Download - Prof. Th. Ottmann

1
Vorlesung Informatik 2
Algorithmen und Datenstrukturen
(17 - Bäume: Durchlaufreihenfolgen, Analyse nat. Bäume)
Prof. Th. Ottmann

2
Binärbäume zur Speicherung von Mengen von Schlüsseln (in den inneren
Knoten der Bäume), so dass die Operationen
• Suchen (find)
• Einfügen (insert)
• Entfernen (remove, delete)
unterstützt werden.
Suchbaumeigenschaft: Die Schlüssel im linken Teilbaum eines Knotens p
sind alle kleiner als der Schlüssel von p, und dieser ist wiederum
kleiner als sämtliche Schlüssel im rechten Teilbaum von p.
Implementierung:
Binäre Suchbäume
3
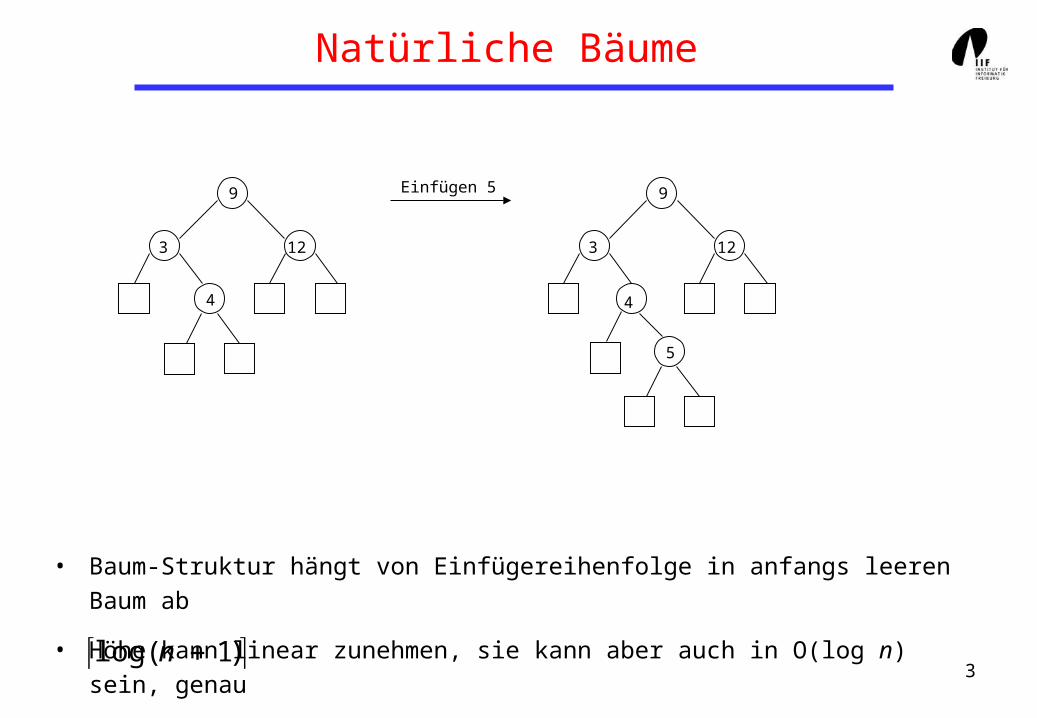
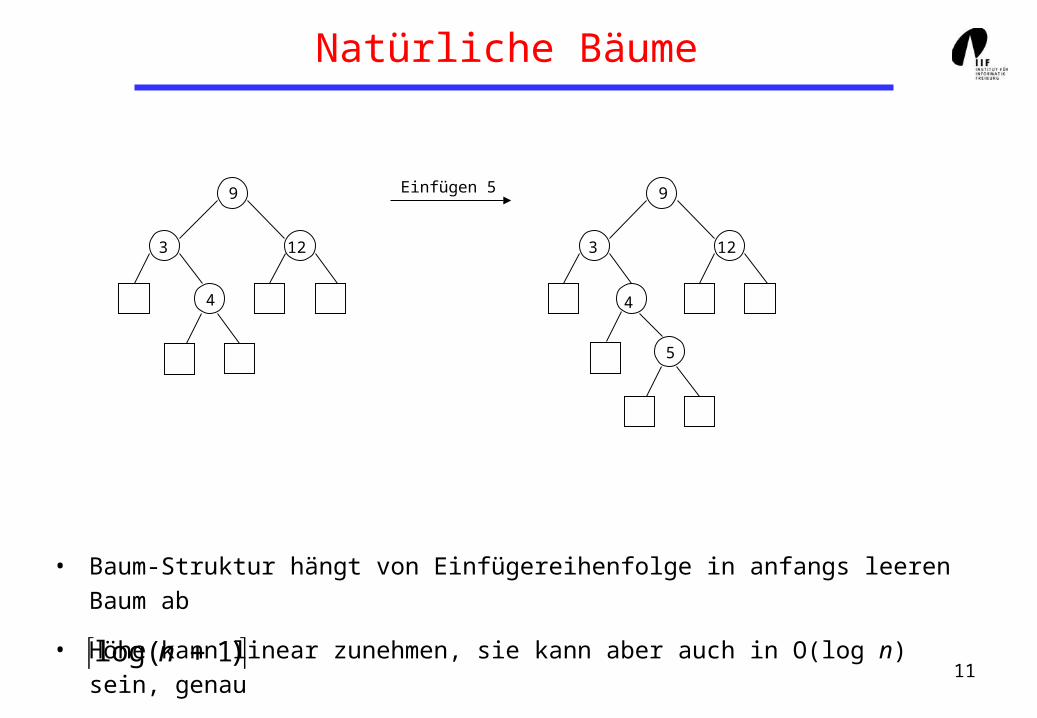
Natürliche Bäume
• Baum-Struktur hängt von Einfügereihenfolge in anfangs leeren Baum ab
• Höhe kann linear zunehmen, sie kann aber auch in O(log n) sein, genau
)1log( n
9
3 12
4
9
3 12
5
Einfügen 5
4

4
Durchlaufreihenfolgen in Bäumen
Durchlaufreihenfolgen zum Besuchen der Knoten des Baums
• zur Ausgabe
• zur Berechnung von Summe, Durchschnitt, Anzahl der Schlüssel . . .
• zur Änderung der Struktur
Wichtigste Durchlaufreihenfolgen:
1. Hauptreihenfolge = Preorder = WLRbesuche erst Wurzel, dann rekursiv linken und rechten Teil-Baum falls vorhanden
2. Nebenreihenfolge = Postorder = LRW
3. Symmetrische Reihenfolge = Inorder = LWR
4. die Spiegelbild-Varianten von 1-3
5
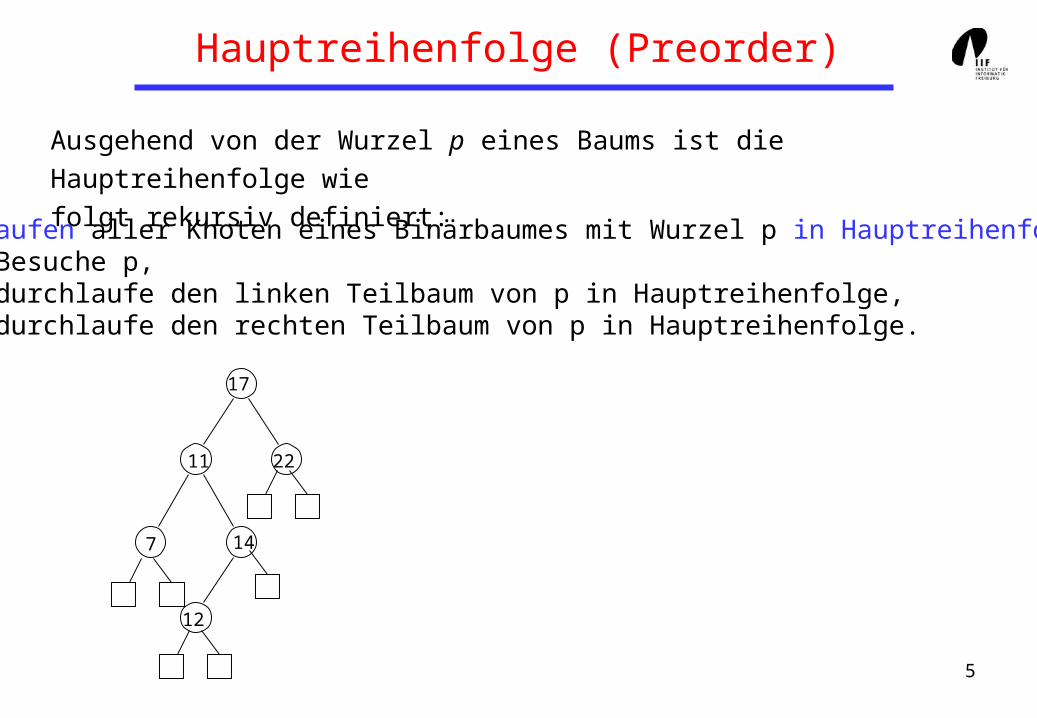
Hauptreihenfolge (Preorder)
Ausgehend von der Wurzel p eines Baums ist die Hauptreihenfolge wie
folgt rekursiv definiert:
Durchlaufen aller Knoten eines Binärbaumes mit Wurzel p in Hauptreihenfolge:Besuche p, durchlaufe den linken Teilbaum von p in Hauptreihenfolge,durchlaufe den rechten Teilbaum von p in Hauptreihenfolge.
17
11 22
7 14
12

6
Hauptreihenfolge Programm
// Hauptreihenfolge; WLRvoid preOrder (){ preOrder (root); System.out.println ();}void preOrder (SearchNode n){ if (n == null) return; System.out.print (n.content+" "); preOrder (n.left); preOrder (n.right);}// Nebenreihenfolge; LRWvoid postOrder (){ postOrder (root); System.out.println ();}// ...
7
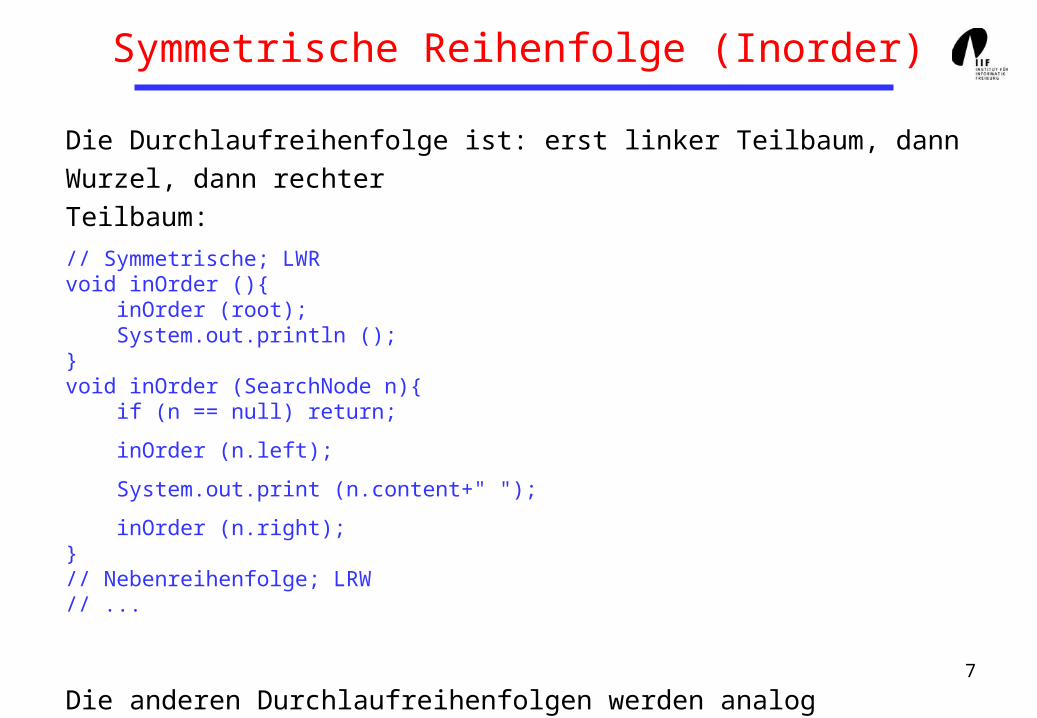
Symmetrische Reihenfolge (Inorder)
Die Durchlaufreihenfolge ist: erst linker Teilbaum, dann Wurzel, dann rechter
Teilbaum:
// Symmetrische; LWRvoid inOrder (){ inOrder (root); System.out.println ();}void inOrder (SearchNode n){ if (n == null) return;
inOrder (n.left);
System.out.print (n.content+" ");
inOrder (n.right);}// Nebenreihenfolge; LRW// ...
Die anderen Durchlaufreihenfolgen werden analog implementiert.
8
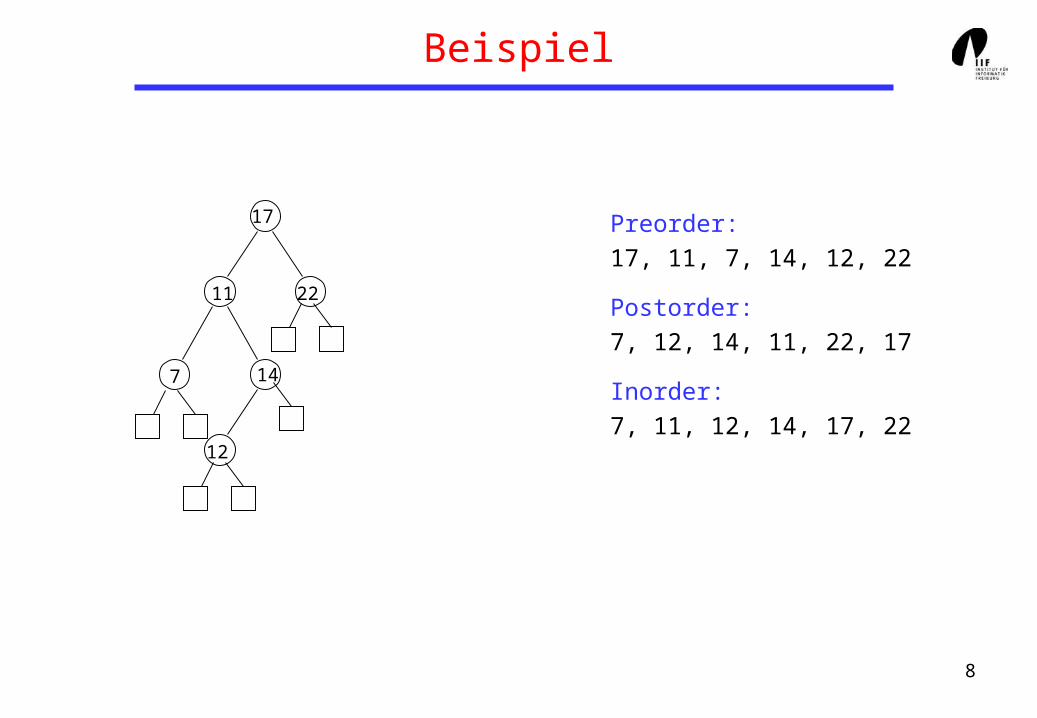
Beispiel
Preorder:
17, 11, 7, 14, 12, 22
Postorder:
7, 12, 14, 11, 22, 17
Inorder:
7, 11, 12, 14, 17, 22
17
11 22
7 14
12
9
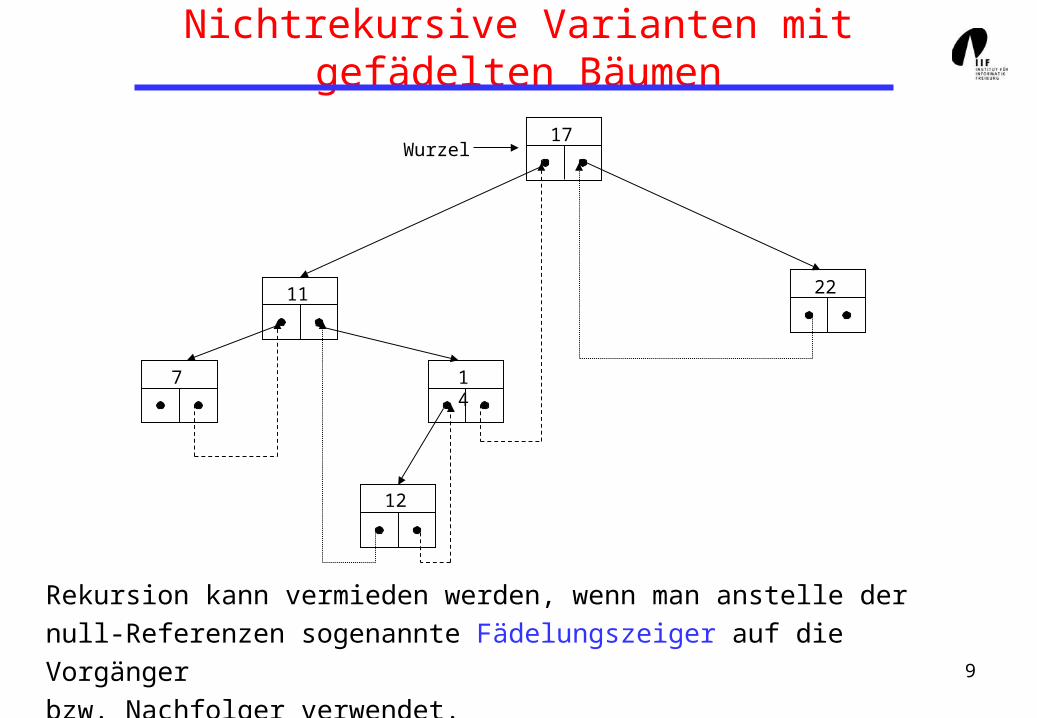
Nichtrekursive Varianten mit gefädelten Bäumen
Rekursion kann vermieden werden, wenn man anstelle der
null-Referenzen sogenannte Fädelungszeiger auf die Vorgänger
bzw. Nachfolger verwendet.
17
2211
14
12
7
Wurzel

10
Binärbäume zur Speicherung von Mengen von Schlüsseln (in den inneren
Knoten der Bäume), so dass die Operationen
• Suchen (find)
• Einfügen (insert)
• Entfernen (remove, delete)
unterstützt werden.
Suchbaumeigenschaft: Die Schlüssel im linken Teilbaum eines Knotens p
sind alle kleiner als der Schlüssel von p, und dieser ist wiederum
kleiner als sämtliche Schlüssel im rechten Teilbaum von p.
Implementierung:
Binäre Suchbäume
11
Natürliche Bäume
• Baum-Struktur hängt von Einfügereihenfolge in anfangs leeren Baum ab
• Höhe kann linear zunehmen, sie kann aber auch in O(log n) sein, genau
)1log( n
9
3 12
4
9
3 12
5
Einfügen 5
4
12
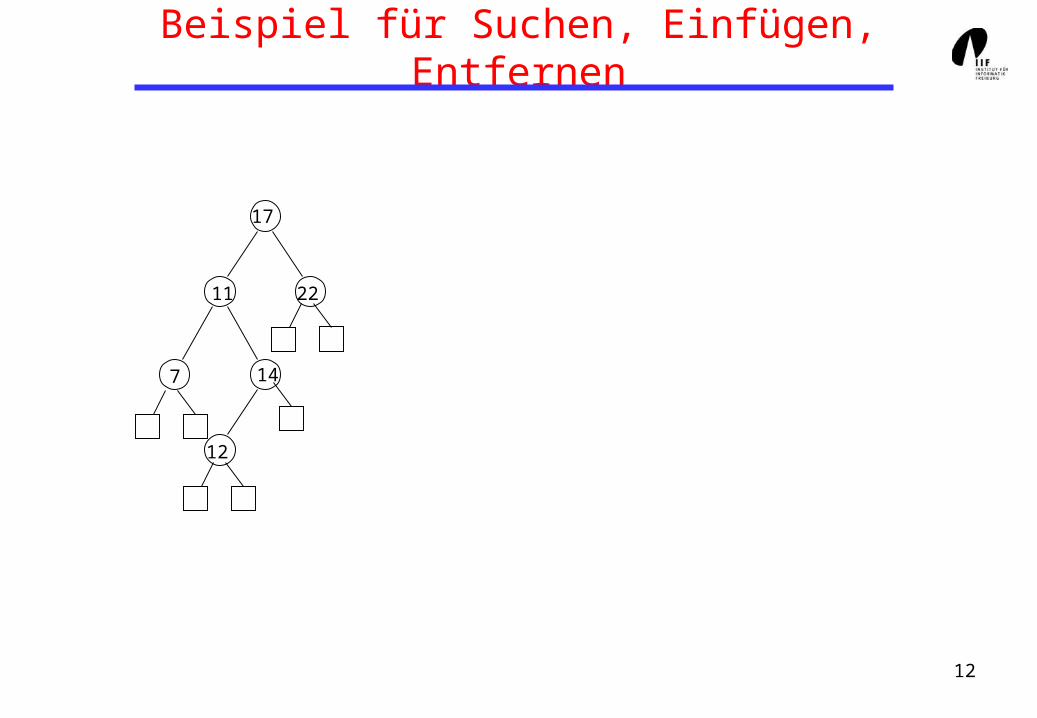
Beispiel für Suchen, Einfügen, Entfernen
17
11 22
7 14
12

13
Sortieren mit natürlichen Suchbäumen
Idee: Bau für die Eingabefolge einen natürlichen Suchbaum auf und gib die
Schlüssel in symmetrischer Reihenfolge (Inorder) aus.
Bemerkung: Abhängig von der Eingabereihenfolge kann der Suchbaum
degenerieren.
Komplexität: Abhängig von der internen Pfadlänge
Schlechtester Fall: Sortierte Eingabe: Schritte.
Bester Fall: Es entsteht ein vollständiger Suchbaum mit minimal
möglicher Höhe von etwa log n. n mal Einfügen und Ausgeben ist daher in
Zeit O(n log n) möglich.
Mittlerer Fall: ?
)( 2n
14
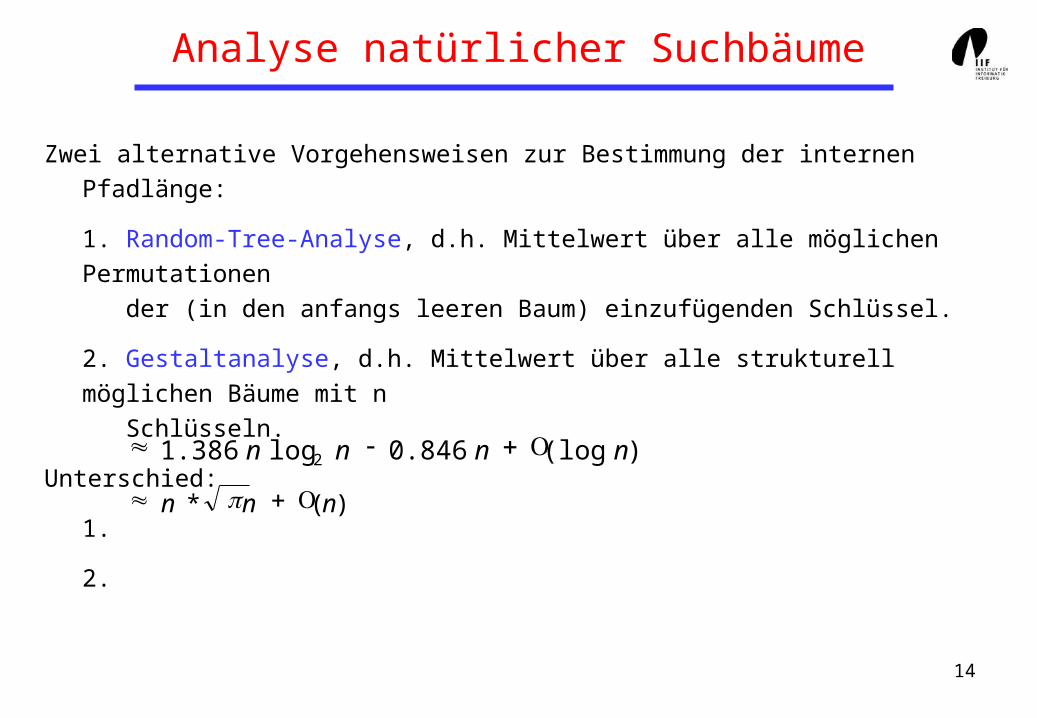
Analyse natürlicher Suchbäume
Zwei alternative Vorgehensweisen zur Bestimmung der internen Pfadlänge:
1. Random-Tree-Analyse, d.h. Mittelwert über alle möglichen Permutationen
der (in den anfangs leeren Baum) einzufügenden Schlüssel.
2. Gestaltanalyse, d.h. Mittelwert über alle strukturell möglichen Bäume mit n
Schlüsseln.
Unterschied:
1.
2.
)(log846.0log386.1 2 nnnn
)(* nnn
15
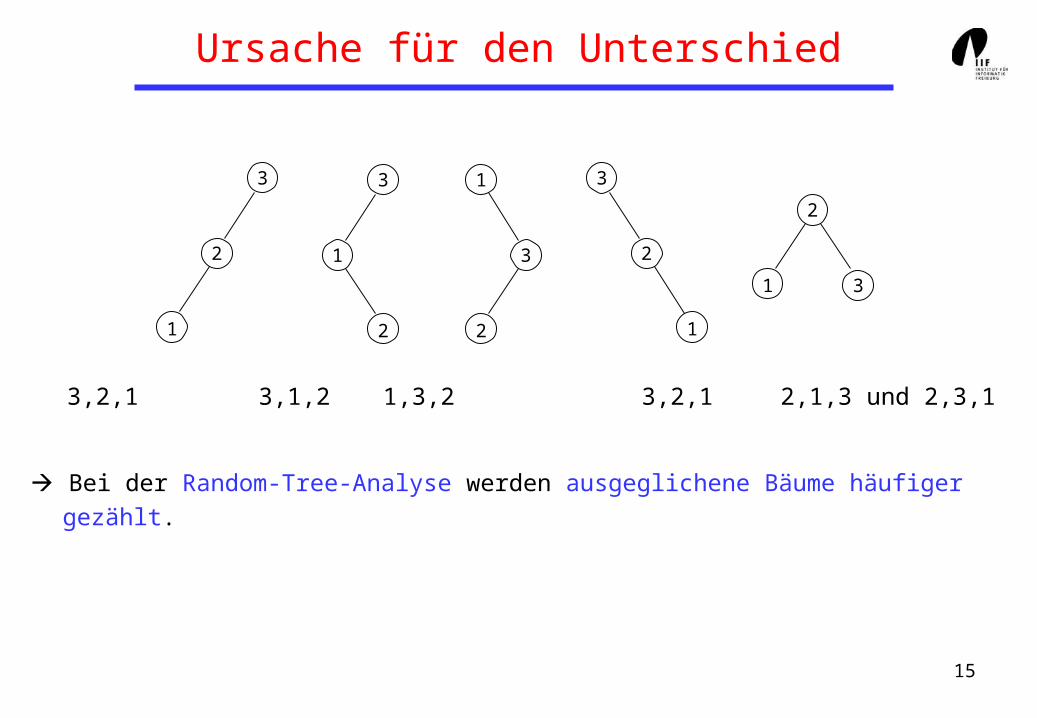
Ursache für den Unterschied
Bei der Random-Tree-Analyse werden ausgeglichene Bäume häufiger
gezählt.
3
2
1
3
1
2
1
3
2
3
2
1
3
2
1
3,2,1 3,1,2 1,3,2 3,2,1 2,1,3 und 2,3,1

16
Interne Pfadlänge
Interne Pfadlänge: Maß zu Beurteilung der Güte eines Suchbaumes.
Rekursive Definition:
1. Ist t der leere Baum, so ist
I(t) = 0.
2. Für einen Baum mit Wurzel t, linkem Teilbaum tl und rechtem
Teilbaum tr gilt:
I(t) := I(tl) + I(tr)+ Zahl der Knoten von t.
Offensichtlich gilt:p
tI
P innerer Knoten von t
pTiefe 1)()(
17
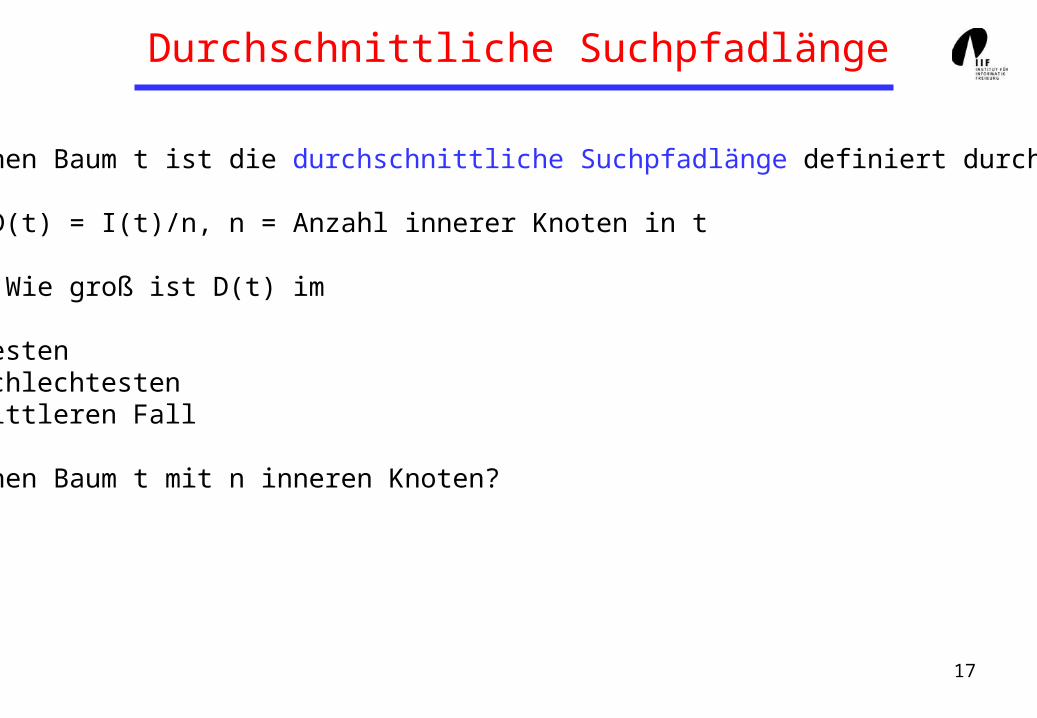
Durchschnittliche Suchpfadlänge
Für einen Baum t ist die durchschnittliche Suchpfadlänge definiert durch:
D(t) = I(t)/n, n = Anzahl innerer Knoten in t
Frage: Wie groß ist D(t) im
• besten• schlechtesten• mittleren Fall
für einen Baum t mit n inneren Knoten?

18
Interne Pfadlänge: Bester Fall
Es ensteht ein vollständiger Binärbaum
19
Interne Pfadlänge: Schlechtester Fall

20
Zufällige Bäume
• Seien oBdA die Schlüssel {1,…,n} einzufügen.
• Sei ferner s1,…, sn eine zufällige Permutation dieser Schlüssel.
• Somit ist die Wahrscheinlichkeit P(s1 = k), dass s1 gerade den
Wert k hat, genau 1/n.
• Wenn k der erste Schlüssel ist, wird k zur Wurzel.
• Dann enthalten der linke Teilbaum k – 1 Elemente (nämlich die
Schlüssel 1,…,k - 1) und der rechte Teilbaum n – k Elemente (d.h. die
Schlüssel k + 1,…,n).

21
Erwartete interne Pfadlänge
EI(n) : Erwartungswert für die interne Pfadlänge eines zufällig
erzeugten binären Suchbaums mit n Knoten
Offensichtlich gilt:
Behauptung: EI(n) 1.386n log2n - 0.846n + O(logn).
n
k
n
k
n
k
knEIkEIn
n
nknEIkEIn
nEI
EI
EI
1 1
1
))()1((1
))()1((1
)(
1)1(
0)0(

22
Beweis (1)
und daher
Aus den beiden letzten Gleichungen folgt
n
k
kEIn
nnEI0
)(*1
2)1()1(
1
0
2
0
2
)(*2*
)(*2)1()1(*)1(
n
k
n
k
kEInEIn
kEInnEIn
).(1
2
1
12)1(
12)()2()1()1(
)(*212)(*)1()1(
nEIn
n
n
nnEI
nnEInnEIn
nEInnEInnEIn

23
Beweis (2)
Durch vollständige Induktion über n kann man zeigen, dass für alle n 1 gilt:
ist die n -te harmonische Zahl, die wie folgt
Abgeschätzt werden kann:
Dabei ist die so genannte Eulersche Konstante.
nHn
1...
2
11
)1
(2
1ln 2nn
nHn
...5772.0
nHnnEI n 3)1(2)(

24
Beweis (3)
Damit ist
Und daher
)1(21ln2*)23(ln2)(n
nnnnnEI
...ln2
)23(log386.1
...ln2
)23(log*log
2log2
...ln2
)23(log*log
2
...ln2
)23(ln2)(
2
210
10
22
n
nn
n
nn
e
n
nn
e
n
nn
n
nEI

25
Beobachtungen
• Suchen, Einfügen und Entfernen eines Schlüssels ist bei einem
zufällig erzeugten binären Suchbaum mit n Schlüsseln im Mittel in
O(log2 n) Schritten möglich.
• Im schlechtesten Fall kann der Aufwand jedoch Ω(n) betragen.
• Man kann nachweisen, dass der mittlere Abstand eines Knotens von
der Wurzel in einem zufällig erzeugten Baum nur etwa 40% über
dem Optimum liegt.
• Die Einschränkung auf den symmetrischen Nachfolger
verschlechtert jedoch das Verhalten.
• Führt man in einem zufällig erzeugten Suchbaum mit n Schlüsseln n2
Update-Operationen durch, so ist der Erwartungswert für die
durschnittliche Suchpfadlänge lediglich ).( n

26
Typischer Binärbaum für eine zufällige Schlüsselsequenz

27
Resultierender Binärbaum nach n2 Updates

28
Strukturelle Analyse von Binärbäumen
Frage: Wie groß ist die durchschnittliche Suchpfadlänge eines Binärbaumes mit N
inneren Knoten, wenn man bei der Durchschnittsbildung jeden strukturell
möglichen Binärbaum mit N inneren Knoten genau einmal zählt?
Antwort: Sei
IN = gesamte interne Pfadlänge aller strukturell verschiedenen Binärbäume mit N
inneren Knoten
BN = Anzahl aller strukturell verschiedenen Bäume mit N inneren Knoten
Dann ist IN/BN =

29
Anzahl strukturell verschiedener Binärbäume
30
Gesamte interne Pfadlänge aller Bäume mit N Knoten
• Für jeden Baum t mit linkem Teilbaum tl und rechtem Teilbaum tr gilt:

31
Zusammenfassung
Die durchschnittliche Suchpfadlänge in einem Baum mit N inneren Knoten (gemittelt
über alle strukturell möglichen Bäume mit N inneren Knoten) ist:
1/N IN/BN







