaftlichen Vorteil zu erlangen, in dem an ausgewählte Kunden ein Gutschein
versendet wird, die ohne Gutschein keinen Folgekauf tätigen. Durch die Folgekäufe wird
zusätzlicher Umsatz generiert, dessen Höhe im weiteren Verlauf der Arbeit genauer
untersucht wird. Gutscheine entfalten ihre Wirkung im Vergleich zu Bonusprogrammen
sofort bei Einlösung und der Kunde spürt den direkten Nutzen.
Zusätzlich zu diesem sofortigen Effekt gibt es weitere Vorteile, die sich aus After Sales
Marketing-Maßnahmen ergeben (vgl. Hogenschurz, Keuper 2008, S. 294):
Verbesserung der Kundenzufriedenheit
Up- und Cross-Selling
Ausbau des Bekanntheitsgrades und Imageverbesserung
Erhöhung der Weiterempfehlungsrate
Bereitschaft der langfristig gebundenen Kunden, höhere Preise zu akzeptieren durch Verringerung des Qualitäts- und Vertrauensrisikos
Informationsgewinn in Bezug auf Kundenwünsche und Markttrends
Unentbehrlich für das After Sales Marketing ist ein Kundenwertmodell, das sich am
gesamten Customer Lifetime Value orientiert (vgl. Abb. 22).
Der Customer Lifetime Value ist der Deckungsbeitrag, den ein Kunde über die gesamte
voraussichtliche Geschäftsbeziehung hinweg realisiert, diskontiert auf den Zeitpunkt der
Betrachtung (vgl. Bruhn, Hadwich, Meffert 2015, S. 46). Anhand des ermittelten Modells
kann individuell ausgerichtet eine Prozesskette in Gang gesetzt werden, die von der
Planung bis hin zur Erfolgskontrolle der angewendeten Maßnahmen reicht (vgl.
Hogenschurz, Keuper 2008, S. 298).
Grundlagen 65
Abbildung 22 - Customer Lifetime Value Quelle: Wikim 2016
Darüber hinaus ist die Identifikation der abwanderungsgefährdeten Kunden notwendig,
was einen Teilbereich des Churn Managements darstellt. Das Churn Management zielt
generell darauf ab, rentable Kunden zu halten und unrentablen Kunden das Abwandern
zu erleichtern. Im Rahmen des Churn Managements werden über statistische Modelle
die Abwanderungswahrscheinlichkeiten der Kunden anhand relevanter Prädikatoren
berechnet (vgl. Günter, Neu 2015, S. 91).
In der vorliegenden Arbeit geht es darum, die Kunden zu klassifizieren, die ohne
Incentivierung durch einen Gutschein keine weitere Bestellung aufgeben. Es wird kein
zusätzliches Kundenwertmodell erstellt, das die Rentabilität der Kunden widerspiegelt.
Es wird demzufolge allen Kunden ein Gutschein zugeschickt, die nicht als Folgekäufer
klassifiziert werden.
In der Praxis ist es teilweise schwierig, die Profitabilitätsauswirkungen von
Kundenbindungsmaßnahmen genau zu ermitteln, da viele Faktoren bei der Bewertung
eine Rolle spielen. Beispielsweise werden negative Auswirkungen auf Nicht-Zielkunden
beobachtet und die Kundenzufriedenheit, die auch für den weiteren Customer Lifetime
Value eine Rolle spielt, ist schwierig zu quantifizieren.
Die im Rahmen dieser Arbeit bearbeitete Aufgabenstellung enthält präzise Vorgaben
hinsichtlich des Umsatzes. Ein Kunde, der ohne Zusendung des Gutscheins keinen

Empirischer Teil 66
Folgekauf tätigt, generiert nach Erhalt eines Gutscheins durchschnittlich zusätzlichen
Umsatz in Höhe von 1,50 Euro.
3 Empirischer Teil
Im empirischen Teil werden zahlreiche statistische Modelle entwickelt und optimiert,
um den Umsatz des Online-Händlers in Bezug auf das After Sales Management zu
maximieren. Der Data Mining-Prozess orientiert sich mit einigen Ausnahmen am CRISP-
DM (siehe Kapitel 2.2.2).
3.1 Geschäftsmodell und Datenerhebung
Die zur Verfügung gestellten Daten stammen von einem Online-Händler für
Medienprodukte. Wie bereits erläutert, ist das betriebswirtschaftliche Ziel der
vorliegenden Aufgabe, den Umsatz des Online-Händlers mit Hilfe einer gezielten After
Sales Marketing-Maßnahme zu maximieren. Es werden dabei im Rahmen der
Aufgabenstellung keine Vorgaben in Bezug auf die Höhe der Umsatzsteigerung getätigt.
Der Trainingsdatensatz besteht aus einer Tabelle mit 32.428 Zeilen, der Testdatensatz
beinhaltet 32.427 Zeilen. Beide Datensätze haben 38 Spalten inklusive des
Klassifikationsattributes.
Die originalen Spaltenattribute werden im Folgenden vorgestellt:
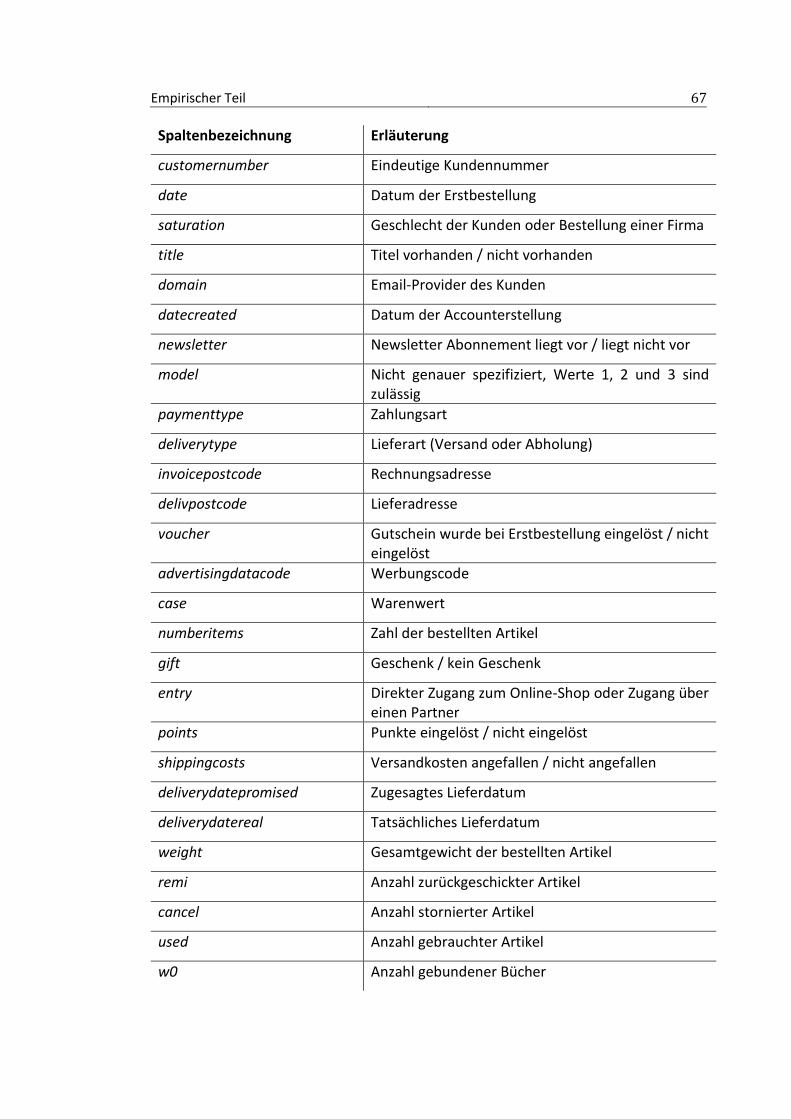
Empirischer Teil 67
Spaltenbezeichnung Erläuterung
customernumber Eindeutige Kundennummer
date Datum der Erstbestellung
saturation Geschlecht der Kunden oder Bestellung einer Firma
title Titel vorhanden / nicht vorhanden
domain Email-Provider des Kunden
datecreated Datum der Accounterstellung
newsletter Newsletter Abonnement liegt vor / liegt nicht vor
model Nicht genauer spezifiziert, Werte 1, 2 und 3 sind zulässig
paymenttype Zahlungsart
deliverytype Lieferart (Versand oder Abholung)
invoicepostcode Rechnungsadresse
delivpostcode Lieferadresse
voucher Gutschein wurde bei Erstbestellung eingelöst / nicht eingelöst
advertisingdatacode Werbungscode
case Warenwert
numberitems Zahl der bestellten Artikel
gift Geschenk / kein Geschenk
entry Direkter Zugang zum Online-Shop oder Zugang über einen Partner
points Punkte eingelöst / nicht eingelöst
shippingcosts Versandkosten angefallen / nicht angefallen
deliverydatepromised Zugesagtes Lieferdatum
deliverydatereal Tatsächliches Lieferdatum
weight Gesamtgewicht der bestellten Artikel
remi Anzahl zurückgeschickter Artikel
cancel Anzahl stornierter Artikel
used Anzahl gebrauchter Artikel
w0 Anzahl gebundener Bücher

Empirischer Teil 68
w1 Anzahl Taschenbücher
w2 Anzahl Schulbücher
w3 Anzahl eBooks
w4 Anzahl versendeter Hörbücher
w5 Anzahl heruntergeladener Hörbücher
w6 Anzahl Filme
w7 Anzahl Musikartikel
w8 Anzahl Hardwareartikel
w9 Anzahl importierter Artikel
w10 Anzahl sonstiger Artikel
target90 Klassifikationsattribut, Folgebestellung innerhalb von 90 Tagen ist erfolgt / nicht erfolgt
Tabelle 1 - Erläuterung der Spaltenattribute
Bei der ersten Untersuchung der Daten fällt auf, dass sowohl Trainings- als auch
Testdaten aus dem selben Zeitraum stammen. Die Bestellungen erfolgten im Zeitraum
vom 01.04.2008 bis zum 31.03.2009, wie aus der Spalte date hervorgeht. Aus dem
Attribut deliverytype geht hervor, dass neben dem Versand auch die Möglichkeit der
Abholung direkt beim Händler besteht, was bei Online-Händlern nicht selbstverständlich
ist.
Das Klassifikationsmerkmal target90 ist bei beiden Datensätzen ähnlich verteilt, wie in
Tabelle 2 dargestellt.
Klassifikationsmerkmal 1 0
target90 (Trainingsmenge)
6.051 (18,7 %) 26.377 (81,3 %)
target90 (Testmenge)
6.168 (19 %) 26.259 (81 %)
Tabelle 2 - Verteilung des Klassifikationsmerkmals target90
Der überwiegende Teil beider Datensätze besteht somit aus Kunden, die ohne
Incentivierung keinen Folgekauf tätigen.

Empirischer Teil 69
Durch zusätzliche Untersuchung der Daten mit Hilfe statistischer Knoten werden
weitere Auffälligkeiten ermittelt. Diese werden für Trainings- und Testmenge gesondert
aufgeführt, um die Vergleichbarkeit beider Datensätze festzustellen.
Trainingsmenge
Die Spalte delivpostcode enthält 31.036 fehlende Werte.
Die Spalte advertisingdatacode enthält 25.905 fehlende Werte.
Die Spalte points enthält ausschließlich den Wert 0.
Die Spalte deliverydatereal enthält 5.472 Mal den inkorrekten Wert „0000-00-00“.
Die Spalte deliverydatepromised enthält neun inkorrekte Werte mit dem Jahr 4746.
Testmenge
Die Spalte delivpostcode enthält 30.984 fehlende Werte.
Die Spalte advertisingdatacode enthält 26.146 fehlende Werte.
Die Spalte points enthält ausschließlich den Wert 0.
Die Spalte deliverydatereal enthält 5.355 Mal den inkorrekten Wert „0000-00-00“.
Die Spalte deliverydatepromised enthält fünf inkorrekte Werte mit dem Jahr 4746.
Die Spalte invoicepostcode enthält einen fehlenden Wert
Die Datensätze weisen nahezu identische Auffälligkeiten auf. Eine Untersuchung der
weiteren Attribute bestätigt die hohe Ähnlichkeit der Datensätze. Somit wird davon
ausgegangen, dass beide Mengen einen repräsentativen Ausschnitt der Kundendaten
darstellen und es möglich ist, einen erfolgreichen Data Mining-Prozess durchzuführen.
Hinsichtlich der Datentypen fällt auf, dass die Datumsangaben alle als Strings im Format
„YYYY-MM-DD“ (Jahr, Monat, Tag) vorliegen. Somit ist es schwierig, sie mit den
zahlreichen Time Difference, Date Shift und Date Extractor Nodes auszulesen und
weiterzuverarbeiten. Eine Typumwandlung in ein geeignetes Datumsformat ist damit
erforderlich.
Neben den aufgeführten Punkten fallen die teilweise langen Liefer- bzw. Abholzeiten
auf. Im Trainingsdatensatz existieren beispielsweise 429 Bestellungen, deren Liefer-

Empirischer Teil 70
oder Abholzeit über ein Jahr beträgt. Es ergeben sich allerdings keine Ansatzpunkte
dafür, dass diese Daten inkorrekt sind.
Lange Lieferzeiten treten z.B. bei schwer erhältlichen Produkten auf, die nicht auf Lager
sind. Darüber hinaus werden von einigen Kunden bei begehrten Artikeln
Vorbestellungen vorgenommen, damit das gewünschte Produkt zum Verkaufsstart
sofort geliefert wird. Somit werden die aufgeführten Lieferzeiten nicht als inkorrekt
eingestuft.
Zudem bestehen erhebliche Differenzen zwischen zugesagten und tatsächlichen
Lieferterminen. Es gibt in der Trainingsmenge 777 Bestellungen, die um mindestens 30
Tage verspätet geliefert wurden. Eine ähnliche Verteilung ist in den Testdaten zu
beobachten.
Bei einer Vielzahl von Datensätzen kommt es vor, dass in einigen Fällen das
versprochene Lieferdatum nicht eingehalten wird. Es ist beispielsweise möglich, dass die
Lieferanten des Medienhändlers Produkte verspätet liefern oder dass Probleme bei der
Zustellung der Artikel auftreten.
Somit werden die entsprechenden Werte nicht als inkorrekt eingestuft.
3.2 Datenvorverarbeitung
Die Datenaufbereitung wird unterteilt in das Behandeln der fehlenden und der
inkonsistenten Werte, die Umwandlung der Daten in geeignete Datentypen, sowie das
Erstellen zusätzlicher Variablen.
3.2.1 Fehlende und irrelevante Werte
Im Folgenden werden die fehlenden Werte, aufgeteilt nach Trainings- und Testmenge
dargestellt.
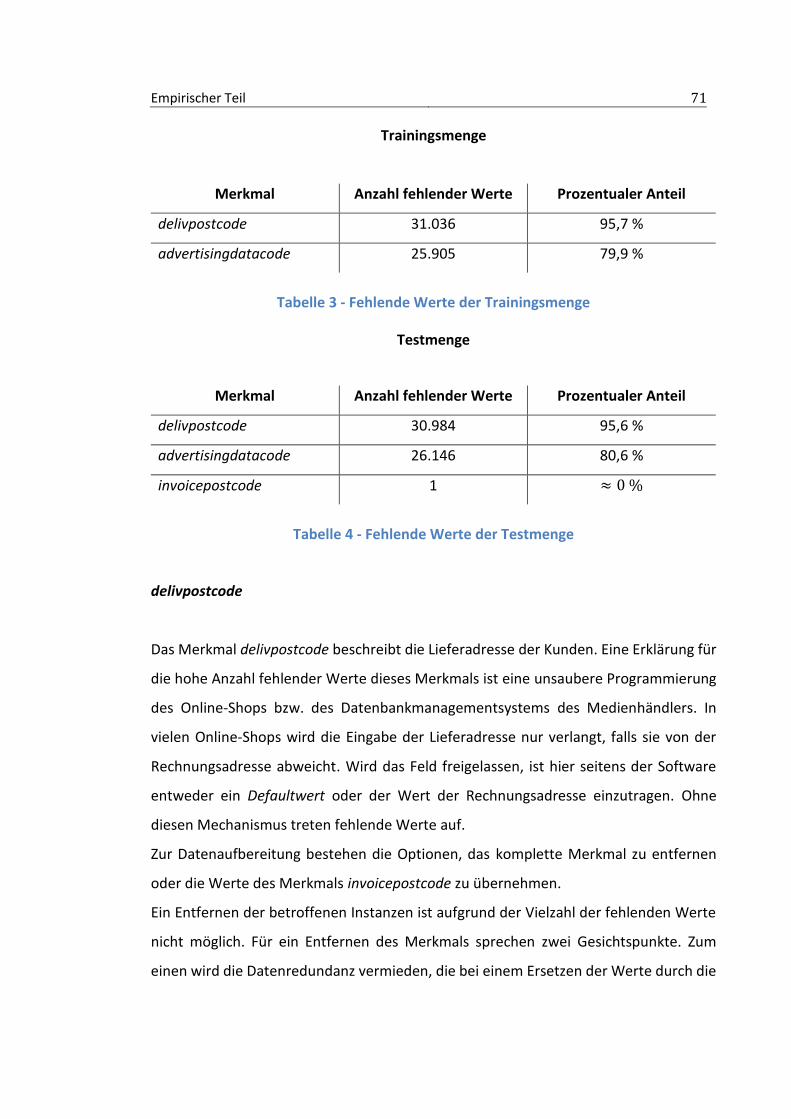
Empirischer Teil 71
Trainingsmenge
Merkmal Anzahl fehlender Werte Prozentualer Anteil
delivpostcode 31.036 95,7 %
advertisingdatacode 25.905 79,9 %
Tabelle 3 - Fehlende Werte der Trainingsmenge
Testmenge
Merkmal Anzahl fehlender Werte Prozentualer Anteil
delivpostcode 30.984 95,6 %
advertisingdatacode 26.146 80,6 %
invoicepostcode 1 ≈ 0 %
Tabelle 4 - Fehlende Werte der Testmenge
delivpostcode
Das Merkmal delivpostcode beschreibt die Lieferadresse der Kunden. Eine Erklärung für
die hohe Anzahl fehlender Werte dieses Merkmals ist eine unsaubere Programmierung
des Online-Shops bzw. des Datenbankmanagementsystems des Medienhändlers. In
vielen Online-Shops wird die Eingabe der Lieferadresse nur verlangt, falls sie von der
Rechnungsadresse abweicht. Wird das Feld freigelassen, ist hier seitens der Software
entweder ein Defaultwert oder der Wert der Rechnungsadresse einzutragen. Ohne
diesen Mechanismus treten fehlende Werte auf.
Zur Datenaufbereitung bestehen die Optionen, das komplette Merkmal zu entfernen
oder die Werte des Merkmals invoicepostcode zu übernehmen.
Ein Entfernen der betroffenen Instanzen ist aufgrund der Vielzahl der fehlenden Werte
nicht möglich. Für ein Entfernen des Merkmals sprechen zwei Gesichtspunkte. Zum
einen wird die Datenredundanz vermieden, die bei einem Ersetzen der Werte durch die

Empirischer Teil 72
Werte des Merkmals invoicepostcode auftritt. Nach einem Ersetzen sind über 95 % der
entsprechenden Werte identisch. Zum anderen entsteht durch die geringe Menge an
vorhandenen Werten kein großer Informationsverlust. Somit wird das Merkmal
delivpostcode entfernt.
advertisingdatacode
Das Merkmal advertisingdatacode beschreibt, ob bei der Bestellung ein Werbungscode
verwendet wurde. Es ist davon auszugehen, dass die Kunden ohne Werbungscode das
entsprechende Feld freigelassen haben und die Software des Medienhändlers auch in
diesem Fall keine Standardbehandlung fehlender Werte vorsieht. Der Anteil der
fehlenden Werte in beiden Mengen liegt ca. bei 80 %.
Damit besteht auch in diesem Fall die Option, das Merkmal aus den Datensätzen zu
entfernen. Im Vergleich zu dem Merkmal delivpostcode ist der Anteil der fehlenden
Werte deutlich geringer (ca. 15 % Differenz). Somit entsteht durch ein Entfernen ein
größerer Informationsverlust hinsichtlich der vorhandenen Werte des Merkmals.
Zusätzlich haben bei einem Kauf in einem Online-Shop empirisch gesehen nicht alle
Kunden einen Werbungscode, so dass eine sinnvolle Erklärung wie beschrieben ein
Freilassen des entsprechenden Feldes in der Eingabemaske darstellt. Damit wird das
Merkmal nicht entfernt.
Zunächst werden alle fehlenden Werte des Merkmals durch den konstanten Wert 0
ersetzt. Dies wird mit dem Missing Value-Knoten durchgeführt. Eine Möglichkeit ist, die
vorhandenen Codes im String-Format zu belassen und sie nicht weiter zu
transformieren. Da einige Modelle wie beispielsweise neuronale Netze als Inputdaten
Number-Werte benötigen, werden die Werbungscodes mit Hilfe eines Java Snippet-
Knoten in Integer-Werte umgewandelt. Die Codes umfassen den Wertebereich
𝐴𝐴, 𝐴𝐵, … 𝐵𝑍, 𝐶𝐴, wie aus der Übersicht Occurrences des Statistics-Knoten ersichtlich
ist (vgl. Abb. 23).

Empirischer Teil 73
Abbildung 23 - Auszug aus den advertisingdatacode-Werten der Trainingsmenge
Somit werden die die Zahlen 1 - 53 vergeben. Ein Teil des Java Snippets ist in Abb. 24
dargestellt.
Abbildung 24 - Java Snippet zur Umwandlung der advertisingdatacode-Werte

Empirischer Teil 74
invoicepostcode
In der Testmenge tritt eine Instanz mit einem fehlenden Wert beim Merkmal
invoicepostcode auf. Für diese Instanz wird der fehlende Wert durch das arithmetische
Mittel der übrigen Werte des Merkmals ersetzt.
points
Das Merkmal points beschreibt, ob Punkte eingelöst wurden. Es geht aus der
Aufgabenstellung nicht hervor, auf welchen Sachverhalt sich die Punkte beziehen. In
beiden Mengen nimmt das Merkmal ausschließlich den Wert 0 an und besitzt somit
keine verwertbare Aussagekraft. Somit wird das Merkmal entfernt.
3.2.2 Inkonsistente Werte
Es liegen auffällige Werte für die Merkmale deliverydatepromised und deliverydatereal
vor, die im Folgenden untersucht werden. Die Werte der Merkmale werden im Date-
Format nach einer erfolgten Typkonvertierung vom ursprünglichen String-Format
dargestellt. Zu beachten ist, dass die ursprünglichen Werte des Merkmals
deliverydatereal, die als String in der Form 0000-00-00 vorlagen, nach der
Typumwandlung die Datumsangabe 30.Nov.0002 aufweisen. Dieses Verhalten ist auf
interne Konvertierungsprozesse innerhalb von KNIME zurückzuführen und hat keine
negativen Auswirkungen auf die weitere Verarbeitung.
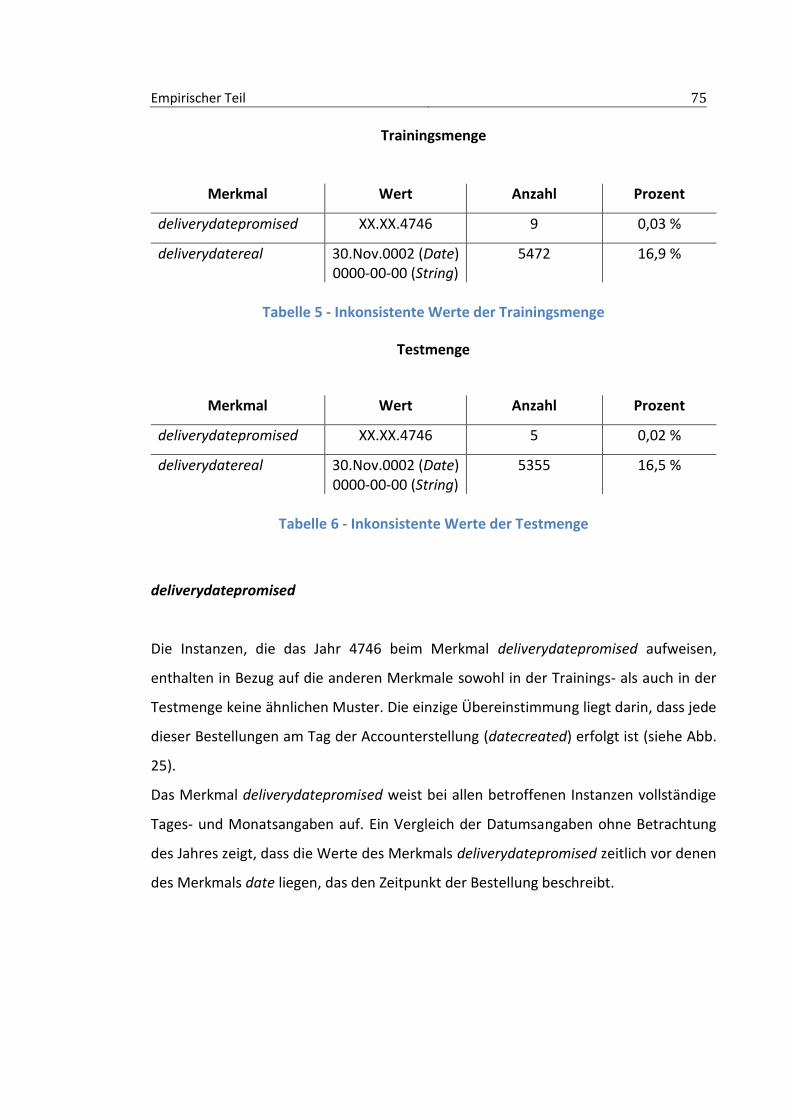
Empirischer Teil 75
Trainingsmenge
Merkmal Wert Anzahl Prozent
deliverydatepromised XX.XX.4746 9 0,03 %
deliverydatereal 30.Nov.0002 (Date) 0000-00-00 (String)
5472 16,9 %
Tabelle 5 - Inkonsistente Werte der Trainingsmenge
Testmenge
Merkmal Wert Anzahl Prozent
deliverydatepromised XX.XX.4746 5 0,02 %
deliverydatereal 30.Nov.0002 (Date) 0000-00-00 (String)
5355 16,5 %
Tabelle 6 - Inkonsistente Werte der Testmenge
deliverydatepromised
Die Instanzen, die das Jahr 4746 beim Merkmal deliverydatepromised aufweisen,
enthalten in Bezug auf die anderen Merkmale sowohl in der Trainings- als auch in der
Testmenge keine ähnlichen Muster. Die einzige Übereinstimmung liegt darin, dass jede
dieser Bestellungen am Tag der Accounterstellung (datecreated) erfolgt ist (siehe Abb.
25).
Das Merkmal deliverydatepromised weist bei allen betroffenen Instanzen vollständige
Tages- und Monatsangaben auf. Ein Vergleich der Datumsangaben ohne Betrachtung
des Jahres zeigt, dass die Werte des Merkmals deliverydatepromised zeitlich vor denen
des Merkmals date liegen, das den Zeitpunkt der Bestellung beschreibt.
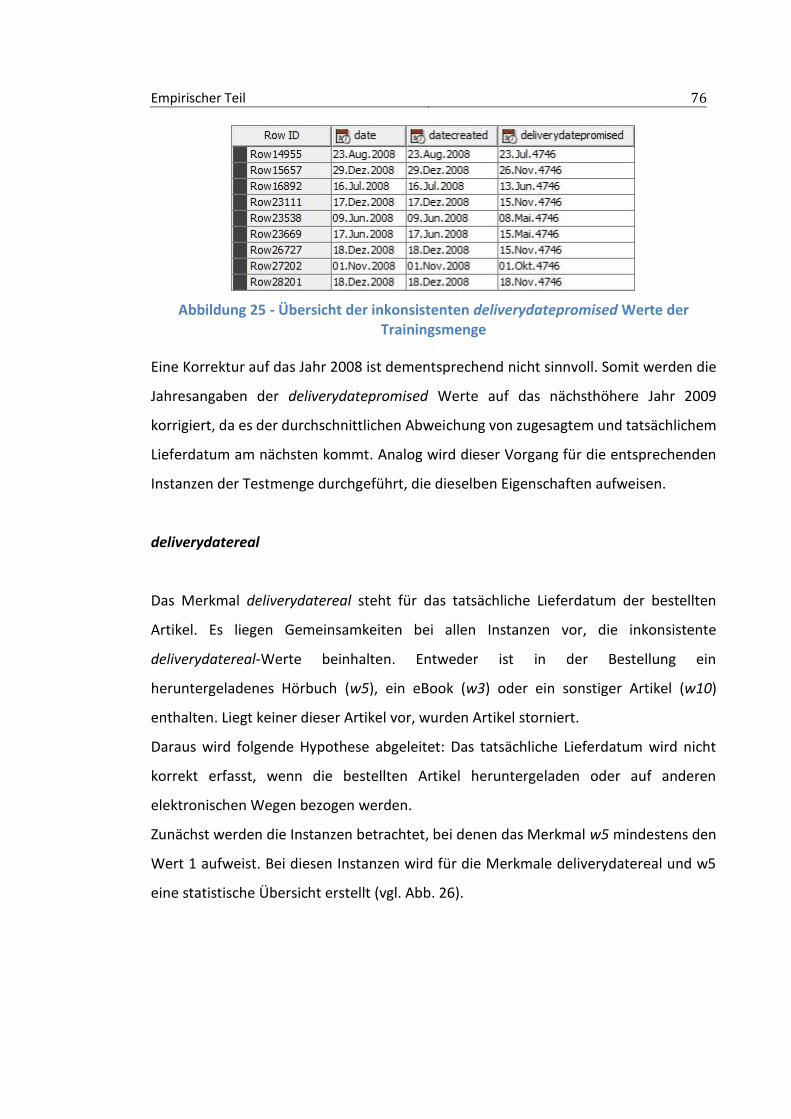
Empirischer Teil 76
Abbildung 25 - Übersicht der inkonsistenten deliverydatepromised Werte der Trainingsmenge
Eine Korrektur auf das Jahr 2008 ist dementsprechend nicht sinnvoll. Somit werden die
Jahresangaben der deliverydatepromised Werte auf das nächsthöhere Jahr 2009
korrigiert, da es der durchschnittlichen Abweichung von zugesagtem und tatsächlichem
Lieferdatum am nächsten kommt. Analog wird dieser Vorgang für die entsprechenden
Instanzen der Testmenge durchgeführt, die dieselben Eigenschaften aufweisen.
deliverydatereal
Das Merkmal deliverydatereal steht für das tatsächliche Lieferdatum der bestellten
Artikel. Es liegen Gemeinsamkeiten bei allen Instanzen vor, die inkonsistente
deliverydatereal-Werte beinhalten. Entweder ist in der Bestellung ein
heruntergeladenes Hörbuch (w5), ein eBook (w3) oder ein sonstiger Artikel (w10)
enthalten. Liegt keiner dieser Artikel vor, wurden Artikel storniert.
Daraus wird folgende Hypothese abgeleitet: Das tatsächliche Lieferdatum wird nicht
korrekt erfasst, wenn die bestellten Artikel heruntergeladen oder auf anderen
elektronischen Wegen bezogen werden.
Zunächst werden die Instanzen betrachtet, bei denen das Merkmal w5 mindestens den
Wert 1 aufweist. Bei diesen Instanzen wird für die Merkmale deliverydatereal und w5
eine statistische Übersicht erstellt (vgl. Abb. 26).

Empirischer Teil 77
Abbildung 26 - Anzahl unterschiedlicher Werte des Merkmals deliverydatereal
Der inkorrekte Wert tritt in 4392 der untersuchten Beispiele auf, nur in einem Fall liegt
ein korrektes Datum vor. Bei einer Bestellung von eBooks (w3) liegen ausschließlich
inkorrekte Datumsangaben vor.
Die sonstigen Artikel werden bei den betroffenen Instanzen mit hoher
Wahrscheinlichkeit ebenfalls Produkte sein, die auf elektronischem Weg bezogen
werden (z.B. Musikdateien, Computerspiele oder Filme), so dass deren tatsächliches
Lieferdatum von der Software ebenfalls nicht erfasst wird. Die sonstigen Artikel machen
im Vergleich zu den heruntergeladenen Hörbüchern und eBooks einen kleinen Teil aus
(228 inkorrekte Datumsangaben).
Die restlichen Bestellungen mit inkorrektem deliverydatereal-Wert enthalten wie
erläutert stornierte Artikel. Für das Entstehen der inkorrekten deliverydatereal-Werte
bei stornierten Artikeln existieren zwei naheliegende Erklärungsmöglichkeiten.
Entweder entsteht der inkorrekte Lieferzeitpunkt dadurch, dass stornierte Artikel nicht
ausgeliefert werden und die Software diesem Sachverhalt keinen korrekten
Lieferzeitpunkt zuordnet oder es handelt sich bei den stornierten Artikeln wiederum um
Artikel, die auf elektronischem Weg bezogen werden.
Es werden somit beispielhaft alle Instanzen der Trainingsmenge untersucht, deren
Merkmale numberitems und cancel den Wert 1 haben. Bei diesen Beispielen wird nur
ein Artikel bestellt, der anschließend storniert wird. In Abb. 27 ist zu erkennen, dass nur
in 399 von 888 Fällen ein inkorrektes Lieferdatum vorliegt.

Empirischer Teil 78
Abbildung 27 - Untersuchung stornierter Artikel
Somit ist nicht der Sachverhalt der Stornierung des Artikels für den inkorrekten
Lieferzeitpunkt verantwortlich.
Die aufgestellte Hypothese wird somit bestätigt. Für alle Artikel, die heruntergeladen
oder auf anderen elektronischen Wegen bezogen werden, wird kein korrektes
tatsächliches Lieferdatum erfasst.
Es ist zu ermitteln, durch welche Werte die inkorrekten Werte ersetzt werden. Eine
Option besteht darin, die Lieferzeit bei diesen Artikeln auf null Tage zu setzen, da diese
Artikel in der Regel sofort verfügbar sind und entweder heruntergeladen oder per Mail
verschickt werden. Da aber in einigen Shops zwischen Bestellung und Verfügbarkeit
dieser Artikel durch Verwaltungsprozesse Zeit vergeht und zudem je nach Bestellung
weitere Artikel in den betroffenen Bestellungen enthalten sind, wird eine Analyse der
übrigen Bestellungen vorgenommen. Die übrigen Bestellungen werden in Bezug auf die
tatsächlich erreichten Lieferzeiten und die Zeitspanne zwischen zugesagtem und
tatsächlichem Lieferdatum untersucht. Im Anschluss an die Analyse wird unter
Beachtung der besonderen Eigenschaften der Artikel eine sinnvolle Lösung ermittelt.
Als Referenzattribute werden date und deliverydatepromised untersucht. Es werden
über den Time Difference-Knoten für die gefilterten korrekten Instanzen jeweils die
Zeitabstände in Tagen von deliverydatereal zu date und zu deliverydatepromised
ermittelt. Anschließend findet eine statistische Auswertung dieser Zeitabstände statt
(vgl. Abb. 28).
Anhand der statistischen Auswertung ist zu erkennen, dass sowohl die
Standardabweichung als auch die Varianz beim Abstand von zugesagtem zu
tatsächlichem Lieferzeitpunkt deutlich höher ausfallen als bei der tatsächlichen
Lieferzeit. Auch das Intervall der Werte ist in dieser Spalte deutlich größer ([−369|368]
zu [0|584]). Diese Gesichtspunkte sprechen dafür, die tatsächliche Lieferzeit als
Anhaltspunkt für das Ersetzen der inkorrekten Werte zu benutzen.
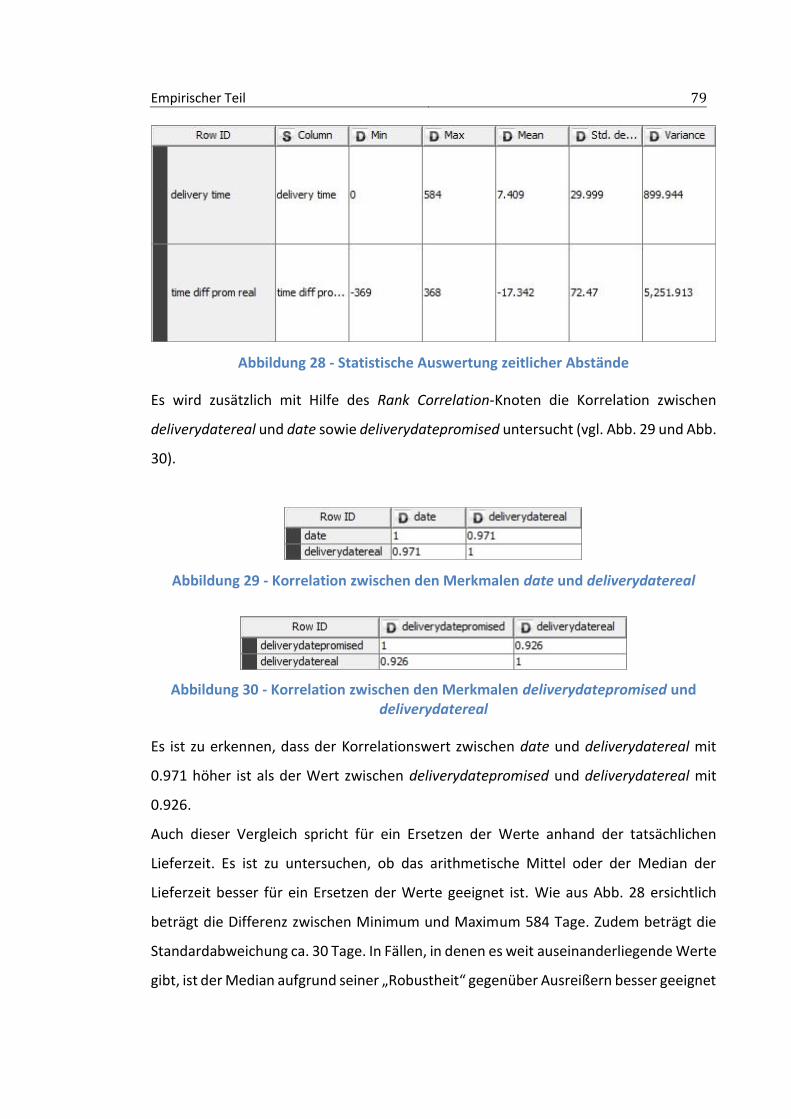
Empirischer Teil 79
Abbildung 28 - Statistische Auswertung zeitlicher Abstände
Es wird zusätzlich mit Hilfe des Rank Correlation-Knoten die Korrelation zwischen
deliverydatereal und date sowie deliverydatepromised untersucht (vgl. Abb. 29 und Abb.
30).
Abbildung 29 - Korrelation zwischen den Merkmalen date und deliverydatereal
Abbildung 30 - Korrelation zwischen den Merkmalen deliverydatepromised und deliverydatereal
Es ist zu erkennen, dass der Korrelationswert zwischen date und deliverydatereal mit
0.971 höher ist als der Wert zwischen deliverydatepromised und deliverydatereal mit
0.926.
Auch dieser Vergleich spricht für ein Ersetzen der Werte anhand der tatsächlichen
Lieferzeit. Es ist zu untersuchen, ob das arithmetische Mittel oder der Median der
Lieferzeit besser für ein Ersetzen der Werte geeignet ist. Wie aus Abb. 28 ersichtlich
beträgt die Differenz zwischen Minimum und Maximum 584 Tage. Zudem beträgt die
Standardabweichung ca. 30 Tage. In Fällen, in denen es weit auseinanderliegende Werte
gibt, ist der Median aufgrund seiner „Robustheit“ gegenüber Ausreißern besser geeignet

Empirischer Teil 80
(vgl. Bankhofer, Vogel 2008, S. 30). Der Median der tatsächlichen Lieferzeit wird anhand
des Statistics-Knotens ermittelt und beträgt einen Tag.
Wie zuvor beschrieben, handelt es sich um Artikel, die auf elektronischem Weg bezogen
werden und für die von einer besonders geringen Lieferzeit auszugehen ist. Eine
Lieferzeit von einem Tag erscheint aufgrund von möglichen Verzögerungen durch
Organisationsprozesse sowie die Lieferzeit eventuell anderer in der Bestellung
enthaltener Artikel realistisch.
Damit wird der Median der tatsächlichen Lieferzeit als Richtwert übernommen. Somit
wird für jede der betroffenen Instanzen ein Tag auf das den Wert des Merkmals date
addiert, um die Werte für das Merkmal deliverydatereal zu ersetzen. In KNIME wird das
Ersetzen der Werte durch eine Schleife über alle inkorrekten Werte erreicht (vgl. Abb.
31). Dieser Vorgang wird für die Trainings- und Testmenge durchgeführt.
Abbildung 31 - Ersetzen der inkorrekten deliverydatereal-Werte
3.2.3 Datentransformation
Im Datentransformationsprozess der vorliegenden Arbeit werden
Datentypkonvertierungen, Normierungen und die Erstellung neuer Attribute
durchgeführt.

Empirischer Teil 81
Datentypkonvertierung
Wie bereits in der Datenerhebung erwähnt, werden einige Attribute in einen anderen
Datentyp umgewandelt, um eine Weiterverarbeitung und einen Vergleich zu
erleichtern. Bei folgenden Attributen wird eine Konvertierung des Datentyps
vorgenommen:
String to Date: date, datecreated, deliverydatepromised, deliverydatereal
Integer to String: target90
String to Integer: advertisingdatacode
Die Umwandlung der Datumsangaben in das Date-Format ermöglicht eine Benutzung
der zahlreichen Knoten, die auf eine Weiterverarbeitung von Datumsangaben
spezialisiert sind, wie beispielsweise Date Field Extractor, Time Difference und
Date/Time Shift.
Das Klassifikationsmerkmal target90 wird in das Format String umgewandelt, da die
meisten Klassifikatoren dieses Format zum Lernen ihres Modells benötigen.
Die Konvertierung des Merkmals advertisingdatacode wird im Rahmen der Behandlung
der fehlenden Werte unter 3.2.1 beschrieben.
Normierung
Einige Klassifikatoren benötigen als Eingabedaten normierte Werte. In der vorliegenden
Arbeit sind das die Support Vector Machine und das neuronale Netz. Der 𝑘-Nächster-
Nachbar-Klassifikator arbeitet sowohl mit nicht normierten als auch mit normierten
Attributwerten. Damit das gewählte Abstandsmaß des 𝑘-Nächster-Nachbar-
Klassifikator nicht unterschiedlich stark durch die verschiedenen Maßeinheiten und
Wertebereiche der Attribute beeinflusst wird, werden auch für diesen Klassifikator
normierte Daten verwendet. Als Normierungsfunktion wird die Min-Max-Normierung
im Intervall [0|1] verwendet.
Zusätzlich benötigen zwei Verfahren zur Prädiktorenselektion eine Normierung der
Eingabedaten. Sowohl die Hauptkomponentenanalyse als auch das Verfahren zur

Empirischer Teil 82
Bestimmung der Korrelationskoeffizienten erzielen bessere Ergebnisse mit normierten
Werten.
Es ist zu beachten, dass der Normalizer-Knoten in KNIME ausschließlich numerische
Werte normiert.
Konstruktion neuer Attribute
Die neu konstruierten Attribute werden anhand heuristischer Kriterien erstellt. Die neu
erstellten Attribute sind (vgl. Levatic, Malenica, Pavlic 2010, S. 4):
year: Extraktion des Jahres des Merkmals deliverydatereal
time diff: Zeitabstand zwischen zugesagtem und tatsächlichem Lieferzeitpunkt
items effective: Anzahl der bestellten Artikel ohne zurückgeschickte und stornierte Artikel
deliverytime absolute: Tatsächliche Lieferzeit der Bestellungen
x-mas: Das Merkmal x-mas beschreibt die Nähe der Bestellung zu Weihnachten in Tagen
Das Merkmal year wurde zunächst extrahiert, um eine Weiterverarbeitung und
Korrektur der Daten zu vereinfachen. Es blieb dann als Merkmal erhalten, um zu
untersuchen, ob sich das Kundenverhalten je nach Lieferjahr unterscheidet. Zudem
besitzt year das Format Integer, so dass dieses Merkmal von allen Verfahren verarbeitet
wird, die keine Date-Formate zulassen (künstliches neuronales Netz, Support Vector
Machine, Naive Bayes). Dieser Vorteil besteht auch bei den im Folgenden erläuterten
Merkmalen time diff und deliverytime absolute.
Das Merkmal time diff wird konstruiert, da von einer stärkeren Unzufriedenheit des
Kunden auszugehen ist, je weiter zugesagtes und tatsächliches Lieferdatum
auseinanderliegen.
Das Merkmal items effective wird erstellt, da durchschnittlich von einer höheren
Kundenzufriedenheit und damit einer höheren Wahrscheinlichkeit einer
Folgebestellung ausgegangen wird, je weniger Artikel zurückgesendet oder storniert
werden. Selbstverständlich gibt es Ausnahmen, wenn beispielsweise aus Versehen ein

Empirischer Teil 83
falscher Artikel bestellt wird und eine Folgebestellung mit dem richtigen Artikel erfolgt.
In Bezug auf alle Bestellungen gesehen, ist eine derartige Hypothese aber sinnvoll.
Das Merkmal deliverytime absolute wird aus ähnlichen Gründen wie das Merkmal time
diff erstellt. Je länger die Lieferzeit eines Artikels dauert, desto unzufriedener ist der
durchschnittliche Kunde. Es ist davon auszugehen, dass die Aussagekraft dieses
Merkmals verglichen mit dem Merkmal time diff geringer ist, da der Kunde bei
Vorbestellungen oder bei Bestellungen von schwer erhältlichen Produkten im Vorfeld
über die lange Lieferzeit informiert ist.
Das Merkmal x-mas wird eingeführt, um die Nähe der Bestellung zu Weihnachten zu
ermitteln. Es kommt häufig vor, dass kurz vor oder direkt nach einem Feiertag (falls ein
Geschenk vergessen wurde) Geschenke in Online-Shops gekauft werden. Es ist möglich,
dass der Online-Shop, bei dem bestellt wird, nur wegen der Verfügbarkeit oder der
geringen Lieferzeit des gesuchten Geschenks ausgesucht wird. In diesen Fällen ist die
Kundentreue zum Online-Shop nicht sehr hoch. Somit ist es interessant, wie sich die
zeitliche Nähe der Bestellung zu Weihnachten auf die Wahrscheinlichkeit einer
Folgebestellung auswirkt.
Es ist zu beachten, dass das Merkmal gift bereits existiert. Dieses Merkmal beschreibt
aber nur, ob die Geschenkoption ausgewählt wird. Es ist davon auszugehen, dass die
Geschenkoption wie in Online-Shops üblich eine Geschenkverpackung beinhaltet und
die Rechnung an den Besteller und nicht den Beschenkten gesendet wird.
Darüber hinaus sind Fälle denkbar, in denen sich der Kunde Artikel nach Hause liefern
lässt, die anschließend individuell verpackt werden. Damit diese Fälle nicht
unberücksichtigt bleiben, wird zusätzlich das Merkmal x-mas eingeführt.
Es wird nur die Nähe zu Weihnachten und nicht zu anderen Feiertagen untersucht.
Ostern kommt aufgrund des Bestellzeitraums (01.04.2008 bis 31.03.2009) nicht in
Betracht. Es ist nicht bekannt, aus welchem Land die für diese Aufgabe zur Verfügung
gestellten Daten stammen. Somit ist es nicht möglich, weitere Feiertage zu ermitteln, an
denen Geschenke gekauft werden.

Empirischer Teil 84
3.3 Modellierung und Evaluation
In diesem Prozessschritt werden die unter 2.5 erläuterten Verfahren auf die konkreten
Datensätze angewendet. Es werden zunächst die für die Modelle in KNIME
vorkonfigurierten Parametereinstellungen benutzt.
Die Ergebnisse der Modelle werden wie bereits beschrieben, anhand der Kostenmatrix
aus 2.6.2 verglichen. Das Ziel ist nicht die Optimierung der Klassifikationsgenauigkeit,
sondern das Erreichen einer möglichst hohen Umsatzsteigerung. Die Kostenmatrix wird
mit Hilfe eines Java Snippet-Knoten erstellt (vgl. Abb. 32).
Abbildung 32 - Java Snippet zur Erstellung der Kostenmatrix
Der gesamte Umsatz wird dann durch einen GroupBy-Knoten ermittelt, der die Summe
der Umsätze pro Bestellung auf die neue Spalte sum(revenue) abbildet.
Als Referenzgröße wird der Basisumsatz ermittelt, der erzielt wird, wenn allen Kunden
ein Gutschein geschickt wird.
Die Testmenge enthält 6.168 Bestellungen mit der Klasse 1 und 26.259 Bestellungen mit
der Klasse 0. Somit lässt sich der Basisumsatz ermitteln als:
Basisumsatz = 6.168 ∙ (−5) + 26.259 ∙ 1,5 = 8.548,5
(29)
Ohne den Einsatz von Data Mining-Verfahren lässt sich damit durch das Versenden der
Gutscheine an alle Kunden der Testmenge ein automatischer Profit von 8548.5 Euro
erzielen.

Empirischer Teil 85
Wie unter 3.1 beschrieben, ist die Trainingsmenge hinsichtlich des
Klassifikationsmerkmals sehr ungleich verteilt. Somit werden zu Beginn die Ergebnisse,
die mit der unveränderten Trainingsmenge erzielt werden mit Ergebnissen einer
gleichverteilten Trainingsmenge verglichen. Mit diesem Vorgehen wird ermittelt, ob die
Ergebnisse durch die ungleiche Verteilung verzerrt werden. Im Anschluss an diesen
Schritt wird untersucht, wie sich die Verfahren zur Selektion der Parameter auf die
Kostenmatrix auswirken. Wenn die Ergebnisse dieser Schritte vorliegen, werden die
vielversprechendsten Modelle weiter optimiert, indem eine systematische
Parameteranalyse durchgeführt wird. Die systematische Parameteranalyse wird mit den
Verfahren durchgeführt, die vor einer Parameteroptimierung die besten Ergebnisse
erzielen, da dieses Verfahren sehr zeitintensiv ist und abhängig vom Modell mehrere
Stunden in Anspruch nimmt.
3.3.1 Bestimmung der Trainingsmenge
Es werden zu Beginn alle Verfahren mit der vollständigen Trainingsmenge und der
Trainingsmenge unter vorheriger Verwendung des Equal Size Sampling-Knotens
verwendet. Dieser Knoten verwendet die Under-Sampling-Methode, so dass zufällig
Instanzen mit der Klasse 0 gelöscht werden, bis eine Gleichverteilung der Klassen
vorliegt.
Diese Vorgehensweise zielt darauf ab, eine erste Einschätzung über den Einfluss der
ungleichen Klassenverteilung zu gewinnen. Zudem wird ein erster Überblick über die
Modellgüte der Verfahren gewonnen.
Der Equal Size Sampling-Knoten wird mit der Option static seed (Startwert) verwendet.
Mit diesem Wert wird ein Zufallszahlengenerator initialisiert, der eine Folge von
Pseudozufallszahlen generiert. Diese Folge von Zufallszahlen lässt sich reproduzieren.
Somit werden bei erneuter Ausführung des Knotens die identischen Instanzen entfernt.
Durch dieses Vorgehen wird eine bessere Vergleichbarkeit der Verfahren ermöglicht und
Testdurchläufe lassen sich wiederholen.
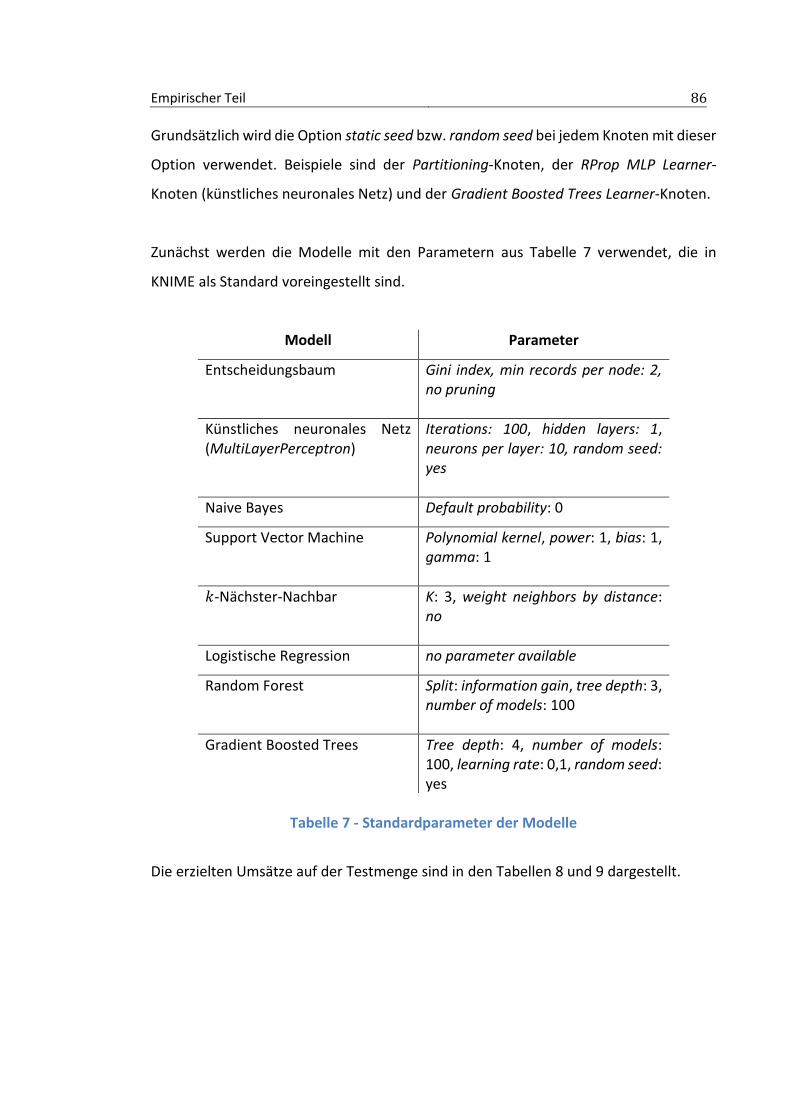
Empirischer Teil 86
Grundsätzlich wird die Option static seed bzw. random seed bei jedem Knoten mit dieser
Option verwendet. Beispiele sind der Partitioning-Knoten, der RProp MLP Learner-
Knoten (künstliches neuronales Netz) und der Gradient Boosted Trees Learner-Knoten.
Zunächst werden die Modelle mit den Parametern aus Tabelle 7 verwendet, die in
KNIME als Standard voreingestellt sind.
Modell Parameter
Entscheidungsbaum Gini index, min records per node: 2, no pruning
Künstliches neuronales Netz (MultiLayerPerceptron)
Iterations: 100, hidden layers: 1, neurons per layer: 10, random seed: yes
Naive Bayes Default probability: 0
Support Vector Machine Polynomial kernel, power: 1, bias: 1, gamma: 1
𝑘-Nächster-Nachbar K: 3, weight neighbors by distance: no
Logistische Regression no parameter available
Random Forest Split: information gain, tree depth: 3, number of models: 100
Gradient Boosted Trees Tree depth: 4, number of models: 100, learning rate: 0,1, random seed: yes
Tabelle 7 - Standardparameter der Modelle
Die erzielten Umsätze auf der Testmenge sind in den Tabellen 8 und 9 dargestellt.

Empirischer Teil 87
Unveränderte Trainingsmenge
Modell Umsatz in €
Entscheidungsbaum 8.906,5
Künstliches neuronales Netz (MultiLayerPerceptron)
8.779
Naive Bayes 10.449,5
Support Vector Machine 8.548,5
𝑘-Nächster-Nachbar 8.533,5
Logistische Regression 8.615,5
Random Forest 8.548,5
Gradient Boosted Trees 8.829,5
Tabelle 8 - Erzielte Umsätze auf den Testdaten mit vollständiger Trainingsmenge
Trainingsmenge nach Anwendung des Equal Size Sampling
Modell Umsatz in €
Entscheidungsbaum 7.301,5
Künstliches neuronales Netz (MultiLayerPerceptron)
10.821,5
Naive Bayes 9.160
Support Vector Machine 10.584
𝑘-Nächster-Nachbar 6.848,5
Logistische Regression 10.705
Random Forest 11.070
Gradient Boosted Trees 11.585
Tabelle 9 - Erzielte Umsätze auf den Testdaten nach Anwendung von Equal Size
Sampling

Empirischer Teil 88
Es ist zu erkennen, dass die Ergebnisse nach dem Sampling der Trainingsmenge im
Durchschnitt deutlich besser ausfallen, als bei Verwendung der vollständigen
Trainingsmenge. Die Klassifikatoren Entscheidungsbaum, Naive Bayes und 𝑘-Nächster-
Nachbar erzielen ohne ein Sampling bessere Ergebnisse. Allerdings liegen die erzielten
Ergebnisse deutlich unter den Umsätzen der besten Modelle nach Anwendung von
Equal Size Sampling. Es ist zu erkennen, dass durch die hohe Anzahl der Instanzen mit
der Klasse 0 bei einigen Modellen eine Verzerrung der Lernalgorithmen stattfindet. Es
wird vielen Objekten der Klasse 1 fälschlicherweise die Klasse 0 zugewiesen. Sehr
deutlich ist das bei der Support Vector Machine und dem Random Forest zu erkennen,
die jedem Kunden einen Gutschein zuschicken (vgl. Abb. 33).
Abbildung 33 - Konfusionsmatrix des Random Forest-Modells bei unveränderter Trainingsmenge
Nach dieser Erkenntnis werden weitere Sampling-Strategien getestet. Es wird sowohl
Over- als auch Under-Sampling verwendet. Beim Over-Sampling wird vorwiegend der
Bootstrap Sampling-Knoten verwendet. Es ist durch erste Tests zu beobachten, dass die
Ergebnisse der Under-Sampling-Verfahren deutlich bessere Resultate liefern, weshalb
weiter in diese Richtung getestet wird.
Das Under-Sampling wird mit Hilfe der Knoten Row Splitter, Partitioning und
Concatenate durchgeführt (vgl. Abb. 34).
Es werden zur Annäherung an das optimale Klassenverhältnis Trainingsmengen mit
folgenden Verhältnissen (Klasse 0: Klasse 1) getestet: 1,25:1; 1,5:1; 1,75:1; 2:1.
Die Tests mit den unterschiedlichen Klassenverhältnissen finden zunächst ausschließlich
anhand der Trainingsmenge statt, um ein Overfitting in Bezug auf die Testdaten zu
vermeiden. Die Trainingsmenge wird prozentual in zwei Untermengen aufgeteilt, so
dass eine Partition der Trainingsmenge als tatsächliche Trainingsmenge genutzt wird
und die andere Partition als Testmenge.

Empirischer Teil 89
Abbildung 34 - Under-Sampling zur Reduktion der ungleichen Verteilung der Klassen
Wie bereits erläutert, existiert keine allgemeingültige Vorschrift zur optimalen
Aufteilung der Partitionen. Anhand heuristischer Gesichtspunkte werden zumeist
Mengen im Verhältnis 70/30 bis zu 50/50 gewählt (vgl. Bipartitionierung in Kapitel
2.6.3). Durch Voruntersuchungen wird ermittelt, dass eine prozentuale Aufteilung von
60/40 die aussagekräftigsten Ergebnisse liefert. Somit werden 60 % der Instanzen der
Trainingsmenge zum Trainieren und 40 % zum Testen verwendet.
Die besten Ergebnisse dieser Auswahl werden mit einer Aufteilung im Verhältnis 1,5:1
mit dem Gradient Boosted Trees-Verfahren erzielt. Anschließende Versuche, die das
Verhältnis feingranularer (in Schritten von 0,1) untersuchen, erzielen keine besseren
Ergebnisse. Somit wird das Verhältnis von 1,5:1 übernommen und anschließend auf die
Testdaten angewendet.
Ein Überblick über den erzielten Umsatz auf den Testdaten ist in Tabelle 10 dargestellt.

Empirischer Teil 90
Trainingsmenge mit dem Klassenverhältnis 1,5:1
Modell Umsatz in €
Entscheidungsbaum 7.738
Künstliches neuronales Netz (MultiLayerPerceptron)
11.458
Naive Bayes 10.076
Support Vector Machine 8.994
𝑘-Nächster-Nachbar 7.770
Logistische Regression 10.461,5
Random Forest 8.683
Gradient Boosted Trees 12.100,5
Tabelle 10 - Erzielte Umsätze mit einem Verhältnis von 1,5:1 (Klasse 0: Klasse 1)
Es ist zu erkennen, dass die Modelle Gradient Boosted Trees und das neuronale Netz mit
Abstand die besten Ergebnisse erzielen. Es gibt auch Modelle, die im Vergleich zum
Equal Size Sampling schlechter abschneiden. Besonders prägnant ist die
Verschlechterung des Ergebnisses beim Random Forest-Verfahren. Es wird deutlich,
dass dieses Verfahren starke Probleme mit der Verarbeitung ungleich verteilter
Trainingsmengen hat.
Da die Zielsetzung darin besteht, mit einem ausgewählten Modell einen möglichst
hohen Umsatz zu erreichen und nicht für viele Verfahren ein optimales Ergebnis zu
erzielen, werden die Ressourcen in eine Verbesserung der bis dato besten Verfahren
investiert.
Die Verfahren, die anhand ihrer Resultate hervorstechen sind Gradient Boosted Trees,
neuronales Netz und Random Forest.
Die Random Forest-Methode wird aufgrund der guten Resultate in weiteren Versuchen
mit der Trainingsmenge getestet, die durch das Equal Size Sampling generiert wird. Das

Empirischer Teil 91
Gradient Boosted Trees-Verfahren und das Random Forest-Verfahren werden mit der
Trainingsmenge mit dem Klassenverhältnis 1,5:1 weitergehend analysiert.
Diese Verfahren besitzen zugleich eine höhere Anzahl an Parametern als die meisten
anderen Verfahren, so dass in Bezug auf die Parameteroptimierung vielfältigere
Möglichkeiten existieren.
3.3.2 Selektion der Prädiktoren
Es wird untersucht, ob eine Selektion der Prädiktoren zu besseren Ergebnissen führt als
die Modellbildung unter Berücksichtigung aller Merkmale. Es liegen einschließlich der
konstruierten Merkmale 40 Prädiktoren vor (ohne target90), so dass der relative Anteil
der Merkmale in Bezug auf die Anzahl der Instanzen der Trainingsmenge 0,1 % beträgt.
Es besteht somit aufgrund der Anzahl der Prädiktoren keine Notwendigkeit zur
Reduktion. Auch die Zeitspannen, die die einzelnen Verfahren zur Modellbildung
benötigen, rechtfertigen keine Reduktion der Prädiktoren. Die Zeitspannen bewegen
sich im Bereich von unter einer Minute bis zu wenigen Minuten.
Somit ist ausschlaggebend, ob durch eine Reduktion der Attribute eine Verbesserung
der Modellgüte oder zumindest eine gleichwertige Modellgüte erreicht wird.
Korrelationskoeffizient
Zunächst wird über den Column Splitter-Knoten das Klassifikationsmerkmal target90
herausgefiltert, so dass die Korrelationskoeffizienten für jedes verbleibende
Merkmalspaar bestimmt werden. Somit werden stark korrelierende und damit
redundante Merkmale ermittelt, die anschließend mit Hilfe des Correlation Filter-
Knotens herausgefiltert werden. Der Correlation Filter-Knoten bietet die Option, einen
Schwellenwert für die Korrelation (engl. correlation threshold) im Wertebereich 0 bis 1
zu bestimmen. Je kleiner der Wert, desto mehr Merkmale werden gefiltert. Bei der

Empirischer Teil 92
Auswahl der zu entfernenden Merkmale berücksichtigt der Correlation Filter-Knoten
darüber hinaus die Abhängigkeiten und Zusammenhänge zu den übrigen Knoten.
Der Linear Correlation-Knoten erstellt zudem eine Korrelationsmatrix, die die
Abhängigkeiten unter den Merkmalen graphisch darstellt (vgl. Abb. 35).
Abbildung 35 - Korrelationsmatrix der Prädiktoren
Die höchste Korrelation besteht zwischen den folgenden Merkmalen:
numberitems und items effective (0,95)
model und entry (0,9)

Empirischer Teil 93
numberitems und weight (0,76)
weight und items effective (0,72)
year und deliverytime absolute (0,5)
case und numberitems (0,43)
Die hohe Korrelation zwischen den Merkmalen numberitems und items effective ist
damit zu erklären, dass der Anteil an zurückgeschickten und stornierten Artikeln im
Vergleich zur Gesamtanzahl an bestellten Artikeln gering ist. Somit besteht eine hohe
Ähnlichkeit der Werte. Die Korrelation zwischen model und entry ist nicht herzuleiten,
da das Merkmal model in der Aufgabenstellung nicht näher spezifiziert wird. Die
Korrelation zwischen weight und numberitems sowie items effective ist evident. Es
besteht zudem ein Zusammenhang zwischen year und deliverytime absolute. Ein
Großteil der Bestellungen wurde im Jahr 2008 aufgegeben. Somit haben Bestellungen,
die 2009 und 2010 geliefert werden (das Merkmal year bezieht sich auf den
tatsächlichen Lieferzeitpunkt), im Durchschnitt eine höhere Lieferzeit als Bestellungen,
die den Kunden im Jahr 2008 erreichen.
Die Korrelation zwischen case und numberitems erklärt sich dadurch, dass der
durchschnittliche Warenwert zunimmt, je höher die Anzahl der bestellten Artikel
ausfällt.
Durch erste Tests anhand der partitionierten Trainingsmenge wird ermittelt, dass sich
die besten Ergebnisse mit einem Wertebereich von 0,5 - 0,9 für den correlation
threshold (im Folgenden: ct) ergeben. Diese Werte werden übernommen und in Bezug
auf die Testmenge untersucht, wobei sich die Ergebnisse aus den Voruntersuchungen
bestätigen (vgl. Tabelle 11).
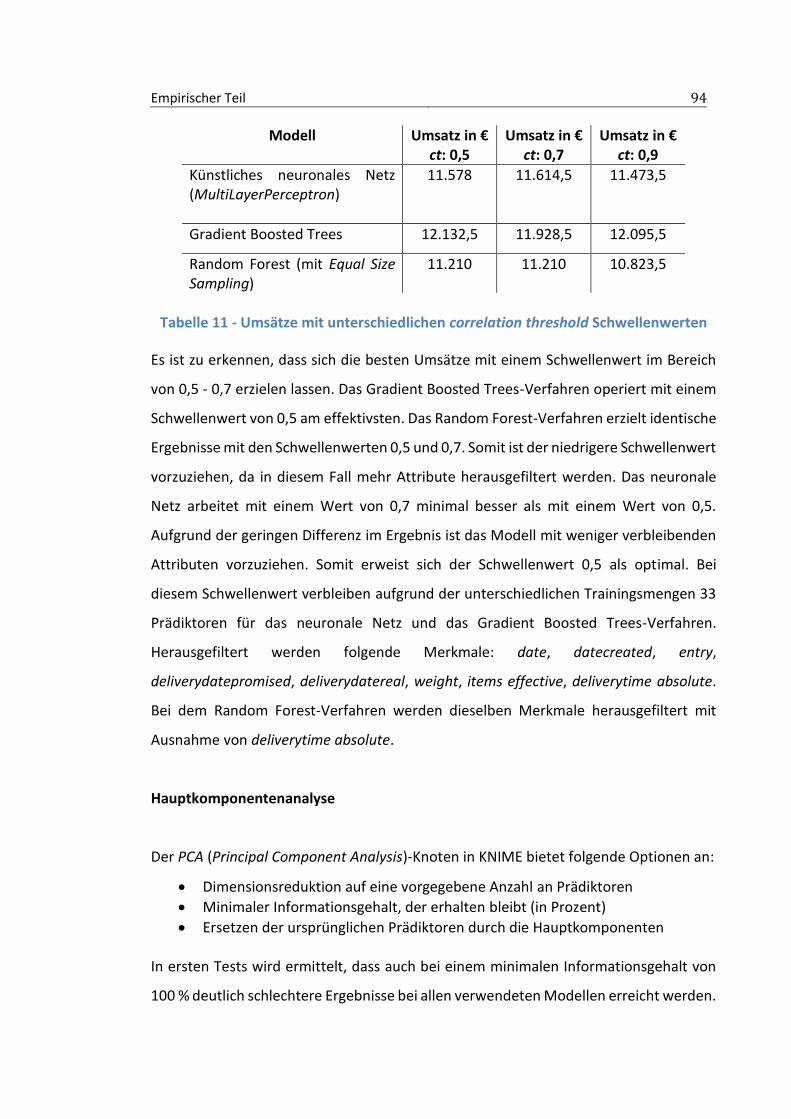
Empirischer Teil 94
Modell Umsatz in € ct: 0,5
Umsatz in € ct: 0,7
Umsatz in € ct: 0,9
Künstliches neuronales Netz (MultiLayerPerceptron)
11.578 11.614,5 11.473,5
Gradient Boosted Trees 12.132,5 11.928,5 12.095,5
Random Forest (mit Equal Size Sampling)
11.210 11.210 10.823,5
Tabelle 11 - Umsätze mit unterschiedlichen correlation threshold Schwellenwerten
Es ist zu erkennen, dass sich die besten Umsätze mit einem Schwellenwert im Bereich
von 0,5 - 0,7 erzielen lassen. Das Gradient Boosted Trees-Verfahren operiert mit einem
Schwellenwert von 0,5 am effektivsten. Das Random Forest-Verfahren erzielt identische
Ergebnisse mit den Schwellenwerten 0,5 und 0,7. Somit ist der niedrigere Schwellenwert
vorzuziehen, da in diesem Fall mehr Attribute herausgefiltert werden. Das neuronale
Netz arbeitet mit einem Wert von 0,7 minimal besser als mit einem Wert von 0,5.
Aufgrund der geringen Differenz im Ergebnis ist das Modell mit weniger verbleibenden
Attributen vorzuziehen. Somit erweist sich der Schwellenwert 0,5 als optimal. Bei
diesem Schwellenwert verbleiben aufgrund der unterschiedlichen Trainingsmengen 33
Prädiktoren für das neuronale Netz und das Gradient Boosted Trees-Verfahren.
Herausgefiltert werden folgende Merkmale: date, datecreated, entry,
deliverydatepromised, deliverydatereal, weight, items effective, deliverytime absolute.
Bei dem Random Forest-Verfahren werden dieselben Merkmale herausgefiltert mit
Ausnahme von deliverytime absolute.
Hauptkomponentenanalyse
Der PCA (Principal Component Analysis)-Knoten in KNIME bietet folgende Optionen an:
Dimensionsreduktion auf eine vorgegebene Anzahl an Prädiktoren
Minimaler Informationsgehalt, der erhalten bleibt (in Prozent)
Ersetzen der ursprünglichen Prädiktoren durch die Hauptkomponenten In ersten Tests wird ermittelt, dass auch bei einem minimalen Informationsgehalt von
100 % deutlich schlechtere Ergebnisse bei allen verwendeten Modellen erreicht werden.

Empirischer Teil 95
Ein Ersetzen der ursprünglichen Prädiktoren erzielt auch keine Verbesserung. Somit wird
die Hauptkomponentenanalyse nicht tiefergehend untersucht.
Rückwärtsselektion
Die Rückwärtsselektion wird anhand des Backward Feature Elimination-Knoten
durchgeführt, der für die Eliminierung der Attribute das Naive Bayes-Modell verwendet
(vgl. Abb. 36).
Es wird kein Abbruchkriterium vorgegeben, sondern erst das Ergebnis der Auswertung
abgewartet. Ein Ausschnitt der Resultate der Rückwärtsselektion der Trainingsmenge
mit 1,5:1 Klassenverteilung ist in Abb. 37 dargestellt. Die Rückwärtsselektion mit der
Trainingsmenge nach dem Equal Size Sampling, die für das Random Forest-Verfahren
benutzt wird, erzielt ein davon abweichendes Ergebnis.
Mit Hilfe des Backward Feature Elimination Filter-Knotens werden anhand manueller
Selektion oder anhand des prediction error threshold (Schwellenwert des
Prognosefehlers) die irrelevanten Prädiktoren herausgefiltert. Wiederum werden
zunächst Versuche anhand der partitionierten Trainingsmenge durchgeführt.
Abbildung 36 - Backward Feature Elimination
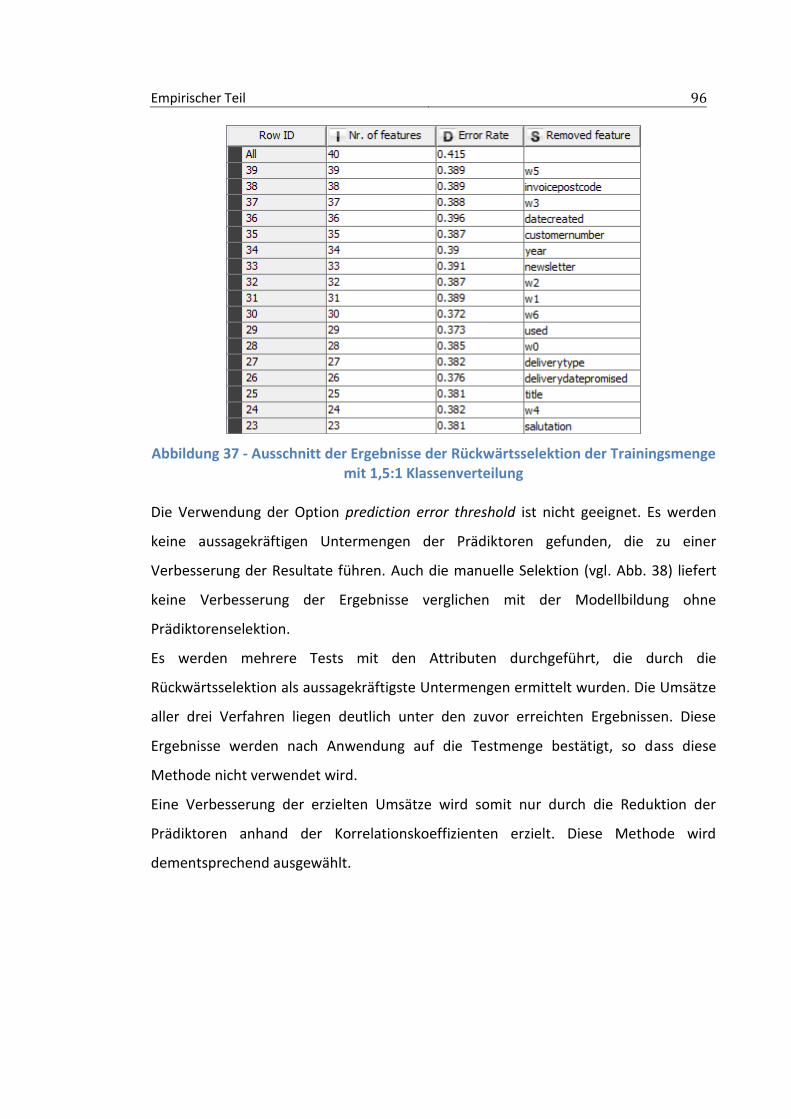
Empirischer Teil 96
Abbildung 37 - Ausschnitt der Ergebnisse der Rückwärtsselektion der Trainingsmenge mit 1,5:1 Klassenverteilung
Die Verwendung der Option prediction error threshold ist nicht geeignet. Es werden
keine aussagekräftigen Untermengen der Prädiktoren gefunden, die zu einer
Verbesserung der Resultate führen. Auch die manuelle Selektion (vgl. Abb. 38) liefert
keine Verbesserung der Ergebnisse verglichen mit der Modellbildung ohne
Prädiktorenselektion.
Es werden mehrere Tests mit den Attributen durchgeführt, die durch die
Rückwärtsselektion als aussagekräftigste Untermengen ermittelt wurden. Die Umsätze
aller drei Verfahren liegen deutlich unter den zuvor erreichten Ergebnissen. Diese
Ergebnisse werden nach Anwendung auf die Testmenge bestätigt, so dass diese
Methode nicht verwendet wird.
Eine Verbesserung der erzielten Umsätze wird somit nur durch die Reduktion der
Prädiktoren anhand der Korrelationskoeffizienten erzielt. Diese Methode wird
dementsprechend ausgewählt.

Empirischer Teil 97
Abbildung 38 - Backward Feature Elimination Filter mit manueller Selektion
3.3.3 Parameteroptimierung
Es wird für jedes der drei verbleibenden Modelle eine systematische Optimierung der
Parameter vorgenommen. Zunächst werden Voruntersuchungen durchgeführt, um
interessante Wertebereiche der einzelnen Parameter zu ermitteln. Anschließend
werden die Parameter über Schleifendurchläufe systematisch getestet (vgl. Abb. 39).

Empirischer Teil 98
Abbildung 39 - Schleife zur Parameteroptimierung
Über den Parameter Optimization Loop Start-Knoten werden die zu untersuchenden
Parameterwerte bestimmt (vgl. Abb. 40).
Abbildung 40 - Parameterselektion MultiLayerPerceptron
Die entsprechend zu testenden Parameter werden in den Modellbildungsknoten der
Verfahren als sogenannte Flow Variables (dynamische Variablen) deklariert (vgl. Abb.
41).
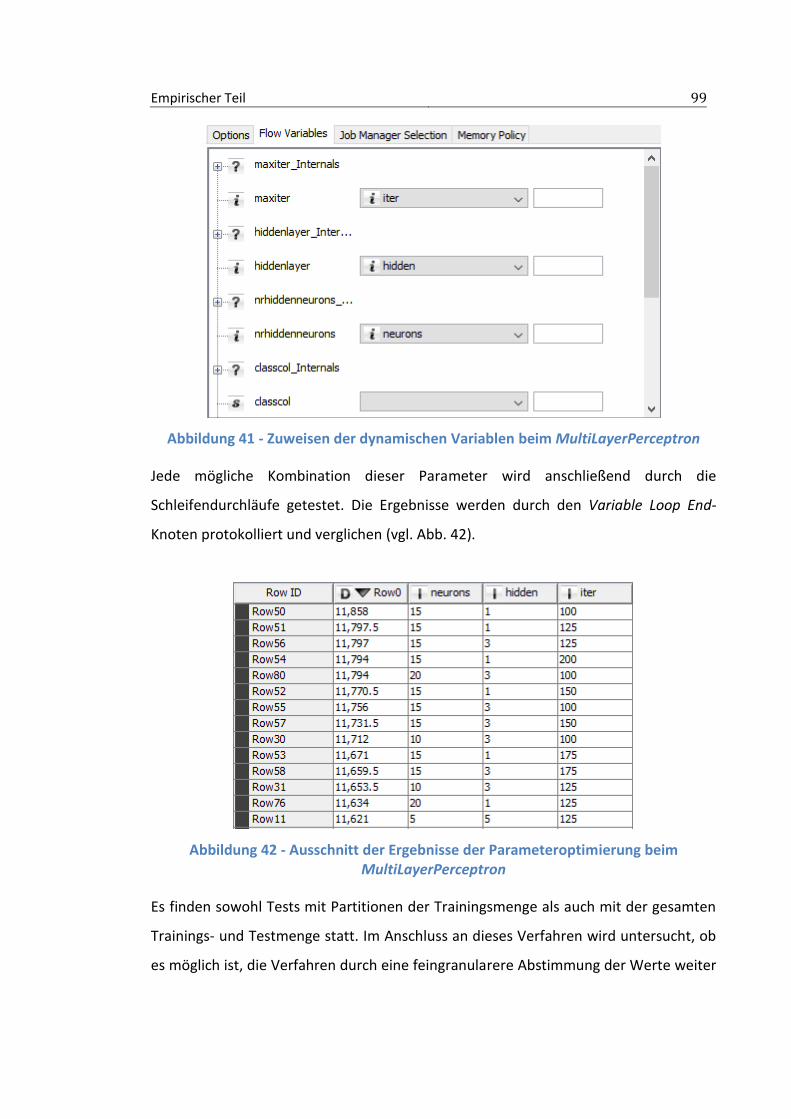
Empirischer Teil 99
Abbildung 41 - Zuweisen der dynamischen Variablen beim MultiLayerPerceptron
Jede mögliche Kombination dieser Parameter wird anschließend durch die
Schleifendurchläufe getestet. Die Ergebnisse werden durch den Variable Loop End-
Knoten protokolliert und verglichen (vgl. Abb. 42).
Abbildung 42 - Ausschnitt der Ergebnisse der Parameteroptimierung beim MultiLayerPerceptron
Es finden sowohl Tests mit Partitionen der Trainingsmenge als auch mit der gesamten
Trainings- und Testmenge statt. Im Anschluss an dieses Verfahren wird untersucht, ob
es möglich ist, die Verfahren durch eine feingranularere Abstimmung der Werte weiter

Empirischer Teil 100
zu optimieren. Die besten Ergebnisse der einzelnen Verfahren sind in Tabelle 12
zusammen mit den spezifischen Parametern dargestellt.
Modell Parameter Umsatz in €
Künstliches neuronales Netz (MultiLayerPerceptron)
Iterations: 100, hidden layers: 1, neurons per layer: 15, random seed: yes
11.858
Gradient Boosted Trees Tree depth: 4, number of models: 102, learning rate: 0,1, random seed: yes
12.184
Random Forest (mit Equal Size Sampling)
Split: information gain, tree depth: 4, number of models: 120
11.372
Tabelle 12 - Maximaler Umsatz der Verfahren nach der Parameteroptimierung
Mit Hilfe der Parameteroptimierung werden die Ergebnisse somit weiter verbessert. Die
deutlichste Umsatzsteigerung ist beim neuronalen Netz zu beobachten. Bei den
Verfahren Gradient Boosted Trees und Random Forest sind durch die Analyse der
Parameter geringe Umsatzsteigerungen zu erzielen.
3.4 Ergebnisse
Die besten Ergebnisse werden durch die Ensemble-Methoden erreicht. Kein anderes der
untersuchten Verfahren erzielt entsprechend gute Werte. Das beste Gesamtergebnis
wird mit 12.184 Euro durch das Gradient Boosted Trees-Verfahren erreicht.
Ein großer Einfluss auf die Modellgüte der einzelnen Verfahren wird von der
Klassenverteilung in den verwendeten Trainingsmengen ausgeübt. Mit der ursprünglich
vorliegenden Trainingsmenge, die hinsichtlich des Klassifikationsmerkmals sehr ungleich
verteilt ist, werden die schlechtesten Ergebnisse erzielt.

Empirischer Teil 101
Im Verlauf der Untersuchungen stellte sich heraus, dass mit einem Klassenverhältnis im
Bereich von 1:1 bis 1,5:1 (Klasse 0: Klasse 1) die besten Ergebnisse erreicht werden. Das
Random Forest-Verfahren bildet das aussagekräftigste Modell mit einer gleichverteilten
Trainingsmenge. Das Gradient Boosted Trees-Verfahren sowie das künstliche neuronale
Netz arbeiten mit einer 1,5:1 verteilten Trainingsmenge am effektivsten.
Bei der Prädiktorenselektion wird durch das Filtern der Merkmale anhand des
Korrelationskoeffizienten eine leichte Verbesserung der Modellgüte erreicht. Die
Hauptkomponentenanalyse und die Rückwärtsselektion verschlechtern die Ergebnisse
der verwendeten Modelle deutlich.
Darüber hinaus wird eine weitere Optimierung der Modelle durch eine systematische
Parameteranalyse erzielt. Die deutlichste Verbesserung ist bei den künstlichen
neuronalen Netzen zu erkennen.
Eine Übersicht über die durch die jeweiligen Optimierungsschritte verwirklichten
Umsatzsteigerungen ist in Abb. 43 dargestellt.
Abbildung 43 - Umsatzsteigerungen durch Modelloptimierung (Beträge in Euro)
Die durch die Data Mining-Verfahren erzielten Ergebnisse werden mit dem Basisumsatz
als Referenzgröße verglichen. Der Basisumsatz von 8.548,5 Euro wird wie erläutert
erzielt, wenn pauschal jedem Kunden ein Gutschein zugesendet wird.
In Tabelle 13 ist die prozentuale Umsatzsteigerung in Bezug auf den Basisumsatz
dargestellt.

Abschlussbetrachtung 102
Modell Umsatzsteigerung
Gradient Boosted Trees 42,52 %
Künstliches neuronales Netz (MultiLayerPerceptron)
38,71 %
Random Forest (mit Equal Size Sampling)
33,02 %
Tabelle 13 - Prozentuale Umsatzsteigerung bezogen auf den Basisumsatz
Es ist zu erkennen, dass mit Hilfe des Gradient Boosted Trees-Modells eine
Umsatzsteigerung von 42,52 % erreicht wird. Die erzielten Umsatzsteigerungen der
beiden verbleibenden Modelle liegen bei über einem Drittel.
4 Abschlussbetrachtung
Die Abschlussbetrachtung beinhaltet ein Fazit in Bezug auf die in dieser Arbeit
verwendete Vorgehensweise und die erreichten Ergebnisse. Zudem wird ein Ausblick
auf mögliche weiterführende Untersuchungen, sowie die aktuelle Entwicklung der
Ensemble-Methoden gegeben.

Abschlussbetrachtung 103
4.1 Fazit
Es ist anhand der vorliegenden Arbeit zu erkennen, dass vor der Anwendung von
ausgewählten Data Mining-Verfahren zunächst eine umfassende Datenerhebung sowie
ein systematischer Datenvorverarbeitungsprozess zu erfolgen hat.
Somit wird gewährleistet, dass ein tiefgreifendes Datenverständnis vorliegt und die Data
Mining-Verfahren aufgrund der gesteigerten Datenqualität effektiver arbeiten. Sowohl
die Datenerhebung als auch die Datenvorverarbeitung beinhalten statistische Analysen,
die das Behandeln fehlender und inkonsistenter Werte erleichtern. Insbesondere bei
einem Ersetzen dieser Werte ist es wichtig, anhand der statistischen Auswertungen
sinnvolle Substitutionswerte zu ermitteln.
Die ungleiche Klassenverteilung innerhalb der Datensätze übt einen entscheidenden
Einfluss auf die Ergebnisse der einzelnen Verfahren aus. Es findet eine Verzerrung der
Ergebnisse hinsichtlich der überrepräsentierten Klasse statt, der durch Sampling-
Methoden entgegenzuwirken ist. Welche der unterschiedlichen Sampling-Methoden
am besten geeignet ist, hängt von den Eigenschaften der jeweiligen Daten und den
verwendeten Verfahren ab. Besonderes Augenmerk ist dabei auf die Anzahl der zur
Verfügung stehenden Datenobjekte zu legen. In der vorliegenden Arbeit liegen
ausreichend große Datensätze vor, um Under-Sampling anzuwenden. Durch Under-
Sampling werden im Vergleich mit den übrigen Sampling-Methoden die mit Abstand
besten Ergebnisse erzielt. Aufgrund der vielen Voruntersuchungen und Testdurchläufe
ist dieser Prozess sehr zeitintensiv.
Durch die Selektion relevanter Prädiktoren wird eine zusätzliche Verbesserung der
Modellgüte erreicht. Die einzige der in dieser Arbeit verwendeten Methoden zur
Prädiktorenselektion, durch die eine Verbesserung der Modelle ermöglicht wird, ist die
Filterung der Merkmale anhand der Korrelationskoeffizienten. Die Steigerung der
Modellgüte ist gering, aber darüber hinaus wird durch eine Merkmalsreduktion die
Komplexität der Modelle verringert und ihre Performanz erhöht.

Abschlussbetrachtung 104
Weitere leichte Modelloptimierungen werden durch die systematische
Parameteranalyse erzielt. Hier zeigt sich, dass die in KNIME vorkonfigurierten
Standardparameter eine gute Ausgangsbasis bilden, da sie keinen großen
Optimierungsspielraum zulassen.
Hinsichtlich der Modellgüte kristallisieren sich die Ensemble-Methoden als Favoriten
heraus. Durch diese Ergebnisse wird der Trend der letzten Jahre bestätigt, in denen die
Ensemble-Methoden immer populärer geworden sind und ihr Einfluss auf das Data
Mining sich ständig vergrößert hat. Durch die schrittweise Verbesserung der vielen
einzelnen Basismodelle und den abschließenden Abstimmungsprozess generieren diese
Modelle einen entscheidenden Vorteil. Dieser Prozess ähnelt der Entscheidungsfindung
in anderen Bereichen, in denen ein Beraterstab konsultiert und anschließend auf
Grundlage der verschiedenen Positionen eine endgültige Entscheidung getroffen wird.
Der Nutzen von Data Mining wird anhand der erzielten Umsatzsteigerung von 42,52 %
in Bezug auf den Basisumsatz deutlich. Ein derartiger Wettbewerbsvorteil ist durch
andere Maßnahmen mit vergleichbaren Ressourcen nur sehr schwer zu erreichen. Dies
gilt besonders für den Online-Handel mit Medien, der von einer hohen Anzahl an
Anbietern und starker Konkurrenz geprägt ist. Zudem sind in dem sofort zu
realisierenden Umsatz die positiven Auswirkungen auf die zukünftige Kundenbindung
und den Customer Lifetime Value noch nicht enthalten. Diese Effekte machen sich
zusätzlich mittel- und langfristig hinsichtlich des Unternehmenserfolgs bemerkbar.
4.2 Ausblick
Interessant in Bezug auf mögliche weiterführende Untersuchungen ist der Einsatz
vergleichbarer Data Mining-Modelle auf andere After Sales Marketing-Maßnahmen wie
die Einführung von Kundenkarten und die Ausschöpfung von Cross Selling-Potentialen.

Abschlussbetrachtung 105
Es ist zu ermitteln, in welchem Umfang in diesen Bereichen weitere Umsatzsteigerungen
möglich sind.
Die Ensemble-Methoden befinden sich in einem Stadium der ständigen
Weiterentwicklung. Es wird zu beobachten sein, inwieweit optimierte Verfahren mit
Datensätzen umgehen, die eine ungleichmäßige Klassenverteilung aufweisen.
Verbessert sich die Modellgüte hinsichtlich dieser Daten, werden zeit- und
ressourcenintensive Datenvorverarbeitungsprozesse eingespart und der gesamte Data
Mining-Prozess gestaltet sich effizienter.
Somit ist es interessant, die in dieser Arbeit durchgeführten Untersuchungen mit neu
erscheinenden KNIME Versionen zu wiederholen und die Modellgüte der
entsprechenden Verfahren zu vergleichen. Eine weitere Möglichkeit besteht darin,
andere Data Mining-Software zur Bearbeitung der vorliegenden Aufgabenstellung zu
verwenden und die Ergebnisse zu vergleichen.

106
Literaturverzeichnis
Aggelos 2010 AGGELOS, Pikrakis; CAVOURAS, Dionisis; KOUTROUMBAS, Konstantinos; THEODORIS, Sergios: Introduction to pattern recognition: a MATLAB approach. Amsterdam: Elsevier, 2010. - ISBN 978-0-12-374486-9. Baars 2010 BAARS, Henning; KEMPER, Hans-Georg; MEHANNA, Walid: Business Intelligence - Grundlagen und praktische Anwendungen: Eine Einführung in die IT-basierte Managementunterstützung. 3. Auflage. Wiesbaden: Vieweg + Teubner, 2010. - ISBN 978-3-8348-0719-9. Backhaus 2015 BACKHAUS, Klaus; ERICHSON, Bernd; WEIBER, Rolf: Fortgeschrittene Multivariate Analysemethoden: Eine anwendungsorientierte Einführung. 3. Auflage. Berlin Heidelberg: Springer Gabler, 2015. - ISBN 978-3-662-46087-0. Backhaus 2016 BACKHAUS, Klaus; ERICHSON, Bernd; PLINKE, Wulff; WEIBER, Rolf: Multivariate Analysemethoden: Eine anwendungsorientierte Einführung. 14. Auflage. Berlin Heidelberg: Springer Gabler, 2016. - ISBN 978-3-662-46076-4. Bankhofer 2008 BANKHOFER, Udo; VOGEL, Jürgen: Datenanalyse und Statistik: Eine Einführung für Ökonomen im Bachelor. 1. Auflage. Wiesbaden: Gabler, 2008. - ISBN 978-3-8349-0434-8. Bde 2016 Github Repository: Online verfügbar unter: http://bdewilde.github.io/assets/images/2012-10-26-knn-concept.png Abruf: 2016-07-10.

Literaturverzeichnis 107
Bissantz 1993 BISSANTZ, Nicolai; HAGEDORN, Jürgen: Data mining (Datenmustererkennung). Wirtschafts- informatik 35(5), 481-487 (1993).
Böwing 2011 BÖWING-SCHMALENBROCK, Melanie; JURCZOK, Anne: Multiple Imputation in der Praxis: ein sozialwissenschaftliches Anwendungsbeispiel. Potsdam: Universität Potsdam, 2011.
Borgelt 2015 BORGELT, Christian; BRAUNE, Christian; KLAWONN, Frank; KRUSE, Rudolf; MOEWES, Christian; STEINBRECHER, Matthias: Computational Intelligence: Eine methodische Einführung in Künstliche Neuronale Netze, Evolutionäre Algorithmen, Fuzzy-Systeme und Bayes-Netze. 2. Auflage. Wiesbaden: Springer Vieweg, 2015. - ISBN 978-3-658-10904-2.
Bruhn 2015 BRUHN, Manfred; HADWICH, Karsten; MEFFERT, Heribert: Dienstleistungsmarketing: Grundlagen-Konzepte-Methoden. 8. Auflage. Wiesbaden: Springer Gabler, 2015. - ISBN 978-3-658-05046-7.
Chapman 1999 CHAPMAN, Pete; CLINTON, Julian; KERBER, Randy; KHABAZA, Thomas; REINARTZ, Thomas; SHEARER, Colin; WIRTH, Rüdiger: CRISP-DM 1.0: Step-by-step data mining guide. Online verfügbar unter: https://www.the-modeling-agency.com/crisp-dm.pdf Abruf: 2016-05-03. Chawla 2005 CHAWLA, Nitesh V.: Data Mining For Imbalanced Datasets: An Overview. In: Data Mining and Knowledge Discovery Handbook. 1. Auflage. New York, 2005. - ISBN 978-0-387-24435-8. Cleve 2014 CLEVE, Jürgen; LÄMMEL, Uwe: Data mining. 1. Auflage. München: De Gruyter Oldenbourg, 2014. - ISBN 978-3-486-71391-6. Davis 2006 DAVIS, Jesse; GOADRICH, Mark: The relationship between Precision-Recall and ROC curves. In: International Conference on Machine Learning. Madison 2006. S. 233-240. DMC 2010 Data Mining Cup: Homepage. dmc2010_task.pdf. Online verfügbar unter: http://www.data-mining-cup.de/rueckblick/rueckblick/article/dmc-2010.html Abruf: 2016-06-12.

Literaturverzeichnis 108
Eibe 2011 EIBE, Frank; HALL, Mark A.; WITTEN, Ian H.: Data Mining: practical machine learning tools and techniques. 3. Auflage. Amsterdam [u.a.]: Elsevier/Morgan Kaufmann, 2011. - ISBN 978-0-08-089036-4. Elder 2009 ELDER, John; MINER, Gary; NISBET, Robert: Handbook of Statistical Analysis and Data Mining Applications. 1. Auflage. Amsterdam Boston: Academic Press/Elsevier, 2009. - ISBN 978-0-08-091203-5. Elder 2010 ELDER, John; SENI, Giovanni: Ensemble Methods in Data Mining: Improving accuracy through combining predictions. In: Synthesis Lectures on Data Mining and Knowledge Discovery. Chicago: University of Illinois, 2010. Online verfügbar unter: https://wiki.eecs.yorku.ca/course_archive/2014-15/F/4412/_media/ensemble_data_ mining.pdf Abruf: 2016-07-09. Fayyad 1996 FAYYAD, Usama; PIATETSKY-SHAPIRO, Gregory; SMYTH, Padhraic (1996a): From Data Mining to Knowledge Discovery in Databases. In: Communications of the ACM, Vol. 39 (1996a) Nr. 11, S. 37-54. Freitas 2003 FREITAS, Alex A.; NIEVOLA, Julio C.; OTERO, Fernando E. B.; SILVA, Monique M. S.: Genetic Programming for attribute construction in data mining. In: EuroGP´03 Proceedings of the 6th European conference on Genetic programming. Berlin Heidelberg: Springer, 2003. - ISBN 3-540-00971-X. Friedman 2009 FRIEDMAN, Jerome; HASTIE, Trevor; TIBSHIRANI, Robert: The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2. Auflage. New York: Springer, 2009. - ISBN 978-0-387-84857-0. Gabler 2016 Gabler Wirtschaftslexikon: Homepage. Stichwort: Korrelationskoeffizient. Online verfügbar unter: 35/Archiv/10564/korrelationskoeffizient-v13.html Abruf: 2016-07-10. Günter 2015 GÜNTER, Jana; NEU, Matthias: Erfolgreiche Kundenrückgewinnung: Verlorene Kunden identifizieren, halten und zurückgewinnen. Wiesbaden: Springer Gabler, 2015. - ISBN 978-3-658-04807-5.

Literaturverzeichnis 109
Han 2012 HAN, Jiawei; KAMBER, Micheline; PEI, Jian: Data Mining: Concepts and Techniques. 3. Auflage. Amsterdam [u.a.]: Elsevier/Morgan Kaufmann, 2012. - ISBN 978-0-12-381479-1. Hogenschurz 2008 HOGENSCHURZ, Bernhard; KEUPER, Frank: Management, Marketing, Promotion und Performance. Wiesbaden: GWV Fachverlage, 2008. - ISBN 978-3-8349-9591-9. Imgur 2016 Imgur: Homepage. Online verfügbar unter: http://i.stack.imgur.com/1gvce.png Abruf: 2016-07-10. Klüver 2009 KLÜVER, Jürgen; SCHMIDT, Jörn; STOICA-KLÜVER, Christina: Modellierung komplexer Prozesse durch naturanaloge Verfahren: Komplexe adaptive Systeme – Modellbildungen und -theorie – neuronale Netze – Soft Computing und verwandte Techniken. 1. Auflage. Wiesbaden: Vieweg + Teubner, 2009. - ISBN 978-3-8348-0400-6. KNIME 2016 KNIME: Homepage. Online verfügbar unter: https://www.knime.org/knime-analytics-platform Abruf: 2016-07-07. Krishna 2013 KRISHNA, Rajan: Informatics for Materials Science and Engineering: Data-driven Discovery for Accelerated Experimentation and Application. Burlington: Elsevier Science, 2013. - ISBN 978-0-12-394399-6. Kronthaler 2014 KRONTHALER, Franz: Statistik angewandt: Datenanalyse ist (k)eine Kunst. Berlin: Springer, 2014. - ISBN 978-3-642-53740-0. Lenz 2013 LENZ, Hans-Joachim; MÜLLER, Roland: Business Intelligence. Berlin Heidelberg: Springer, 2013. - ISBN 978-3-642-35560-8. Levatic 2010 LEVATIC, Jurica; MALENICA, Antonija; PAVLIC, Ilija: Data Mining Cup 2010 Report. Zagreb: University of Zagreb, 2010. Online verfügbar unter: https://web.math.pmf.unizg.hr/nastava/su/index.php/download_file/-/view/39/ Abruf: 2016-06-05.

Literaturverzeichnis 110
Lprogram 2016 Lazyprogrammer: Homepage. Online verfügbar unter: http://lazyprogrammer.me/wp-content/uploads/2015/11/PCA.jpg Abruf: 2016-07-10. Medcalc 2016 Medcalc: Homepage. Online verfügbar unter: https://www.medcalc.org/manual/_help/images/roc_intro3.png Abruf: 2016-07-12. Meier 2012 MEIER, Andreas; STORMER, Henrik: eBusiness & eCommerce: Management der digitalen Wertschöpfungskette. 3. Auflage. Berlin Heidelberg: Springer, 2012. - ISBN 978-3-642-29802-8. Oberhofer 1996 OBERHOFER, Walter; ZIMMERER, Thomas: Wie künstliche neuronale Netze lernen: Ein Blick in die Black Box der Backpropagation Netzwerke. In: Regensburger Diskussionsbeiträge Nr. 287. Regensburg: Universität Regensburg, Institut für Volkswirtschaftslehre einschließlich Ökonometrie, 1996. Online verfügbar unter: http://www.hs-ansbach.de/fileadmin/bachelor/Betriebswirtschaftslehre/Zimmerer/Literatur/DP_287.pdf Abruf: 01.06.2016. Refaat 2007 REFAAT, Mamdouh: Data preparation for data mining using SAS. Amsterdam [u.a.]: Morgan Kaufmann, 2007. - ISBN 978-0-12-373577-5. Ruckstuhl 2008 RUCKSTUHL, Andreas: Numerische und statistische Methoden für Chemieingenieure. Zürich: Zürcher Hochschule Winterthur, 2008. Online verfügbar unter: http://stat.ethz.ch/~stahel/courses/cheming/nlreg.pdf Abruf: 2016-05-20. Runkler 2010 RUNKLER, Thomas: Data Mining: Methoden und Algorithmen intelligenter Datenanalyse. Wiesbaden: Vieweg + Teubner, 2010. - ISBN 978-3-8348-0858-5. Saed 2016 Saedsayad: Homepage. Online verfügbar unter: http://www.saedsayad.com/images/SVM_optimize.png Abruf: 2016-07-12. Schnöring 2016 SCHNÖRING, Marc: Konsequenzen der Prämieneinlösung in Kundenbindungsprogrammen: Theoretische Fundierung und empirische Analyse. Wiesbaden: Springer Gabler, 2016. - ISBN 978-3-658-12169-3.

Literaturverzeichnis 111
Sharafi 2013 SHARAFI, Armin: Knowledge Discovery in Databases: Eine Analyse des Änderungsmanagements in der Produktentwicklung. Wiesbaden: Springer, 2013. - ISBN 978-3-658-02002-6. Spehling 2007 SPEHLING, Markus: Analyse und Erweiterung von Methoden des Data Mining in räumlichen Datenbanken. Hannover: Leibnitz Universität Hannover, 2007. Statista 2016 Statista: Homepage. Online verfügbar unter: https://de.statista.com/statistik/lexikon/definition/57/f_test/ Abruf: 2016-07-09. Statistics 2016 Statistics4u: Homepage. Online verfügbar unter: http://www.statistics4u.info/fundstat_germ/ee_classifier_performance_metrics.html Abruf: 2016-06-09. Steinlein 2003 STEINLEIN, Uwe: Data Mining als Instrument der Responseoptimierung im Direktmarketing: Methoden zur Bewältigung niedriger Responseraten. Göttingen: Cuvillier, 2004. - ISBN 3-89873-981-3. Strecker 1997 STRECKER, Stefan: Künstliche Neuronale Netze - Aufbau und Funktionsweise In Arbeitspapiere WI Nr. 10/1997, Lehrstuhl für allgemeine BWL und Wirtschaftsinformatik. Mainz: Universität Mainz, 1997. Wang 1999 WANG, Xue Zhang: Data Mining and Knowledge Discovery for Process Monitoring and Control. London [u.a.]: Springer, 1999. - ISBN 1-85233-137-2. Wikim 2016 Wikimedia: Homepage. Online verfügbar unter: https://upload.wikimedia.org/wikibooks/de/thumb/8/88/CLV.jpg/500px-CLV.jpg Abruf: 2016-07-12.

Versicherung über Selbstständigkeit Hiermit versichere ich, dass ich die vorliegende Arbeit ohne fremde Hilfe selbstständig verfasst und nur die angegebenen Hilfsmittel benutzt habe. Hamburg, den _______________ __________________________







