konzept und realisierung eines zweidimensionalen ... · pdf fileuniversitat¨ des...
TRANSCRIPT

Universitat des SaarlandesProf. Dr.-Ing. L. ThieleLehrstuhl fur Mikroelektronik
S ITAS
SA
R
AV I E N
SI S
R
N
IVE
U
Konzept und Realisierung
eines zweidimensionalen
programmierbaren
Rechenfeldes mit
XILINX FPGAs
Diplomarbeit von Tobias Blickle
Betreuer: Dipl.-Inform. Joachim Konig
Eingereicht im Marz 1993

Inhaltsverzeichnis
Bilderverzeichnis iii
Tabellenverzeichnis iv
Kapitel 1 Einfuhrung 1
Kapitel 2 Einbettung 3
2.1 COMPAR 4
2.2 PAr2 4
2.3 Aufgabenstellung der Diplomarbeit 5
Kapitel 3 Konzept von PAr2 6
3.1 Xilinx FPGAs 6
3.2 Interface 9
3.3 Anforderungen 10
3.4 Grunduberlegungen 12
Kapitel 4 Die Komponenten von PAr2 18
4.1 Rechenfeld 18
4.1.1 Aufgabe 18
4.1.2 Kommunikation der Rechenfeld FPGAs untereinander 19
4.1.3 Kommunikation zwischen Rechenfeld und Ramcontroller 19
4.2 Ramcontroller 22
4.2.1 Aufgabe 22
4.2.2 Kommunikation zwischen Ramcontroller und Interface 23
4.2.3 Kommunikation zwischen Ramcontroller und RAM 24
4.3 Takterzeugung 28
4.3.1 Grundkonzept 28
4.3.2 Bestimmung des optimalen Timing 29
4.4 Modellierung der Kommunikation 36
4.5 Programmierung und Debugging 39
4.5.1 Vorbereiten der Programmierung 39
4.5.2 Programmiervorgang 41
4.5.3 Readback 42
ii

Kapitel 5 Realisierung der Hardware 445.1 Uberblick 44
5.2 Rechenfeld 465.3 Ramcontroller 48
5.4 Interface Adapter 495.4.1 Signalverteilung 49
5.4.2 Taktverteilung 505.4.3 General Purpose Bus 50
5.5 Layout 515.5.1 Stromversorgung 51
5.5.2 Signalleitungen 525.6 Test 54
5.7 Verbesserungsvorschlage zur Realisierung 55
Kapitel 6 Zusammenfassung 57
Literaturverzeichnis 58
Anhang A Programm zur Bestimmung des Timing 60
Anhang B Technische Angaben Rechenfeld 64
Anhang C Technische Angaben Ramcontroller 70
Anhang D Technische Angaben Ramcard I 77
Anhang E Technische Angaben Program&Readback Buffer 79
Anhang F Technische Angaben Interface-Adapter 81
Anhang G Meßstecker 90
iii

Bilderverzeichnis
Bild 1 Schematischer Aufbau eines XILINX FPGA . . . . . 7Bild 2 Vereinfachter Input-/Output Block (IOB) der
FPGAs. . . . . . . . . . . . . . . . . . . . . . . . . . . . 8Bild 3 Configurable Logic Block (CLB) der FPGAs. . . . . 9Bild 4 Blockschaltbild des PSI-Interface . . . . . . . . . . . 10Bild 5 Prinzipschaltbild von PAr2 — Kommunikation . . . 15Bild 6 Prinzipschaltbild Ramcontroller zu Bild 5 . . . . . . 16Bild 7 Prinzipschaltbild von PAr2 — Programmierung,
Readback und globaler Bus. . . . . . . . . . . . . . 17Bild 8 Kommunikation zwischen zwei
Rechenfeld-FPGAs. . . . . . . . . . . . . . . . . . . . 19Bild 9 Kommunikation zwischen Rechenfeld und
Ramcontroller . . . . . . . . . . . . . . . . . . . . . . . 20Bild 10 Prinzipielles Timingdiagramm fur die
Kommunikation zwischen Rechenfeld (RF) undRamcontroller (RC). . . . . . . . . . . . . . . . . . . . 21
Bild 11 Kommunikation zwischen Ramcontroller undInterface . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Bild 12 Prinzipielles Timingdiagramm fur dieKommunikation zwischen Ramcontroller(RC) undInterface(IF) uber den IFBUS. . . . . . . . . . . . . 25
Bild 13 Adreßmultiplexer der Ramcontroller . . . . . . . . . 26Bild 14 Prinzipielles Timingdiagramm fur die Kommunikation
zwischen Ramcontroller und RAM. . . . . . . . . . 27Bild 15 Prinzip der Taktsignalerzeugung aus einem
Grundtakt . . . . . . . . . . . . . . . . . . . . . . . . . 29Bild 16 Vollstandiges Timingdiagramm fur die
Kommunikation zwischen Rechenfeld undRamcontroller . . . . . . . . . . . . . . . . . . . . . . . 30
Bild 17 Vollstandiges Timingdiagramm fur dieKommunikation zwischen Ramcontroller undInterface . . . . . . . . . . . . . . . . . . . . . . . . . . 32
Bild 18 Vollstandiges Timingdiagramm fur dieKommunikation zwischen Ramcontroller undRam. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Bild 19 Resultiernder Verlauf der globalen Taktsignale vonPAr2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
iv

Bild 20 An der Grenze zwischen positiver getriggerter undnegativ getriggerter Logik wirken zwei Register wieeineinhalb. . . . . . . . . . . . . . . . . . . . . . . . . . 37
Bild 21 Registermodell von PAr2 . . . . . . . . . . . . . . . . 39Bild 22 Blockschaltbild mit Verteilung der globalen Signale
sowie der Adressen der FPGAs . . . . . . . . . . . 45Bild 23 Phyikalische Verdrahtung der lokalen Verbindungen
der FPGAs auf dem Rechendfeld. . . . . . . . . . . 46Bild 24 Mogliches Verdrahtungsschema der FPGAs des
Rechenfeldes mit konstanten Leitungslangen. . . 48Bild 25 �-Tiefpaßfilter in den Versorgungsleitungen . . . 52Bild 26 Zusatzlicher Filter in der Stromversorungsleitung
des Grundtaktoszillators . . . . . . . . . . . . . . . . 52Bild 27 Thevenin-Terminierung eines Gatterausgangs . . . 53Bild 28 Schaltplan des Rechenfeldes . . . . . . . . . . . . . 65Bild 29 Pinbelegung eines Rechenfeld-FPGAs (Sicht
entsprechend dem XILINX-Tool XACT) . . . . . . . 66Bild 30 Pinbelegung eines Rechenfeld-FPGAs . . . . . . . 67Bild 31 Schaltplan des Ramcontrollers . . . . . . . . . . . . 71Bild 32 Pinbelegung eines Ramcontroller-FPGA (Sicht
entsprechend dem XILINX-Tool XACT) . . . . . . . 72Bild 33 Pinbelegung eines Rechenfeld-FPGAs . . . . . . . 73Bild 34 Pinbelegungen der DIL-Sockel der Ramcard . . . 77Bild 35 Schaltbild der Ramcard I . . . . . . . . . . . . . . . . 78Bild 36 Schaltbild des Program&Readback Buffer . . . . . 80Bild 37 Lage der GPBUS Jumper im Jumperfeld . . . . . . 81Bild 38 Layout der Interface-Adapter-Platine . . . . . . . . 82Bild 39 Schaltbild des Interface-Adapters . . . . . . . . . . 83Bild 40 Meßpunkte des Interface-Adapters . . . . . . . . . 84Bild 41 Teilschaltbild Taktsignalverteilung . . . . . . . . . . . 85Bild 42 Schaltbild der General-Purpose-Bus-Verteilung . . 86
v

Tabellenverzeichnis
Tabelle 1 Signalbezeichnungen im Rechenfeld-FPGA . . . . 40Tabelle 2 Signalbezeichnungen im Ramcontroller-FPGA . . 41Tabelle 3 Signalbezeichnungen im Ramcontroller-FPGA . . 41Tabelle 4 Pinbelegung Rechenfeld CN1 . . . . . . . . . . . . . 68Tabelle 5 Pinbelegung Rechenfeld CN2 – CN7 . . . . . . . . 69Tabelle 6 Pinbelegung Ramcontroller CN1 . . . . . . . . . . . 74Tabelle 7 Pinbelegung Ramcontroller CN2 . . . . . . . . . . . 75Tabelle 8 Pinbelegung Ramcontroller CN3, CN4 . . . . . . . 76Tabelle 9 Pinbelegung Interface-Adapter CN1 . . . . . . . . . 87Tabelle 10 Pinbelegung Interface-Adapter CN2 . . . . . . . . . 88Tabelle 11 Pinbelegung Interface-Adapter CN3 . . . . . . . . . 89Tabelle 12 Pinbelegung Interface-Adapter CN4 . . . . . . . . . 89Tabelle 13 Pinbelegung Interface-Adapter CN5 . . . . . . . . . 89Tabelle 14 Pinbelegung Meßstecker Typ A . . . . . . . . . . . . 90Tabelle 15 Pinbelegung Meßstecker Typ B . . . . . . . . . . . . 90
vi

Hiermit versichere ich an Eides statt, daß ich diese Arbeit selbst und nur mit
den angegebenen Hilfsmitteln angefertigt habe.
Saarbrucken, den 17.3.1993
(Tobias Blickle)
vii

Kapitel 1 Einfuhrung
1 Einfuhrung
Viele Probleme der Datenverarbeitung, besonders im Bereich der Signalverar-
beitung, erfordern heute Datenraten und Rechenleistungen, die von herkommlichen
sequentiellen Rechnern nicht bereitgestellt werden konnen. Zwar wurden in letzter
Zeit immer wieder Leistungssteigerungen durch Vergroßern der Packungsdichte
und Erhohung der Taktfrequenz erreicht, aber hier sind bereits die physikalischen
Grenzen der Miniaturisierung und Frequenzsteigerung absehbar. Selbst bei weite-
ren Leistungssteigerungen waren die Rechenleistungen fur Echtzeitanwendungen
wie Bilddatentransformation nicht ausreichend. Deshalb sucht man seit langerem
nach anderen Moglichkeiten, die Leistungsfahigkeit von Rechnern zu erhohen.
Den Schlussel dazu liefert die Parallelisierung, denn dadurch konnen von meh-
reren Prozessoren Teilaufgaben gleichzeitig gelost werden, was eine deutliche
Leistungssteigerung mit sich bringen kann.
Dabei werden zwei unterschiedliche Wege in der Ausfuhrung paralleler Pro-
gramme beschritten.
Eine Moglichkeit, die parallelisierten Probleme berechnen zu lassen, stel-
len frei programmierbare Parallelrechner dar. Dabei sind mehrere Prozessoren
durch ein festes Netz verbunden. Die Prozessoren selbst arbeiten ein Programm
sequentiell mit Hilfe eines Befehlssatzes ab, der auf die Probleme der parallelen
Verarbeitung zugeschnitten ist. Spezielle Compiler passen den Algorithmus an die
Hardware an. Sie sind dafur verantwortlich, wie gut die vorhandene Hardware
genutzt wird. Diese Parallelrechner sind wegen ihrer freien Programmierbarkeit
fur unterschiedliche Probleme leicht anpaßbar. Ihr Parallelitatsgrad ist allerdings
durch die Anzahl der vernetzten Prozessoren beschrankt.
Ein anderer Weg wird bei der Herstellung von algorithmisch spezialisierten
parallelen Schaltungen gegangen. Dabei wird fur jedes Problem ein spezieller
Chip entwickelt. Dadurch lassen sich im allgemeinen noch hohere Verarbeitungs-
geschwindigkeiten als bei Parallelrechnern erreichen, denn es konnen nicht nur die
einzelnen Teilprozessoren parallel arbeiten, sondern jeder Prozessor kann intern
parallel aufgebaut sein. Außerdem kann die Verbindungsstruktur der Prozessoren
auf dem Chip fur jeden Algorithmus angepaßt werden.
Beiden Verfahren ist zu eigen, daß die notigen Umformungen am Algorith-
mus, um ihn an einen Parallelrechner oder an einen Chip anzupassen, sehr kom-
plex sind. Wegen der einfachen Programmierbarkeit haben die Parallelrechner
den Vorteil, daß das Ergebnis der Umformung schnell auf einem solchen Rechner
verifiziert werden kann. Bei algorithmisch spezialisierten Schaltungen ist dage-
gen erst die Fertigung eines Prototyps notig, wenn man nicht auf Simulationen
1

Kapitel 1 Einfuhrung
angewiesen sein will. Eine solche Chipherstellung dauert mehrere Wochen und
ist sehr kostspielig.
Besonders im Bereich der Forschung und Entwicklung von parallelen Schal-
tungen ist deshalb ein System von Interesse, das wie die Parallelrechner einfach
und beliebig oft programmiert werden kann, dessen Prozessoren sich aber selbst
noch spezifizieren lassen, um die Parallelitat optimal auszunutzen. So lassen sich
die langen Wartezeiten und hohen Kosten, die durch die Fertigung eines Chip-
Prototypen entstehen, umgehen. Außerdem wird es moglich, einen schnellen
Uberblick uber die entwickelte Schaltung zu bekommen und sie fruhzeitig in der
Anwendungsumgebung zu testen.
Ein solches System stellen programmierbare Rechenfelder dar. Sie basieren
auf FPGAs (Field-Programmable Gate-Array), die eine Weiterentwicklung der
bekannten PLAs (Programmable Logic Array) darstellen. FPGAs sind nicht
nur in der Lage, kombinatorische Schaltungen zu realisieren, sondern stellen
auch intern Flipflops, programmierbare Verdrahtung und programmierbare Ein-
/Ausgabepins zur Verfugung. Außerdem sind sie wie ein RAM beschreibbar, d.h.
die momentane Konfiguration kann einfach uberschrieben werden, ohne daß ein
Loschen wie bei einem EPROM notig ware.
Mehrere dieser FPGAs sind bei einem programmierbaren Rechenfeld zu einem
Netz verbunden. Die Verbindungen der Teilprozessoren (FPGAs) sind somit zwar
starr vorgegeben, aber die FPGAs selbst lassen intern eine Parallelisierung und
Spezialisierung zu.
Diese Vorteile werden bereits in mehreren Architekturen ausgenutzt, die unter
dem Schlagwort “Rapid Prototyping” zusammengefaßt werden. Beispiele hierfur
sind Splash [4], Anyboard [9] oder ein Prototyping-System fur Steuerungsaufga-
ben [6].
Da der Lehrstuhl sich mit der Synthese algorithmisch spezialisierter Schal-
tungen befaßt, besteht ein Interesse an einem programmierbaren Rechenfeld. Die
Entwicklung und Realisierung eines solchen Rechenfeldes erfolgt im Rahmen des
Projekts PAr2 (Prototyping Array for Parallel Architecture). Es soll an das Ent-
wurfssystem COMPAR angeschlossen werden, das zur Abbildung von Algorith-
men auf Schaltungen dient. Die damit erzeugten Algorithmen sollen auf diesem
Rechenfeld abgearbeitet und getestet werden konnen.
Neben der Hardware des eigentlichen Rechenfeldes wird fur den Einsatz eines
solchen Systems ein Interface zum Anschluß an einen Hostrechner, sowie Soft-
ware benotigt, die eine Programmierung des Rechenfeldes gestattet. Die Entwick-
lung und Realisierung der Hardware fur PAr2 war Aufgabe dieser Diplomarbeit.
2

Kapitel 2 Einbettung
2 Einbettung
Dieses Kapitel bettet das Projekt PAr2 und diese Diplomarbeit in die Lehr-
stuhlarbeit ein.
Wie in der Einleitung kurz erwahnt, ist der Entwurf eines algorithmisch spezia-
lisierten Chips sehr komplex. Es mussen diverse Transformationen durchgefuhrt
werden, die den Algorithmus naher an eine Schaltung heranfuhren, die Semantik
aber nicht verandern. Um einen Entwurf effizient zu halten, ist eine Computer-
unterstutzung sinnvoll.
Normalerweise ist die Formulierung eines Algorithmus in sequenzieller Form
gegeben. Ein erster Schritt, einer Schaltungsrealisation naherzukommen, ist des-
halb die Parallelisierung des Algorithmus. Die Probleme, die mit einer Automati-
sierung dieser Parallelisierung zusammenhangen, sind ein Teil der Lehrstuhlarbeit.
Ein weiterer Schwerpunkt der Arbeiten ist, fur eine Algorithmenklasse ein
Entwurfssystem zu erstellen, das die notwendigen Schritte zur Abbildung eines
(bereits parallelisierten) Algorithmus auf eine Schaltung durchfuhrt, indem es dem
Entwickler eine Reihe von Transformationstools zur Verfugung stellt.
Dabei beschrankt man sich auf eine spezielle Klasse von Algorithmen, die Pro-
blemstellungen aus dem Bereich der linearen Algebra behandeln, den sogenannten
stuckweisen linearen Algorithmen (Piecewise Linear Algorithms). Zu ihnen zah-
len Algorithmen der Signalverarbeitung wie FIR-Filter (Finite Response Filter),
der Bildverarbeitung (z.B. Bilddatenkompression) oder direkte Anwendungen aus
der linearen Algebra wie Matrizenmultiplikation.
Um die parallele Form des Algorithmus beschreiben zu konnen, wurde fur
diese Klasse von Algorithmen die Sprache LIRAN entwickelt, die auf der von
Chandy und Misra entwickelten parallelen Programmnotation UNITY [2] aufbaut.
Formal lassen sich diese Algorithmen wie folgt charakterisieren:
• Es existieren nur Anweisungen zwischen linear indizierten Variablen.
• Jeder dieser Anweisungen ist ein Gultigkeitsraum im Indexraum zugeordnet.
• Jede Variable steht nur einmal auf der linken Seite einer Gleichung (Single
Assignment Bedingung).
• Es existiert eine zeitliche Reihenfolge der Anweisungen, so daß jeder Va-
riablen, die auf der rechten Seite einer Anweisung auftaucht, vorher schon
einmal ein Wert zugewiesen wurde (Berechenbarkeit).
3

Kapitel 2 Einbettung
2.1 COMPAR
Das Projekt COMPAR (Compiler for Massive Parallel Architectures) ist ein
Entwurfssystem, um stuckweise lineare Algorithmen auf Schaltungen abzubilden
[1].
Ausgehend von einer Beschreibung des Algorithmus in LIRAN soll der Al-
gorithmus aus der anfanglichen hardwarefernen Darstellung in eine hardwarenahe
Darstellung gebracht werden. Dazu sind eine ganze Reihe von Transformatio-
nen notig, die aber das Ein-/ Ausgangsverhalten des Algorithmus nicht verandern
durfen. Das Lokalisierungstool beispielsweise dient dazu, globale Datenabhangig-
keiten in lokale umzuwandeln [10]. Globale Abhangigkeiten entsprachen langen
Verbindungen auf dem Chip, die lange Signallaufzeiten und Platzprobleme mit
sich brachten und deshalb unerwuscht sind. Weitere Beispiele fur Transformatio-
nen sind die Generierung der Steuerung [12], die Zuordnung einer Zeitrichtung
(Scheduling) oder die Partitionierung [13]. Die Parititionierung ist besonders im
Hinblick auf das Rechenfeld von Interesse, denn sie ermoglicht es, den Algo-
rithmus an die vorgegebenen Ressourcen anzupassen. Hierauf wird genauer in
Kapitel 3.3 und 4.4 eingegangen.
Wurden alle erforderlichen Transformationen durchgefuhrt, ist beispielsweise
eine Ausgabe des Algorithmus in einer hardwarenahen Beschreibungssprache
(VLSI-OCCAM) moglich. Die Ausgabe in VLSI-OCCAM ermoglicht die Si-
mulation des Algorithmus auf einem Transputer. Sie dient aber auch als Aus-
gangspunkt, um die endgultige Realisierung auf einem Chip zu ermoglichen. Die
notigen Anpassungen werden dabei von dem ebenfalls am Lehrstuhl entwickelten
Transformationstool O2H (Occam to Hardware) vorgenommen.
Die Anbindung an das programmierbare Rechenfeld PAr2 soll ebenfalls uber
eine hardwarenahe Beschreibungssprache erfolgen. Allerdings ist dazu ein wei-
terer Schritt notwendig, der den Algorithmus auf die Register-Transfer-Ebene
(Register-Transfer-Level, RTL) umformt.
Da COMPAR zur Zeit noch in Entwicklung ist, sind noch nicht alle angespro-
chenen Transformationen verfugbar. Implementiert sind bisher nur die Datenein-
und -ausgabe in LIRAN, die Occamausgabe und die Lokalisierung.
2.2 PAr2
Das Projekt PAr2 soll ein programmierbares Rechenfeld zur Verfugung stellen,
um die mit COMPAR erzeugten Algorithmen in Echtzeit ablaufen lassen zu
konnen.
Dazu muß auf der Hardwareseite eine ausreichende Rechenkapazitat - also
genugend Gatteraquivalente bei moglichst hoher Taktfrequenz - vorhanden sein.
4

Kapitel 2 Einbettung
Die Hardware muß schnell, einfach und beliebig oft programmierbar sein. De-
buggingmoglichkeiten sollten vorgesehen sein. Ebenso sollte auf dem Rechenfeld
lokal ausreichend RAM vorhanden sein, um speicherintensive Algorithmen reali-
sieren zu konnen, ohne Zwischenergebnisse zwischen Host und Rechenfeld hin-
und hertransportieren zu mussen.
Neben dem eigentlichen Rechenfeld muß eine Anbindung an das Rechner-
system (Sparcstations) uber ein Interface erfolgen. Dazu dient das PSI-Interface
(Programmable SBus Interface), das hostseitig an den SBus der Sparcstations
angeschlossen wird. Die andere Seite des Interfaces stellt eine beliebig program-
mierbare Schnittstelle zu Verfugung, die nicht nur zum Anschluß von PAr2 ver-
wendet werden kann, sondern auch fur andere Projekte des Lehrstuhls verwendet
werden soll (siehe [8]). Die Programmierung dieser Schnittstelle fur PAr2 wurde
in der Diplomarbeit von Patrik Knapp ausgefuhrt [7].
Als weiterer Schritt zur vollstandigen Anbindung eines Rechenfeldes an
COMPAR muß softwareseitig die Lucke zwischen RTL-Beschreibung des Al-
gorithmus und der Gatterebene geschlossen werden, auf der PAr2 arbeitet.
Ist die vollstandige Anbindung des Rechenfeldes an COMPAR gelungen,
so stellt PAr2 eine flexible Hardware zur Verfugung, um parallele Algorithmen
abzuarbeiten. Neben der Verifizierung von Chipentwurfen ware in einem nachsten
Schritt die Einbindung dieser Hardware uber Funktionsaufrufe am Host denkbar,
die automatisch den entsprechenden Algorithmus im Rechenfeld programmieren
und abarbeiten. Auf diese Weise ließe sich PAr2 als ein "Coprozessor fur parallele
Algorithmen" an konventionellen Rechnersystemen einsetzen.
2.3 Aufgabenstellung der Diplomarbeit
Im folgenden Kapitel wird zunachst das Grundkonzept von PAr2 vorgestellt,
das in enger Zusammenarbeit mit Prof. Dr.-Ing. Lothar Thiele, Dipl.- Inform.
Joachim Konig sowie Patrik Knapp entstanden ist.
In Kapitel 4 wird der erste Themenschwerpunkt der Diplomarbeit erlautert,
der sich mit den gewahlten Kommunikationsmethoden des Rechenfeldes befaßt.
Neben der Beschreibung dieser Kommunikation wird ein Registermodell der
Hardware vogestellt. Dieses Modell ist besonders fur COMPAR wichtig, da es
die Restriktionen vorgibt, die von jedem Algorithmus erfullt werden mussen,
damit er auf der Hardware lauffahig ist. Mit Hilfe dieses Registermodells und
der Einfuhrung von einheitlichen Signalbezeichnungen innerhalb der FPGAs wird
es auch moglich, eine Beschreibung der Kommunikation abstrahiert von der
tatsachlichen physikalischen Realisation zu finden.
Der zweite Themenschwerpunkt wird in Kapitel 5 behandelt und stellt die
Hardware von PAr2 vor und geht auf die Probleme bei der Realisation ein.
5

Kapitel 3 Konzept von PAr2
3 Konzept von PAr2
In diesem Kapitel soll nun das Konzept von PAr2 dargelegt werden. Nach
kurzer Vorstellung der verwendeten FPGA-Bausteine und des Interface werden die
Anforderungen an das Rechenfeld zusammengefaßt. Im Anschluß wird daraus
das Konzept von PAr2 entwickelt.
3.1 Xilinx FPGAs
Das gesamte Konzept von PAr2 basiert auf den XILINX FPGAs der XC4000
Serie [15]. FPGA steht fur Field-Programmable Gate Array, frei ubersetzbar mit
"programmierbarem Logikchip". Mit ihnen lassen sich die Vorteile von VLSI
Schaltungen nutzen, ohne jedoch fur jede Anwendung einen speziellen Chip
konventionell herstellen zu mussen. Die Chips werden programmiert, indem man
die Konfigurationsdaten in den internen Speicher ladt. Dies kann entweder vom
Chip selbstandig aus einem EPROM erfolgen oder durch Laden eines Bitstroms
von einem Host aus. Sind die Daten geladen, kann die Schaltung mit einer
Taktfrequenz von bis zu 50-60 MHz betrieben werden. Dies gilt allerdings nur
bei geringer Auslastung des FPGAs und entsprechend optimaler Verdrahtung;
Praxiswerte bei hoher Chipauslastung und komplexen Routing liegen eher bei
10–20 MHz. Da ein FPGA beliebig oft programmiert werden kann, stellen sie
die idealen Bausteine zur Realisierung eines programmierbaren Rechenfeldes dar.
Die FPGAs lassen sich in drei Grundblocke aufteilen: Ein- /Ausgabe-Blocke
(Input-Output-Blocks, IOBs), konfigurierbare Logikblocke (Configurable Logic
Blocks, CLBs) und programmierbare Verbindungen (programmable Interconnect).
Die CLBs sind regelmaßig in einem quadratischen Feld auf dem Chip verteilt. An
den Randern des Chips befinden sich die IOBs. In den Zwischenraumen liegen
die Verdrahtungskanale mit den Verbindungsleitungen, an die die CLBs und IOBs
angeschlossen werden konnen (Bild 1).
Die IOBs bilden die Schnittstelle zwischen Chip und Außenwelt. Jedem
frei verfugbarem Datenpin ist ein IOB zugeordnet, der den Pin als Eingang
oder Ausgang konfigurieren kann. Da der Ausgang uber einen Tristate-Treiber
hochohmig geschaltet werden kann, sind auch bidirektionale Pins realisierbar.
Außerdem konnen sowohl im Eingangs-, als auch im Ausgangspfad ein Register
zwischengeschaltet werden (vgl. Bild 2).
Die CLBs stellen die eigentliche Schaltungslogik zur Verfugung. Sie besteht
im wesentlichen aus zwei programmierbaren Funktionsgeneratoren F und G mit
jeweils vier Eingangen und einem Ausgang (vgl. Bild 3). Sie bestimmen ihren
Funktionswert uber eine Look-Up-Table, d.h. uber ein vier Bit breites und
6

Kapitel 3 Konzept von PAr2
IOB
CLB
Verdrahtungs-kanale
Bild 1 Schematischer Aufbau eines XILINX FPGA
ein Bit tiefes ROM, in dem der Funktionswert zu jeder Eingangskombination
gespeichert ist. Die Ausgange der Funktionsgeneratoren konnen zusammen mit
einem weiteren externen Signal als Eingange fur den Funktionsgenerator H dienen.
Außerdem befinden sich in jedem CLB zwei Flipflops, deren Eingange von den
Ausgangen der Funktionsgeneratoren F, G oder H oder direkt von dem externen
Signal C2 gespeist werden konnen. Als Ausgange eines CLBs existieren die
Ausgange der Flipflops und zwei weitere Leitungen, die mit den Ausgangen der
Funktionsblocke F, G und H verbunden werden konnen.
Alle Flipflops der FPGA ubernehmen die Daten mit steigender Taktflanke.
Neben dieser Grundfunktion verfugt jeder CLB uber eine Fast Carry Logic,
sowie uber eine Moglichkeit, die Funktionsgeneratoren F und G als 16*1 Bit
RAM zu verwenden. Auf diese Moglichkeiten soll hier nicht weiter eingegangen
werden, da sie fur das Verstandnis der Arbeitsweise von PAr2 nicht erforderlich
sind. Genauere Informationen lassen sich in [15] nachlesen.
Das dritte Grundelement der FPGAs stellen die programmierbaren Verbin-
dungen dar. Es existieren dabei unterschiedliche Typen von Verbindungsleitun-
gen: Die "Single-Length Lines" verbinden direkt benachbarte CLBs, wahrend
"Double-Length Lines" immer ein CLB uberspringen. Fur großere Entfernung
7

Kapitel 3 Konzept von PAr2
Q
SD
RDEC
D
Q
SD
RDEC
D
M
M
OUT DATA
OUT CLOCK
M
M
M Q L
M
M
M
IN CLOCK
IN2
IN1
OUTPUT ENABLE
PAD
Pullup
Pulldown
invert
invert
invert
invert
M Multiplexer konfigurierbar bei Programierung
Bild 2 Vereinfachter Input-/Output Block (IOB) der FPGAs.
sind die "Global Longlines" pradestiniert, die mit Tristate-Treibern angesteuert
werden konnen. “Global Nets” sind fur die Verteilung von Taktsignalen konzi-
piert. Sie sind mit besonderen internen Treibern versehen (Global Primary Buffer
und Global Secondary Buffer) und erlauben es, zeitkritische Signale auf dem Chip
zu verteilen, da sie zu jedem Flipflop im Chip eine garantierte Laufzeit unter funf
Nanosekunden haben. Insgesamt stehen acht solcher Leitungen pro Chip zur
Verfugung; eine dieser Leitungen wird zum Verteilen des globalen Taktes ver-
wendet. Die Verbindungen zwischen den unterschiedlichen Leitungen erfolgen
uber sogenannte "Switch Matrices".
Der Programmiervorgang besteht nun darin, die Funktion der einzelnen Funk-
tionsblocke der CLB festzulegen, sowie die Art und Weise wie ihre Ausgange ver-
schaltet sind. Ebenso werden beim Programmieren die Konfiguration der IOBs
geladen und die Verbindungen zwischen den CLBs festgelegt, d.h. die Switch
Matrices programmiert.
Als Besonderheit bieten die XILINX FPGAs die Moglichkeit, den internen
Zustand auszulesen. Dies geschieht uber das READBACK. Zu einem beliebigen
Zeitpunkt kann mittels des Signals RDBK.TRIG das FPGA veranlaßt werden,
die Daten mit der durch RDBK.CLK vorgegebenen Geschwindigkeit uber den
Pin RDBK.DATA auszugeben. Dabei werden nicht nur die Daten uber die
8

Kapitel 3 Konzept von PAr2
S/RCONTROL
S/RCONTROL
C1 C2 C3 C4
G1
G2
G3
G4
F1
F2
F3
F4
K
(clock)
H1 DIN S/R EC
G’
F‘
G’
H’
G’
H’
G’
H’
H’
F’
DIN
DIN
F’
Q
SD
RDEC
D YQ
XQQ
SD
RDEC
D
1
1
Y
X
Logic
Function
of
G1-G4
Logic
Function
of
F1-F4
Logic
Function
of
F’,G’
and
H1
H’
F’
Bild 3 Configurable Logic Block (CLB) der FPGAs.
programmierte Funktion ubertragen, sondern auch der Zustand der Register in
den IOBs und CLBs.
Beim Aufbau von PAr2 wurden FPGAs vom Typ XC4005 verwendet. Sie
verfugen uber eine Gatteraquivalent von ca 5000 in 14 * 14 = 196 CLBs. In einem
156poligen Grid-Array stellen sie 112 frei verfugbare IOPins und ebensoviele
IOBs zur Verfugung. Insgesamt befinden sich in den CLBs und IOBs zusammen
616 Flipflops. Durch Ausnutzung der Funktionsgeneratoren als Speicher konnen
maximal 6272 Bit RAM auf einem Chip realisiert werden.
3.2 Interface
Das Interface, das am Lehrstuhl entwickelt wird, soll die Moglichkeit bieten,
unterschiedlich parallele algorithmische und semialgorithmische Prozessoren an
SPARC-Stations anzuschließen. Bild 4 zeigt das Prinzipschaltbild. Uber einen
Buscontroller ist ein FPGA an den SBus der SPARC-Station angeschlossen, das
die Kommunikation mit dem Host steuert. Zwei getrennte 32 Bit breite FIFOs —
eins fur die Lese-, eins fur die Schreibrichtung — puffern die zu ubertragenden
Daten, die an zwei weitere FPGAs gefuhrt werden. Von jedem dieser FPGAs
sind 60 Pins auf eine Steckerleiste gelegt, deren Bedeutung frei programmierbar
ist, je nach der in den FPGAs realisierten Schaltung. Es stehen also insgesamt
120 Pins zur Verfugung.
9

Kapitel 3 Konzept von PAr2
In seiner momentanen Realisierung erreicht das Interface eine Ubertragungs-
rate von maximal 8 MByte/s.
DM
A-C
on
tro
ller
Forth-
Code
Data/
Address
Address
Control
16
8
8
Serial
Prom
Serial
Prom
Xilinx XC4005PG156Transfer-Agent
SBus-FIFO
Configuration
32
SB
us-
Con
nec
tor
Data
Xilinx XC4005PG156Write-ControlApplic.-FIFO
Xilinx XC4005PG156Read-ControlApplic.-FIFO
FIFO Write
FIFO Read
Control
Data
Data
32
32
8
8
Control
Control
Control
Control
status
status
pro
gra
mm
ab
le I
/O-P
ins
pro
gra
mm
ab
le I
/O-P
ins
Control
Control
Bild 4 Blockschaltbild des PSI-Interface
3.3 Anforderungen
Das Rechenfeld soll fur den implementierten Algorithmus1 sozusagen das
Gehause zur Verfugung stellen, d.h. mehrere FPGAs und das RAM sowie die
Datenein- und -ausgabe so verfugbar machen, daß moglichst wenig Ressourcen
der FPGAs verloren gehen. Die Moglichkeiten, die sich durch die Transfor-
mationstools in COMPAR ergeben, sollten gewinnbringend in der Konzeption
eingesetzt werden.
Insgesamt ergeben sich folgende Anforgerungen an das Rechenfeld:
• Es muß eine ausreichende Anzahl von Gatteraquivalenten zur Verfugung
stellen.
• Die Anordnung der FPGAs als Teilprozessoren soll regelmaßig sein. Ziel der
Chipentwicklung ist es, eine regelmaßige Realisierung zu erreichen.
• Die einzelnen FPGAs sind uber lokale Busse miteinander verbunden. Lo-
kale Verbindungen direkt benachbarter FPGAs sind ausreichend, da mit dem
Lokalisierungstool von COMPAR globale Datenabhangigkeiten im implemen-
tierten Algorithmus aufgelost werden konnen. Uber diese Verbindungen ge-
langen sowohl die Rechendaten als auch die Steuerdaten, die Information
uber den momentanen Zustand im implementierten Algorithmus reprasentie-
ren. Zwischen diesen Daten besteht kein qualitativer Unterschied, denn durch
1 Im weiteren bezeichnet der kursiv gedruckte Ausdruck implementierter Algorithmus, die Schaltung (Algorithmus),die auf dem Rechenfeld ablaufen soll.
10

Kapitel 3 Konzept von PAr2
die Generierung einer Steuerung mittels COMPAR lassen sich Steuersignale
wie normale Daten behandeln.
• Die Kommunikation mit dem Host erfolgt am Rand des Rechenfeldes. Dies
ergibt sich praktisch direkt aus der Lokalitat des Algorithmus. Außerdem
erlaubt eine Chiprealisierung des Algorithmus nur Anschlusse am Rand der
Chipflache. Entsprechend ist es sinnvoll, bei einem Rechenfeld analog zu
verfahren.
• Es sollte moglichst viel RAM auf dem Rechenfeld vorhanden sein, um Daten
speichern zu konnen, ohne den Umweg uber den Host nehmen zu mussen,
was viel Zeit in Anspruch nehmen wurde. Die von den FPGAs von XILINX
zur Verfugung stehenden ca. 6k RAM sind nicht ausreichend fur speiche-
rintensive Algorithmen. Außerdem ist dieses RAM nur gegen Verzicht auf
Logikblocke erhaltlich, d.h. es bleiben fur die Kombinatorik der Schaltung
weniger Gatteraquivalente ubrig.
Hauptverwendungszweck des RAMs wird das Speichern von Daten sein, die
durch die Partitionierung anfallen. Eine Partitionierung ist deshalb notig,
weil der implementierte Algorithmus in den seltensten Fallen genau auf das
Rechenfeld “paßt”, d.h. der implementierte Algorithmus muß auf die durch
das Rechenfeld vorgegebenen Ressourcen abgebildet werden [13].
Die Partitionierung besteht in einem Aufteilen des Algorithmus in mehrere
Teilalgorithmen, wobei zwei grundsatzliche Methoden unterschieden werden
konnen. Arbeiten alle Prozessoren des Rechenfeldes parallel an einem Teil-
algorithmus, und die Teilalgorithmen werden sequentiell nacheinander abge-
arbeitet, spricht man von einer Partitionierung nach dem LPGS-Verfahren
(locally parallel, globally sequential). Hierbei wird wird zum Speichern der
Zwischenergebnisse Speicher am Rand des Prozessorfeldes benotigt, um Da-
ten uber mehrer Teilalgorithmen hinweg auszutauschen. Die zweite Methode
ist die LSGP-Partitionierung (locally sequential, globally parallel): Hier arbei-
tet jeder Prozessor einen Teilalgorithmus sequentiell ab, alle Teilalgorithmen
aber werden parallel ausgefuhrt. Dabei benotigt jeder Prozessor seinen eige-
nen Speicher, um die Daten des Teilalgorithmus zu speichern.
Fur eine LSGP-Partitionierung mußte jedem FPGA eigenes RAM zur Verfu-
gung gestellt werden. Damit wurden viel Ressourcen des FPGAs verbraucht,
denn es werden sowohl viele Pins fur die Adressierung und den Datentransfer
zum RAM benotigt, als auch CLBs fur eine Ansteuerschaltung des RAMs.
Da die Kommunikation mit dem Host sowieso eine Sonderbehandlung am
Rand des Rechenfeldes erfordert, geht man davon aus, daß nach dem LPGS-
Verfahren partitioniert wird und somit der Speicher ebenfalls an den Rand
gelegt werden kann.
• Das Rechenfeld soll zweidimensional sein. Diese Vorgabe liegt hauptsach-
lich in der dadurch erreichbaren hoheren Parallelitat begrundet. Außerdem
11

Kapitel 3 Konzept von PAr2
sind zweidimensionale Rechenfelder seltener vertreten und somit weniger gut
untersucht als eindimensionale Anordnungen.
• Die Kommunikation erfolgt synchron. Der Grund hierfur ist der wesentlich
geringere Hardwareaufwand einer synchronen Kommunikation gegenuber ei-
ner asynchronen, die zusatzliche Quittierungsleitungen benotigt. Die Nach-
teile der synchronen Kommunikation sind die Taktverschiebung bei großen
Entfernungen, sowie die Stromspitzen durch das gleichzeitige Schalten der
Elemente.
• Selbstverstandlich soll das Rechenfeld beliebig oft programmierbar sein.
• Debuggingmoglichkeiten sollten so weit wie moglich genutzt werden, da bei
einem experimentellen System jede Form der Uberprufbarkeit willkommen
ist.
• Wunschenswert ist weiterhin eine weitestgehende Modularitat der Hardware,
um sich die Option einer spateren Erweiterbarkeit des Systems offen zu halten.
3.4 Grunduberlegungen
Aus diesen Anforderungen an PAr2 ist das folgende Grundkonzept entstanden.
Das Rechenfeld besteht aus einem quadratischen 3x3 Feld von XILINX
XC4005 FPGAs, die zusammen eine Gatterkapazitat von 45000 Gattern haben.
Die FPGAs sind lokal uber Busse miteinander verbunden und am Rand torusmaßig
geschlossen. Bei 112 I/O Pins der FPGAs und vier benotigten Bussen ergibt sich
eine theoretische Busbreite von 28 Bit. Da SRAMS in Datenbusbreiten von 8 Bit
oder Vielfachen davon ublich sind, wurde als Busbreite 24 Bit gewahlt.
Die Verwaltung des benotigten Speichers am Rand sowie die Kommunika-
tion mit dem Host erfolgt uber FPGAs mit besonderen Steueraufgaben, die in die
Ruckfuhrungen der Rechenfeldverbindungen eingeschleift sind (Ramcontroller-
FPGAs). Sie haben damit die Moglichkeit, die Daten, die das Rechenfeld aus-
tauscht, "mitzuhoren" und zu manipulieren. Da in diesen Daten auch Steuerinfor-
mationen enthalten sind, konnen sie so eine gewunschte Aktion ausfuhren, also
z.B. Daten an den Host schicken bzw. vom Host holen oder Daten ins RAM
schreiben bzw. vom RAM lesen.
Die Aufgaben des Ramcontrollers sollen naher untersucht werden.
Um Daten mit dem Host auszutauschen, ist an jedes Ramcontroller-FPGA
das Interface uber den IFBUS (Interface-Bus) angeschlossen, der sowohl eine
Lese-, als auch eine Schreibrichtung hat. Dies liegt darin begrundet, daß das
Interface bereits getrennt Richtungen fur Lesen und Schreiben vorsieht. Da es
pro Rechenfeldzeile und Rechenfeldspalte jeweils ein Ramcontroller FPGA gibt,
sind an den IFBUS mehrere FPGAs parallelgeschaltet. In Leserichtung (vom
Interface zu den Ramcontrollern) ergibt sich daraus kein Problem, da nur das
12

Kapitel 3 Konzept von PAr2
Interface schreibend auf diesen Teilbus zugreift. In Schreibrichtung sieht das
anders aus, da hier jedes FPGA einen moglichen Datensender darstellt. Dadurch
wird es notig, eine Buskontrolle einzufuhren, die garantiert, daß immer nur ein
Teilnehmer auf den Bus zugreift.
Dafur wurden die unterschiedlichsten Verfahren in Erwagung gezogen. So
ist z.B. eine ubergeordnete Buskontrolle durch das Interface denkbar, das die
Ramcontroller der Reihe nach abfragt und ihnen so die Moglichkeit gibt, ihre
Daten abzusenden (Polling). Eine andere Idee ware, jedem Ramcontroller eine
“Request-Leitung” zum Interface zu legen, mit dem es ihm anzeigt, daß es Daten
senden mochte. Nach Zuteilung der Erlaubnis kann der Ramcontroller den Bus
belegen und seine Daten zum Interface schicken. Dieses Verfahren benotigt so
viele Leitungen am Interface wie es Ramcontroller gibt.
Der Nachteil an diesen Verfahren ist aber, daß der Ramcontroller so seine Da-
ten zwischenspeichern muß, da einige Zeit vergehen kann, bis er den Bus zugeteilt
bekommt. Ein Zwischenspeichern konnte nur entfallen, wenn das Interface in-
nerhalb eines Taktzyklusses des Ramcontrollers den “Sender” ausmachen und die
Daten ubertragen kann. Dies wiederum setzt voraus, daß das Interface (bei sechs
Ramcontrollern) mindestens sechsmal schneller lauft als der Ramcontroller. Zu-
satzlich mußte garantiert werden, daß nicht ein zweiter Ramcontroller zur selben
Zeit Daten sendet, sonst mußte einer von beiden wiederum seine Daten speichern.
Wurde man sich also notgedrungen auf eine Zwischenspeicherung der Daten
einlassen und eine gewisse Zwischenspeichergroße festlegen, mußte man sich
immer noch uberlegen, was passierte, wenn dieser Speicher voll ware. Dann
mußte der Ramcontroller das Rechenfeld anhalten konnen, bis wieder Platz in
seinem Speicher ware. Damit waren zwei Taktleitungen zu den Ramcontrollern
notig: eine, die die Kommunikation mit dem Rechenfeld steuern wurde und
angehalten werden konnte und eine weitere, die die Kommunikation zwischen
Ramcontroller und Interface regeln wurde.
Man sieht, daß diese Uberlegungen zu immer neuen Problemen fuhren. Des-
wegen wurde ein anderes Konzept gewahlt, das die Moglichkeiten von COMPAR
ausnutzt: Um die aufwendige Busarbitrierungsmaßnahmen zu vermeiden, wird
davon ausgegangen, daß jeder Ramcontroller den Zeitpunkt "weiß", wann er den
Bus benutzen darf. Dieses Wissen ist in COMPAR bereits vorhanden, denn die
Arbeitszeitpunkte der Prozessoren sind bekannt und somit auch die Zeitpunkte, an
denen die Ergebnisse der Berechnungen anfallen. Durch Wahl einer Zeitrichtung
in COMPAR (Schedule) ist eine Transformation des Algorithmus so moglich, daß
immer nur ein Ramcontroller zu einer Zeit den Bus benutzt. Dadurch ist die
Buskontrolle in eine hohere Ebene delegiert. Es genugt so, jedem Ramcontroller-
FPGA ein Output-Enable Signal fur seine Bustreiber zur Verfugung zu stellen.
Auf der Gegenseite muß das Interface wissen, wann Daten auf dem Bus gultig
13

Kapitel 3 Konzept von PAr2
sind. Denn es ist durchaus denkbar, daß mehrere Taktzeitpunkte kein Ramcon-
troller Daten zu senden hat. Dieses Problem wird in [7] diskutiert. Prinzipiell
ware es auch moglich, alle Daten einfach an den Host weiterzugeben, und diesen
erst die Unterscheidung treffen zu lassen, ob die Daten gultig oder ungultig sind.
Dies ist aber eine ungunstige Losung, da so viele unnotige Daten zum Host trans-
portiert wurden und der Bus zwischen Interface und Host, der sowieso schon den
Flaschenhals in der Kommunikation darstellt, zusatzlich belastet wurde.
Man benotigt nun zwar immer noch einen Mechanismus, um das gesamte Re-
chenfeld mit Ramcontroller anhalten zu konnen, aber jetzt kann dies das Interface
allein entscheiden. Denn der einzig denkbare Ausloser dafur ist das Uberlaufen
des Schreib-FIFOS bzw. das Leerlaufen des Lese-FIFOs im Interface. Außer-
dem besteht bei dieser Losung die Moglichkeit, andere Arbitrierungsverfahren
nachtraglich durch Programmieren der FPGAs zu realisieren, indem man einige
Leitungen des IFBUS fur diese Zwecke reserviert.
Das RAM ist ebenfalls an den Ramcontroller angeschlossen und soll pro
Taktzyklus sowohl einen Lese- als auch einen Schreibzugriff gestatten. Dies
erlaubt es beispielsweise gleichzeitig Daten vom RAM zum Interface zu senden
und Daten vom Rechenfeld in das RAM zu schreiben.
Insgesamt ergibt sich aus diesen Uberlegungen das in Bild 5 am Beispiel
eines 2x2–Feldes gezeigte Prinzipschaltbild.
Wie dort zu ersehen ist, mussen an ein Ramcontroller-FPGA die Busse
zweier Rechenfeld-FPGAs, Adreß- und Datenbus des RAMs sowie der IFBUS
zur Kommunikation mit dem Interface angeschlossen werden. Die verwendeten
XC4005 FPGAs stellen wie erwahnt 112 I/O-Pins zur Verfugung. Die Ramcon-
troller benotigen bei einer Busbreite von 24 Bit und 64k Adreßraum insgesamt
6*24+2*16=176 Pins. Es sollten aber keine großeren Chips der XC4000–Serie
verwendet werden, da diese erheblich teurer sind. Der Preis steigt hierbei etwa
quadratisch mit der Anzahl der zur Verfugung stehenden CLBs. Nicht unerheblich
ist auch das geometrische Problem, das im Layout entsteht, wenn so viele Leitun-
gen gezogen werden mussen. Es wird auch zunehmend schwieriger, ein Design
zu routen, je großer der Chip ist, da die Ressourcen an Verbindungsleitungen
zwischen den CLBs konstant sind.
Um also den Leitungsbedarf am Ramcontroller zu vermindern, wird ein
Multiplexen auf allen Bussen des Ramcontroller-FPGAs eingefuhrt. Man faßt
dazu die Lese- und Schreibleitungen eines Busses zusammen und benotigt dadurch
nur noch die halbe Anzahl der Leitungen, muß das Lesen und Schreiben dafur
nacheinander innerhalb eines Taktzyklus auf denselben Leitungen durchfuhren.
Die Datenrate auf den Bussen wird dadurch doppelt so hoch wie die Taktrate
von PAr2. Dies begrundet auch den Nachteil des Multiplexens: Da sich die maxi-
male Taktrate im wesentlichen nach der hochsten vorkommenden Datenrate in der
14

Kapitel 3 Konzept von PAr2
Interface-Adapter
Clock-generator
INTERFACE
Rechenfeld
FPGA
Rechenfeld
FPGA
Rechenfeld
FPGA
Rechenfeld
FPGA
Ramcontroller
Ramcontroller
Ram
cont
rolle
r
Ram
cont
rolle
r
Bild 5 Prinzipschaltbild von PAr2 — Kommunikation
Schaltung richtet, fuhrt es zu einer Halbierung der Taktrate des gesamten Rechen-
feldes. Da man auf diese Weise aber eine Halbierung der Anzahl der Leitungen
am Ramcontroller erreicht, ist dieser Nachteil tolerierbar. Dies gilt insbesondere
dann, wenn wahrend der Laufzeit des Algorithmus große Datenmengen vom oder
zum Host transportiert werden mussen. In einem solchen Fall nutzt eine hohere
Taktrate namlich wenig, da die Datenubertragungsrate vom Host bzw. Inter-
face bestimmt wird. Bei hoherer Verarbeitungsgeschwindigkeit des Rechenfeldes
mußte das Rechenfeld nur um so ofter angehalten werden, da der Host nicht mehr
nachkommt, die Daten abzunehmen bzw. bereitzustellen. Außerdem konnen als
RAM nun konventionelle SRAMs eingesetzt werden, die erheblich preisgunstiger
und in großeren Speicherkapazitaten als Dual-Port RAM erhaltlich sind.
Das in Bild 5 gezeigte Prinzipschaltbild stellt also nicht die physikalische
Wirklichkeit dar, wie die Komponenten von PAr2 verbunden sind. Es zeigt
vielmehr das “Prinzip” in dem Sinne, wie die Hardware fur den implementierten
15

Kapitel 3 Konzept von PAr2
Bust
reib
er
RamcontrollerFPGA
Steuerung
Pfad-kontrolle
Adressen
Daten
Daten
Adressen
RA
MSch
reib
enLese
n
Rec
henf
eld-
FP
GA
s
IFB
US
Bild 6 Prinzipschaltbild Ramcontroller zu Bild 5
Algorithmus aussieht. Es ist somit ein “virtuelles” Prinzipschaltbild im Gegensatz
zu den physikalischen Prinzipschaltbildern zur Kommunikation im folgenden
Kapitel (Bild 9, 11 und 13).
Zusatzlich zu diesen prinzipiellen Komponenten gibt es einen globalen Bus
(General Purpose Bus, GPBUS), an dem alle FPGAs des Rechenfeldes und die
der Ramcontroller angeschlossen sind (siehe Bild 7). Obwohl dieser globale
Bus dem eigentlichen Konzept der Lokalitat des Algorithmus widerspricht, wurde
er eingefuhrt, um keine Leitungen an dem FPGA ungenutzt zu lassen. Denn
dadurch, daß die Busbreite auf 24 Bit festgesetzt wurde, sind abzuglich reservierter
Leitungen 10 Leitungen an jedem FPGA frei. Außerdem sind Anwendungen
denkbar, in denen dieser Bus sinnvoll genutzt werden kann. Da dieser Bus auch
zu den sieben nicht benotigen Global Primary bzw. Secondary Buffer (siehe
Kapitel 3.1) fuhrt, konnen hiermit beispielsweise zusatzliche Taktsignale verteilt
werden.
Zur Programmierung von PAr2 mussen die Programmdaten an die einzelnen
FPGAs geleitet werden und sichergestellt werden, daß nur ein FPGA gleichzeitig
programmiert wird. Dies erfolgt uber die Zuordnung einer Adresse zu jedem
FPGA, das nur dann an die Programmierleitungen angeschlossen wird, wenn
die ensprechende Adresse anliegt. Die Programmierung erfolgt dann uber einen
Befehl an das Interface, das die Daten in das entsprechende FPGA leitet.
Um einen Algorithmus debuggen zu konnen, wurde die Moglichkeit des
READBACKS der XILINX FPGAs auch in PAr2 vorgesehen. Mit demselben
Mechanismus wie bei der Programmierung kann ein FPGA angesprochen werden
und der interne Zustand der Register im Chip ausgelesen werden. Die Leitungen
16

Kapitel 3 Konzept von PAr2
zum Programmierung und Debuggen der FPGAs sind zu dem PRBUS (Programm
& Readbackbus) zusammengefaßt.
Rechenfeld
FPGA
Rechenfeld
FPGA
Rechenfeld
FPGA
Rechenfeld
FPGA
Interface-Adapter
Clock-generator
INTERFACE
Tris
tate
buffe
r
Tristatebuffer
FPGA
Tris
tate
buffe
r
FP
GA
Tris
tate
buffe
r
FP
GA
Tris
tate
buffe
r
Tris
tate
buffe
r
Tris
tate
buffe
r
Tristatebuffer
FPGA
PRBUS (Program&Readback)
GP
BU
S (G
eneral Purpose)
Bild 7 Prinzipschaltbild von PAr2 — Programmierung, Readback und globaler Bus.
Aus der beschriebenen Notwendigkeit, die gesamte Hardware von PAr2 an-
halten zu konnen, ergibt sich in Verbindung mit dem READBACK-Mechanismus
eine komfortables Fehlersuchverfahren. So ist es moglich, den Algorithmus im
Einzel-Schritt-Verfahren abzuarbeiten und nach jedem Taktzyklus die internen Zu-
stande der FPGAs auszulesen und zu uberprufen.
17

Kapitel 4 Die Komponenten von PAr2
4 Die Komponenten von PAr2
Die Hauptaufgabe bei der Konzeption und Realisierung von PAr2 bestand
darin, die Kommunikationsmittel fur den implementierten Algorithmus bereitzu-
stellen. Nach der Festlegung des Grundkonzepts im vorangegangenen Kapitel
soll hier im einzelnen beschrieben werden, wie die Kommunikation der Elemente
Rechenfeld, Ramcontroller mit RAM und Interface von PAr2 geregelt ist. Im
Anschluß daran werden die fur diese Kommunikation benotigten Taktsignale ab-
geleitet und deren optimaler Verlauf bestimmt. Kapitel 4.4 befaßt sich mit dem
Registermodell von PAr2. Dieses Modell stellt eine Abstraktion von der physika-
lischen Realisierung der Kommunikation dar und ermoglicht eine Beschreibung
durch fest definierte Schnittstellen an den FPGA-Grenzen. Der letzte Abschnitt
dieses Kapitels befaßt sich mit der Programmierung der FPGAs.
Grundsatzlich geht das Konzept davon aus, daß zu jedem Taktzyklus der
globalen Clock (ComCLK , Communikation CLocK) einmal Daten von jeder
Datenquelle anfallen konnen, also von den FPGAs des Rechenfeldes, des Ram-
controller, vom RAM und vom Interface. Daß in der Regel beim implementierten
Algorithmus nicht in jeden Taktzyklus ein Datum anfallt, stort dabei nicht, denn
die transportierten Daten konnen von dem implementierten Algorithmus einfach
nicht beachtet werden.
Den “Flaschenhals” in der Kommunikation zwischen Host und PAr2 bildet
hierbei sicherlich das Interface. Bei der gewahlten Busbreite von 24 Bit und
einer Kommunikation in beiden Richtungen vom und zum Interface mit einer
Taktfrequenz von 8 MHz fallen am Interface 24*8*2/8 = 48 MB pro Sekunde
an. Dies ist in seiner jetzigen Implementierung vom Interface bei einer Datenrate
von 8MB/s nicht zu bewaltigen, so daß eine Moglichkeit bestehen muß, das
gesamte System von PAr2 vom Interface aus anzuhalten, wenn das Interface die
Daten nicht weiterleiten kann. Dieser Fall kann dabei nicht nur durch den hohen
Datendurchsatz auftreten, sondern ebenso bei Kommunikationsengpassen mit dem
Host.
4.1 Rechenfeld
4.1.1 Aufgabe
Das Rechenfeld besteht aus einem 3x3 Feld von XILINX XC4005 FPGAs
und stellt somit eine Gatterkapazitat von ca 45000 Gattern zur Verfugung. Die
FPGAs sind durch lokale 24 Bit breite Busse miteinander verbunden. Hier soll
der implementierte Algorithmus ablaufen.
18

Kapitel 4 Die Komponenten von PAr2
4.1.2 Kommunikation der Rechenfeld FPGAs untereinander
Die Verbindungen der Rechenfeld-FPGAs untereinander sind unidirektional
und statisch fur den gesamten Ablauf eines Algorithmus. Das ist auch sinnvoll,
denn eine Umkehr des Datentransfers auf einer Leitung wahrend der Laufzeit
des Algorithmus ist ausgeschlossen. Allerdings ist die Richtung des Datenflusses
auf Grund der freien Programmierbarkeit der IOBs der XILINX FPGAs fur jede
Leitung unabhangig von den Richtungen der anderen Leitungen moglich.
Die Kommunikation zwischen zwei benachbarten Rechenfeld FPGAs gestal-
tet sich relativ einfach (Bild 8). An der Datenquelle der Leitung wird das IOB des
entsprechenden FPGAs auf Ausgang mit vorgeschaltetem Register programmiert.
An der Datensenke des anderen FPGAs befindet sich ein auf Eingang program-
miertes Register im IOB. Beide Register, bei der Quelle wie bei der Senke, werden
mit steigender Taktflanke von ComCLK beschrieben. Die Daten haben also eine
Taktperiode von ComCLK Zeit, um von einem FPGA zum anderen zu gelangen.
BIT A
C
D Q
U3
OUTFF
C
D Q
QM
U1
INREG
BIT A
ComCLK ComCLK
BIT B
C
DQ
U4
OUTFF
C
DQ
QM
U2
INREG
BIT B
Rechenfeld FPGA 1 Rechenfeld FPGA 2
Bild 8 Kommunikation zwischen zwei Rechenfeld-FPGAs.
4.1.3 Kommunikation zwischen Rechenfeld und Ramcontroller
In Kapitel 3.4 wurde das Multiplexen aller Leitungen zum Ramcontroller
eingefuhrt, um das Leitungsproblem am Ramcontroller zu losen. Die dafur
notwendige Multiplexschaltung zeigt Bild 9. Der gesamte Mehraufwand an
Hardware gegenuber unidirektionalen Verbindungen kann in den IOBs der FPGAs
untergebracht werden. Sie verfugen bereits uber Tristate-Ausgangstreiber sowie
Ein- und Ausgaberegister innerhalb eines IOBlocks (vgl Bild 2). Es gehen somit
keine CLBs und damit Gatteraquivalente innerhalb der FPGAs verloren.
19
Kapitel 4 Die Komponenten von PAr2
U3
OUTFFT
U7INV
BIT A
C
DQ
QM
U2
INREG
ComCLK
BIT B
ComCLK
C
DQ
QM
U1
INREG
U4
OUTFFT
U8
INV
BIT A
BIT B
ComCLK
U9
INV
U5
OUTFFT
BIT A
BIT A out
BIT A in
C
D Q
QM
U6
INREG
U10
OUTFFT
U12
INVBIT B out
BIT B
C
D Q
QM
U11
INREG
BIT B in
Rechenfeld FPGA 1
Rechenfeld FPGA 2
Ramcontroller
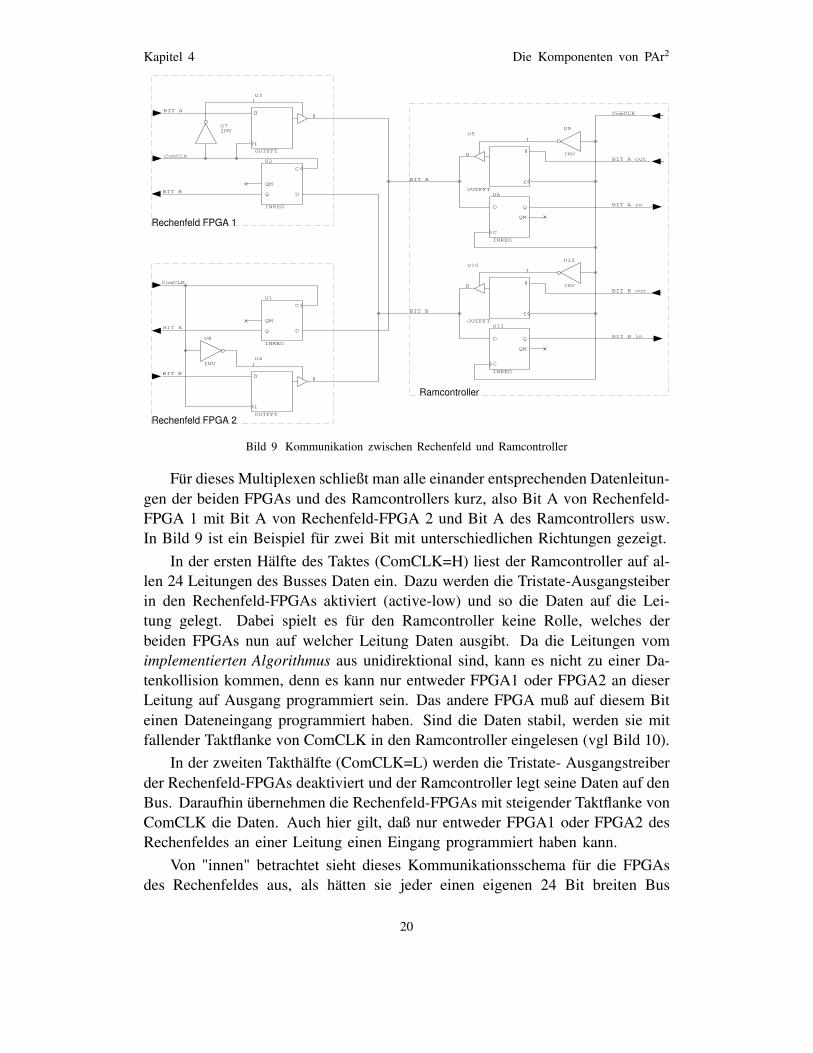
Bild 9 Kommunikation zwischen Rechenfeld und Ramcontroller
Fur dieses Multiplexen schließt man alle einander entsprechenden Datenleitun-
gen der beiden FPGAs und des Ramcontrollers kurz, also Bit A von Rechenfeld-
FPGA 1 mit Bit A von Rechenfeld-FPGA 2 und Bit A des Ramcontrollers usw.
In Bild 9 ist ein Beispiel fur zwei Bit mit unterschiedlichen Richtungen gezeigt.
In der ersten Halfte des Taktes (ComCLK=H) liest der Ramcontroller auf al-
len 24 Leitungen des Busses Daten ein. Dazu werden die Tristate-Ausgangsteiber
in den Rechenfeld-FPGAs aktiviert (active-low) und so die Daten auf die Lei-
tung gelegt. Dabei spielt es fur den Ramcontroller keine Rolle, welches der
beiden FPGAs nun auf welcher Leitung Daten ausgibt. Da die Leitungen vom
implementierten Algorithmus aus unidirektional sind, kann es nicht zu einer Da-
tenkollision kommen, denn es kann nur entweder FPGA1 oder FPGA2 an dieser
Leitung auf Ausgang programmiert sein. Das andere FPGA muß auf diesem Bit
einen Dateneingang programmiert haben. Sind die Daten stabil, werden sie mit
fallender Taktflanke von ComCLK in den Ramcontroller eingelesen (vgl Bild 10).
In der zweiten Takthalfte (ComCLK=L) werden die Tristate- Ausgangstreiber
der Rechenfeld-FPGAs deaktiviert und der Ramcontroller legt seine Daten auf den
Bus. Daraufhin ubernehmen die Rechenfeld-FPGAs mit steigender Taktflanke von
ComCLK die Daten. Auch hier gilt, daß nur entweder FPGA1 oder FPGA2 des
Rechenfeldes an einer Leitung einen Eingang programmiert haben kann.
Von "innen" betrachtet sieht dieses Kommunikationsschema fur die FPGAs
des Rechenfeldes aus, als hatten sie jeder einen eigenen 24 Bit breiten Bus
20

Kapitel 4 Die Komponenten von PAr2
zum Ramcontroller. Auf diesem werden pro Taktperiode von ComCLK genau
einmal (mit steigender Flanke von ComCLK) die Daten aus den Eingangsregister
eingelesen bzw. in die Ausgangsregister geschrieben. Die Rechenfeld-FPGAs
arbeiten also mit der Taktfrequenz von ComCLK.
Der Ramcontroller "sieht" einen 24 Bit breiten bidirektionalen Bus, bei dem
die Leserichtung zu einem, die Schreibrichtung zu dem anderen FPGA des Re-
chenfeldes fuhrt. Welche Richtung zu welchem Rechenfeld-FPGA fuhrt, ent-
scheidet sich erst bei der Programmierung von PAr2 durch Festlegen der Daten-
richtungen in den Rechenfeld-FPGAs. Der Ramcontroller arbeitet ebenfalls mit
der Taktfrequenz von ComCLK. Da der Ramcontroller die Daten bei fallender
Taktflanke ubernimmt, das Rechenfeld jedoch bei steigender, herrscht zwischen
den Ramcontrollern und Rechenfeld eine Phasenverschiebung von 180 Grad bzw.
einem halben Takt. Der Ramcontroller wird deshalb mit dem invertierten Signal
von ComCLK, also ComCLK betrieben. Dann arbeiten alle internen Register des
Ramcontrollers ebenfalls mit steigender Flanke, allerdings mit steigender Flanke
von ComCLK.
Aus der obigen Darstellung ergibt sich, daß die FPGAs am Rand des Re-
chenfeldes nicht direkt miteinander kommunizieren konnen, sondern ihre Daten
immer durch den Ramcontroller schicken mussen, wie das in den Grunduberle-
gungen in Kapitel 3.4 (Bild 5) dargelegt wurde. Selbst wenn dieser die Daten
einfach nur weitergibt, ergibt sich eine großere Registeranzahl als zwischen zwei
FPGAs innerhalb des Rechenfeldes. Darauf wird in Kapitel 4.4 eingegangen.
ComCLK
RF out= RC in
Data valid
Data validRC out=RF in
ComCLK
Datenübernahme RC Datenübernahme RF
1. Takthälfte 2.Takthälfte 1. Takthälfte
Datenübernahme RF
resultierenderSignalverlauf
Data validRF RC
Data validRC RF
Data validRF RC
Data valid
Bild 10 Prinzipielles Timingdiagramm fur die Kommunikation
zwischen Rechenfeld (RF) und Ramcontroller (RC).
21

Kapitel 4 Die Komponenten von PAr2
Der IOB eines Pins eines auf Ausgang programmierten Rechenfeld-FPGAs
sieht fur die Busse innerhalb des Rechenfeldes (vgl. Bild 8) anders aus, als fur
die Rander, die zu den Ramcontrollern fuhren (Bild 9). Diese Unregelmaßigkeit
laßt sich aber durch das Einfuhren fester Signalbezeichnungen im FPGA (Kapitel
4.5) vor dem implementierten Algorithmus verbergen.
4.2 Ramcontroller
4.2.1 Aufgabe
Die Ramcontroller sind die Steuerzentralen der Rechenfeldes. Sie sind die
Ruckleitungen der Rechenfeld-FPGAs eingeschleift und konnen so die Daten im
Rechenfeld verfolgen und beeinflussen. Je nach gewunschter Aktivitat werden
dann Daten vom Host gelesen oder an den Host gesendet, oder Daten ins RAM
geschrieben oder vom RAM gelesen. All diese Aktionen werden durch die
Steuerdaten, die auf den Bussen des Rechenfeldes fließen und vom Interface
kommen, bestimmt.
Die Auswertung der Steuerinformation des Rechenfeldes ist dabei offen gelas-
sen. In dieser Arbeit werden nur die entspechenden Schnittstellen zum Rechenfeld,
Host und RAM zur Verfugung gestellt. Die Verbindung dieser Komponenten hangt
vom implementierten Algorithmus ab und muß mit dessen Programmierung auch
in den Ramcontroller-FPGAs definiert werden. Dies ist durchaus beabsichtigt;
denn eine Spezialisierung von der Hardwareseite auf ein bestimmtes Steuerungs-
schema schrankt die Klasse der bearbeitbaren Algorithmen ein.
Die Hauptaufgabe des Speichers am Rand wird in den meisten Fallen das
Zwischenspeichern der Daten fur eine bestimmte Anzahl von Taktzyklen sein,
der Speicher wird also als FIFO (First In – First out) genutzt werden. Allerdings
ist es durchaus denkbar, daß mehrere FIFOs unterschiedlicher Tiefe auf verschie-
denen Bits des Datenbusses realisiert werden mussen. Wollte man diese FIFOs
durch eine allgemeine Schaltung unabhangig vom implementierten Algorithmus
realisieren, hatte man sich auf eine bestimmte maximale Anzahl von FIFOs un-
terschiedlicher Tiefe festlegen und ihnen feste Bitnummern zuordnen mussen.
Dies wurde die Klasse der abarbeitbaren Algorithmen aber sehr einschranken.
Mit der jetzt zur Verfugung stehenden freien Gatterkapaziat von ca 4100 Gat-
tern pro Ramcontroller-FPGA kann man eine individuelle Darstellung des RAMs
fur jeden implementierten Algorithmus gut realisieren. Da diese Realisierung re-
lativ komplex ist, ist dabei an eine Bibliothek von Standardlosungen gedacht, aus
der fur den speziellen Fall eine Ansteuerung “maßgeschneidert” werden kann.
22

Kapitel 4 Die Komponenten von PAr2
4.2.2 Kommunikation zwischen Ramcontroller und Interface
Die Ramcontroller sind uber den Interface-Bus (IFBUS) mit dem Interface
verbunden. Dieser besteht aus zwei 24 Bit breiten Teilbussen fur Lesen und
Schreiben.
Mit derselben Uberlegung wie bei der Kommunikation zwischen Rechenfeld
und Ramcontroller (4.1.3) kann man die Leitungsanzahl am Ramcontroller in
Richtung Interface halbieren. Die zwei getrennten Busse fur Datenein- und
Datenausgabe werden an jedem Ramcontroller uber Bustreiber zusammengefaßt
(Bild 11).
ComCLK
U3
INV
U1
OUTFFT
XU1
1/6 74F245
IFBUS (READ)
BOE
C
D Q
U6
OUTFF
BIT A out
ComCLK
U5
BIT A
C
D Q
QM
U2
INREG
BIT A out
BIT A in
RCOE
C
DQ
U4
OUTFF
RCBOE
C
DQ
QM
INREG
XU2
1/6 74F245
IFBUS (WRITE)BIT A in
Interface Ramcontroller FPGARamcontrollerIFBUS
ComCLK
FPGA Write-Control
FPGA Read-Control
Bild 11 Kommunikation zwischen Ramcontroller und Interface
Betrachten wir zunachst den Datentransfer vom Ramcontroller zum Interface
uber den Write-Bus. Hat der Ramcontroller Daten zu senden, liegen sie an “Bit
A out” an. Gleichzeitig muß die Steuereinheit des Ramcontrollers an der Leitung
RCOE ein Low anlegen (fur die Signalverlaufe siehe auch Bild 12). Mit der
nachsten steigenden Flanke von ComCLK werden die Daten in die IOB-Register
ubernommen. Dadurch wird das Signal RCBOE low und der Bustreiber XU2
aktiv. Gleichzeitig hiermit wird der Bustreiber eines anderen Ramcontrollers, der
eventuell vorher den Bus belegt hat, inaktiv, da bei ihm RCOE high sein muß. Der
WRITE-Bus ist nun ausschließlich von diesem FPGA belegt. Solange ComCLK
high ist, ist der Ausgangstreiber im OUTFFT durchgeschaltet, und die Daten
gelangen uber die Tristatetreiber XU2 und den IFBUS(WRITE) zum Interface.
Wechselt ComCLK von High auf Low, ist das gleichbedeutend mit einem Wechsel
von ComCLK von Low auf High, was eine Ubernahme der angelegten Daten in
die IOBs des “FPGA Write-Control” des Interface zur Folge hat.
Nun erfolgt der Datentransfer in die andere Richtung (Ramcontroller-READ).
Mit dem Wechsel von ComCLK auf High wurden die im “FPGA Read-Control”
23

Kapitel 4 Die Komponenten von PAr2
an “Bit A out” anliegenden internen Daten in OUTFF ubernommen und gelangen
uber IFBUS(READ) an XU1. Gleichzeitig wird der Tristatetreiber im Ramcon-
troller FPGA inaktiv. Analog zur Schreibrichtung wurde man den Tristatetreiber
XU1 mit ComCLK steuern. Da das Aktivieren dieses Treibers aber wesentlich
schneller geschieht als das Abschalten des Treibers in den FPGAs, wurde aus Si-
cherheitsgrunden ein zusatzliches Signal BOE eingefuhrt, dessen fallende Flanke
gegenuber der von ComCLK verzogert ist. Solange dieses Signal Low ist, liegen
die Daten an U2 (INREG) des Ramcontrollers an. Hier werden sie mit steigender
Flanke von ComCLK ubernommen. Damit wird auch BOE wieder High und der
Treiber XU1 inaktiv und ein Schreib-/Lesezyklus ist abgeschlossen.
Wahrend der Ramcontroller-READ-Phase bleibt der Treiber XU2 aktiv, wo-
durch die Lesedaten auch uber den IFBUS(WRITE) an den INREGs des Interface
anliegen. Dies stort aber nicht, da die Daten nur mit steigender Taktflanke von
ComCLK ins Interface ubernommen werden. Die Daten liegen aber nur solange
an, bis ComCLK wieder Low wird.
4.2.3 Kommunikation zwischen Ramcontroller und RAM
Als RAM wurde statischer Speicher gewahlt, da er ohne komplizierte Refresh-
Schaltungen auskommt und die benotigten kurzen Zugriffszeiten von 12ns ermo-
glicht.
Der Speicher wird ebenfalls innerhalb eines Taktes von ComCLK sowohl
gelesen als auch geschrieben. Dazu verfugen die Datenleitungen zum RAM
uber denselben Multiplex-Mechanismus wie bei den Rechenfeld- bzw. Interface-
Anschluss. Die Adreßleitungen mussen aber ebenfalls gemultiplext werden, da-
mit das Schreiben an einer anderen Adresse wie das Lesen innerhalb des selben
Taktzyklus moglich ist. Diese Multiplexschaltung ist in Bild 13 gezeigt. Sie
stellt dem Ramcontroller intern getrennte Adreßleitungen fur Lesen (RADR0–14)
und Schreiben (WADR0–14) zur Verfugung, die synchron mit steigender Takt-
flanke von ComCLK ubernommen werden. Mit dieser Taktflanke werden auch
die Schreibdaten der angelegten Schreibadresse in die Datenbus-IOBs ubernom-
men. Ebenfalls gleichzeitig erscheinen die Lesedaten der Ramadresse des letzten
Taktzyklus am internen Eingang der FPGAs.
Im nachsten Takt werden zuerst bei ComCLK=H die Schreibadressen auf
den Adreßleitungen ausgegeben. Gleichzeitig sind die Datenleitungen des FPGAs
mit ComCLK=H auf Ausgang geschaltet. Das WE-Signal der RAMs wird nach
Einhalten der Adreßhaltezeit global auf Low gesetzt, wodurch die Daten in
das RAM geschrieben werden. Geht das WE-Signal wieder auf High, ist der
Schreibzugriff beendet. Dies erfolgt gleichzeitig mit dem Wechsel von ComCLK
auf Low. Damit werden zum einen an den Adreßleitungen die Leseadresse
ausgegeben, zum anderen die DatenbusIOBs des Ramcontrollers auf Eingang
24

Kapitel 4 Die Komponenten von PAr2
ComCLK
Data valid
Datenübernahme RCDatenübernahme IF
ComCLK
resultierenderSignalverlauf(RCPAD)
Data valid IF RC
Data validRC IF
Data valid IF RC
IFBUS(READ)
BOE
RCBOE
RC out(RCPAD)
IFBUS(WRITE)
RC in(RCPAD)
Data valid Data valid
Data valid
Datenübernahme IF
(falsche Daten)
Buskontrolle bei diesem Ramcontroller
Bild 12 Prinzipielles Timingdiagramm fur die Kommunikation
zwischen Ramcontroller(RC) und Interface(IF) uber den IFBUS.
geschaltet. Nach Abwarten der Adreßhaltezeit wird mittels des globalen OE-
Signals die Daten vom RAM auf den Datenbus gelegt. Mit steigender Taktflanke
von ComCLK werden diese Daten ins FPGA eingelesen und der Ablauf beginnt
von vorne.
Da die Schaltung vollig synchron mit globalen Taktsignalen arbeitet, wurden
Daten in jedem Taktzyklus sowohl vom RAM gelesen als auch ins RAM ge-
schrieben. Es ist aber durchaus denkbar, daß nicht in jedem Taktzyklus Daten fur
das RAM anfallen. Die vom RAM gelesen Daten storen dabei wenig, sie konnen
von dem implementieren Algorithmus einfach ignoriert werden. Das Schreiben
von Daten ins RAM muß jedoch in einem solchen Fall verhindert werden, da
nicht garantiert werden kann, daß uber mehrere Taktzyklen am internen Datenbus
25

Kap
itel4
Die
Ko
mp
on
enten
vo
nPA
r2
U12
OBUF
F27
SC
U36
OPAD
BLKNM=ADR0,FAST,LOC=N14
ADR0
wadrq016M2-1
..\16M2-1\16M2-1.SCH
A0
A1
A3
A4
A5
A6
A7
A8
A9
A10
A11
A12
A13
A14
A15
A2
B0
B1
B2
B3
B4
B5
B6
B7
B8
B9
B10
B11
B12
B13
B14
B15
SE
O0
O1
O2
O3
O4
O5
O6
O7
O8
O9
O10
O11
O12
O13
O14
O15
F1
SC
F2
SC
F3
SC
F4
SC
F5
SC
F6
SC
F7
SC
F8
SC
F9
SC
F10
SC
F11
SC
F12
SC
F13
SC
D0
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
D15
CE
Q0
Q1
Q2
Q3
Q4
Q5
Q6
Q7
Q8
Q9
Q10
Q11
Q12
Q13
Q14
Q15
CRD
U4
RD16wadr0
wadr0
wadr1
wadr2
wadr3
wadr4
wadr5
wadr6
wadr7
wadr8
wadr9
wadr10
wadr11
wadr12
wadr1
wadr2
wadr3
wadr4
wadr5
wadr6
wadr7
wadr8
wadr9
wadr10
wadr11
wadr12
U23
VCC radrq0
radrq1
wadrq1
wadrq2
wadrq3
wadrq4
wadrq5
wadrq6
wadrq7
wadrq8
wadrq9
wadrq10
wadrq11
wadrq12
U6
OBUF
U7
OBUF
U8
OBUF
F28
SC
F29
SC
F30
SC
U37
OPAD
BLKNM=ADR1,FAST,LOC=P15
U38
OPAD
BLKNM=ADR2,FAST,LOC=N15
U39
OPAD
BLKNM=ADR3,FAST,LOC=M14
ADR1
ADR2
ADR3
U13
OBUF
U14
OBUF
U16
OBUF
F31
SC
F32
SC
F33
SC
F34
SC
U40
OPAD
BLKNM=ADR4,FAST,LOC=P16
U41
OPAD
BLKNM=ADR5,FAST,LOC=L15
U42
OPAD
BLKNM=ADR6,FAST,LOC=M16
ADR4
ADR5
ADR6
radrq2
radrq3
radrq4
radrq5
radrq6
radrq7
radrq8
radrq9
radrq10
radrq11
radrq12U1
GND
D0
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
D15
CE
Q0
Q1
Q2
Q3
Q4
Q5
Q6
Q7
Q8
Q9
Q10
Q11
Q12
Q13
Q14
Q15
CRD
U5
RD16radr0
radr1
radr2
radr0
radr1
radr2
radr3
radr4
radr5
radr6
radr7
radr8
radr9
radr10
radr11
radr12
F14
SC
F15
SC
F16
SC
radr3
radr4
radr5
radr6
radr7
radr8
radr9
radr10
radr11
radr12
U24
VCC
F17
SC
F18
SC
F19
SC
F20
SC
F21
SC
F22
SC
F23
SC
F24
SC
F25
SC
F26
SC
U15
OBUF
U17
OBUF
U20
OBUF
F35
SC
F36
SC
F37
SC
U43
OPAD
BLKNM=ADR7,FAST,LOC=L16
U44
OPAD
BLKNM=ADR8,FAST,LOC=K14
U45
OPAD
BLKNM=ADR9,FAST,LOC=K15
ADR7
ADR8
ADR9
U9
OBUF
U10
OBUF
U18
OBUF
U19
OBUF
F38
SC
F39
SC
U46
OPAD
BLKNM=ADR10,FAST,LOC=K16
U47
OPAD
BLKNM=ADR11,FAST,LOC=J16
U48
OPAD
BLKNM=ADR12,FAST,LOC=J15
ADR10
ADR11
ADR12
VCC
U25
VCC
F48
SC
F49
SC
F50
SC
F51
SC
U2
GND
wadr13
wadr14
wen=L : active
w\e\n\wen
A0
A1
O0
O1
O2
O3
U27
D2-4
wadr13
wadr14
CE
D0
D1
D3
Q0
Q1
D2
R
Q2
Q3
C
U22
RD4R
4M2-1
..\4M2-1\4M2-1.SCH
A0
A1
A2
A3
B0
B1
B2
B3
SE
O0
O1
O2
O3
U32
INV
F44
SC
F45
SC
U11
OBUF
U28
OBUF
F40
SC
F41
SC
U49
OPAD
BLKNM=ADR13,FAST,LOC=H16
U50
OPAD
BLKNM=ADR14,FAST,LOC=G16
U51
OPAD
BLKNM=BANK0,FAST,LOC=G15
ADR13
ADR14
U29
OBUF
U30
OBUF
U31
OBUF
F42
SC
F43
SC
U52
OPAD
BLKNM=BANK1,FAST,LOC=G14
U53
OPAD
BLKNM=BANK2,FAST,LOC=F16
U54
OPAD
BLKNM=BANK3,FAST,LOC=E16
U33
INV
U34
INV
U35
INV
F46
SC
F47
SC
CE
D0
D1
D3
Q0
Q1
D2
R
Q2
Q3
C
U21
RD4R
F52
SC
F53
SC
F54
SC
F55
SC
ren
A0
A1
O0
O1
O2
O3
U26
D2-4
radr13
radr14
radr13
radr14
ren=L : active
r\e\n\
ComCLK
U3
INV
Bild
13
Adreß
multip
lexer
der
Ram
contro
ller
des
FP
GA
sg
ultig
eS
chreib
daten
ansteh
en.
Dieser
Sch
reibsch
utz
erfolg
tuber
das
CS
Sig
nal
des
RA
Ms,
das
nur
dan
nau
fL
ow
ist,w
enn
amW
EN
Ein
gan
gdes
Adreß
multip
lexers
eben
fallsein
Low
anlieg
t.L
iegt
dort
einH
igh
anw
erden
zwar
die
Sch
reibad
ressenau
sgeb
enund
Sch
reibdaten
anden
Daten
bus
geleg
t,au
chden
WE
-Sig
nal
kom
mt
aufg
rund
der
glo
balen
Gen
erierung
dieses
Sig
nals
amR
AM
an,
weil
CS
aber
Hig
hist,
werd
endie
Daten
nich
tubern
om
men
.A
us
Sym
metrie-
gru
nden
wurd
efu
rdie
Leserich
tung
das
analo
ge
Sig
nal
RE
Nein
gefu
hrt.
26

Kapitel 4 Die Komponenten von PAr2
ComCLK
Data valid
ComCLK
resultierenderSignalverlauf(Datenbus)
Data validRam RC
Data validRC Ram
RAMWE
RC out
Data valid Data valid
OE
Ram out
Adresse Read Adresse ReadAdresse WriteRamadresse
Datenübernahme RC Datenübernahme RamDatenübernahme Ram
Data validRam RC
Bild 14 Prinzipielles Timingdiagramm fur die Kommunikation zwischen Ramcontroller und RAM.
Mit Hilfe des CS Signals am RAM wird es auch moglich, mehrere RAM-
Bausteine parallel zu schalten und nur uber das CS Signal auszuwahlen, welches
RAM angesprochen wird. Auf diese Weise wurden 4 parallele BANKs vorge-
sehen, deren Auswahl uber die obersten Adreßbits erfolgt. Die Schaltung wie
sie jetzt vorliegt, ist fur 8kB RAMs konzipiert, es ergibt also ein maximaler
Adreßraum von 32k. Da aber das Pinout von 8kB und 32kB RAMs kompatibel
ist, wurden die zusatzlichen Leitungen bereits vorgesehen, und so konnen maxi-
mal 4x32k=128k Adreßraum angesprochen werden. Dafur ist die Schaltung des
Adreßmultiplexer aus Bild 13 an den vergroßerten Adreßraum anzupassen.
Die Schaltung des Adreßmultiplexer ist sehr zeitkritisch und erfordert deshalb
eine optimale Plazierung und Verdrahtung auf dem FPGA, damit keine zu großen
Laufzeiten auftreten. Deshalb ist vorgesehen, den Adreßmultiplexer aus einer
Datei zu der restlichen Schaltung des FPGAs dazuzuladen. In dieser Datei sind
dann bereits Plazierungsinformationen enthalten, welche die kurzen Laufzeiten
27

Kapitel 4 Die Komponenten von PAr2
garantieren. Dies wird durch eine Beschreibung des Adreßmultiplexers durch ein
sogenanntes Hardmacro erreicht (siehe [18]).
Der Adreßmultiplexer ist - wie der Umfang der Schaltung zu erkennen gibt
- im Gegensatz zu den Multiplexern der Datenleitungen nicht in den IOBs des
FPGAs unterzubringen. Er belegt 33 CLBs, also 17% des Ramcontroller-FPGAs.
Damit ist die Beschreibung der Kommunikation abgeschlossen. Im nachsten
Abschnitt soll nun das dafur notwendige Timing hergeleitet werden.
4.3 Takterzeugung
4.3.1 Grundkonzept
Da die Schaltung synchron arbeitet, muß ein globaler Takt zur Versorgung
aller FPGAs erzeugt werden. Neben diesem eigentlichen Taktsignal ComCLK
sind noch zwei zusatzliche globale Signale zur Steuerung der statischen RAMs
notwendig: das Output-Enable-Signal OE und das Write-Enable Signal WE.
Das Signal BOE zum Steuern der Tristatetreiber der Ramcontroller hat einen
identischen Verlauf wie das OE-Signal fur die RAMs. Dieses Signal wird fortan
mit BOE bezeichnet, das RAM WE Signal mit RAMWE.
Alle Signale werden von einem schnellen Grundtakt BaseClock (BSCLK) mit
64 Mhz abgeleitet. Dieser Grundtakt speist einen 3 Bit Zahler, an den eine 3 Bit
tiefes ROM angeschlossen ist. An den Datenausgangen des ROMs lassen sich so
je nach Programmierung beliebige Signale aus maximal 8 Segmenten und einer
Auflosung von 12.5 ns erzeugen. Bild 15 zeigt das Schaltung der Takterzeugung
wie sie in einem FPGA des Interface untergebracht ist.
Da dieser Zahler und das ROM in einem der FPGAs des Interface unterge-
bracht ist, ist es moglich, die durch das ROM erzeugten Taktsignale beliebig zu
andern. Deshalb wurden neben den erwahnten Taktsignalen noch vier weitere Lei-
tungen des Interface reserviert, um bei Bedarf zusatzliche Taktsignale erzeugen
zu konnen.
Wie erwahnt, ist die Moglichkeit vorgesehen, das Rechenfeld durch das
Interface anzuhalten. Dazu dient das Signal HALT, das mit steigender Flanke
von ComCLK in das Ausgangsflipflop von GTBUF geschrieben wird. An diesem
Signal ist der Output-Enable Pin der Takttreiber angeschlossen. Geht dieses Signal
auf high, werden die Ausgange der Treiber inaktiv. Durch Pullup- bzw. Pulldown-
Widerstande wird der Zustand der Signale hinter den Treibern “eingefroren”.
Somit bleibt das Rechenfeld stehen. Wird das HALT-Signal wieder auf Low gelegt
erfolgt das Aktivieren der Treiber synchron zu ComCLK, und das Rechenfeld
lauft weiter.
28

Kapitel 4 Die Komponenten von PAr2
U14
OPAD
U6
OBUFU7
OBUF
F6SC
F7SC
F2SC
F3SC
F4SC
A0A1A2
O0O1O2O3O4O5O6
U10
RFCLKGEN
F8SC
U8
OBUF
U15
OPAD
U16
OPAD
U17
OPAD
U5
OBUF
F5SC
F9SC
RD
Q0
Q1
Q2
Q3C
CE
U1C4BINRIP
U2VCC
F1SC
U4
IBUF
U22
IPADF10SC
U11
OBUFU12
OBUF
U18
OPAD
U19
OPAD
U20
OPAD
U13
OBUF
F11SCU3
GND
halt
C
D Q
U9
OUTFF
U21
OPAD
BLKNM=RAMWEout,FAST
FILE=RFCLKGEN
BLKNM=IFBOEout,FAST
BLKNM=ComCLKout,FAST
BLKNM=CLKa_out,FAST
BLKNM=BSCKL,FASTBLKNM=CLKb_out,FAST
BLKNM=CLKc_out,FAST
BLKNM=CLKd_out,FAST
BLKNM=GTBUF,FAST
Bild 15 Prinzip der Taktsignalerzeugung aus einem Grundtakt
Das Ableiten der Taktsignale aus einem gemeinsamen Grundtakt wurde der
Erzeugung von Taktsignalen mittels Verzogerungsglieder aus mehreren Grunden
vorgezogen. So ist es zum einen moglich, die Signale durch einfaches Umpro-
grammieren des Interface FPGAs dem oben beschriebenen Rahmen zu andern.
Außerdem kann so bei Laufzeitproblemen das gesamte Timing von PAr2 durch
Auswechseln des Quarzoszillators fur den Grundtakt geandert werden. Dies er-
wies sich insbesondere in der Testphase des Rechenfeldes als sehr nutzlich. Indem
man zuerst mit einem Quarz niedriger Frequenz die Schaltung testet, kann man
laufzeitbedingte Fehler ausschließen. Wenn eventuelle logische Fehler beseitigt
wurden, kann man durch Erhohen der Taktfrequenz die maximale Datenrate fest-
legen. Sollte das Rechenfeld spater vergroßert werden, wodurch sich langere
Laufzeiten der Signale auf dem globalen Interface-Bus ergeben, kann die Takt-
frequenz ebenfalls einfach angepaßt werden.
4.3.2 Bestimmung des optimalen Timing
Zur Bestimmung der optimalen Taktsignale wurden die einzuhaltenden Zeiten
zum Umschalten der diversen Treiber und des RAMs als lineares Programm
formuliert und dadurch das optimale Timing bestimmt. Dabei stellt sich das
Problem, daß die einzelnen Gatterlaufzeiten zwar sehr genau bekannt waren([15],
[11] und [5]), die Laufzeit der Signale auf den Leitungen jedoch nur schwer
abzuschatzen war. Dies lag einerseits an der anfangs nicht bekannten Geometrie
29

Kapitel 4 Die Komponenten von PAr2
des Rechenfeldes, zum anderen an den unbekannten dielektrischen Eigenschaften
des Platinenmatrials. So wurden die Laufzeiten als Variablen in das lineare
Programm eingesetzt, deren Werte erst durch empirische Messungen am fertigen
Aufbau bestimmt werden konnten. Die Lange des gemultiplexten Busses zwischen
Rechenfeld und Ramcontroller von etwa 40 cm ergab eine Laufzeit von ca 7ns.
Zwischen Interface und Ramcontroller sind die Signalleitungen mit ca 60 cm noch
langer und die Verzogerung somit noch großer (11 ns). Diese Verzogerungen
sollen nun systematisch untersucht werden und daraus ein lineares Programm
formuliert werden, um die maximale Taktfrequenz zu bestimmen.
τ
Tpick
ComCLK
Data validRC out
Tfza
Data validRF in
t0 t1
ComCLK
RF outData valid Data valid
Tfza
Tdrf
Tpick
RC inData valid Data valid
t2
Tdrf
Bild 16 Vollstandiges Timingdiagramm fur die Kommunikation zwischen Rechenfeld und Ramcontroller
Betrachten wir zunachst die Kommunikation zwischen Rechenfeld und Ram-
controller (Bild 16). Hierbei wird von einer Taktverschiebung Tdrf und einer
Datenlaufzeit derselben Große ausgegangen. Dies ist durchaus akzeptabel, da die
Leitungslangen der entsprechenden Signale in derselben Großenordnung liegen.
Fur die Kommunikation vom Ramcontroller zum Rechenfeld erhalten die Daten
dieselbe Verzogerung wie das Taktsignal. Es mussen also nur die Zeiten fur das
Einschalten der Ausgangstreiber des FPGAs (Tfza) und die Haltezeit am Ein-
gangsregister (Tpick) eingehalten werden. Dies liefert uns als erste Bedingung im
30

Kapitel 4 Die Komponenten von PAr2
linearen Programm:
Tfza + Tpick < t2 � t1
Bei der Kommunikation vom Rechenfeld zum Ramcontroller (2. Takthalfte
von ComCLK in Bild 16) ist der Takt ComCLK des Rechenfeldes bereits um
Tdrf gegen den Takt des Ramcontrollers verschoben. Nachdem das Rechenfeld
seine Daten durchgeschaltet hat (Tfza), dauert es wiederum Tdrf Sekunden, bis
die Daten am Ramcontroller-FPGA anliegen. Dort mussen sie mindesten Tpick
Sekunden anstehen, bevor ComCLK auf high wechselt. Dies liefert uns eine
weitere Bedingung fur das lineare Programm:
Tdrf + Tpick + Tdrf + Tfza < t1 � t0
Betrachten wir nun die Signale zwischen Interface und Ramcontroller (Bild
17). Da alle Signale vom Interface erzeugt werden, erhalten die Daten bei
der Kommunikation vom Interface zu den Ramcontroller dieselbe Verzogerung,
wie die Taktsignale selbst. Somit muß die Verzogerung der Signale in dieser
Richtung – analog zu dem oben betrachteten Fall – nicht berucksichtigt werden
(erste Takthalfte in Bild 17). Die relevanten Zeiten sind die Aktivierungszeit des
externen Treibers (Tbza) und die Datenhaltezeit (Tpick). Die Bedingung an das
lineare Programm ergibt sich so zu:
Tbza + Tpick < t1 � t3
wenn t3 der Zeitpunkt am Interface ist, zu dem das Signal BOE von High auf
Low wechselt. Es ist aber moglich, daß das BOE–Signal schneller schaltet, als
die Durchlaufzeit der Daten durch das Flipflop (Tokop) und den externen Treiber
XU1 (Tbd) ist. Dies wird mit folgender Ungleichung berucksichtigt:
Tokop + Tbd + Tpick < t1 � t0
Dazu kommt die Bedingung, daß der externe Treiber nicht zu fruh schalten darf,
damit nicht zwei Ausgange gegeneinander arbeiten:
Tfaz � Tshort < t3 � t0 + Tbza
wobei Tshort die Zeit ist, die zwei Ausgange maximal gegeneinander geschaltet
sein durfen.
Bei der Kommunikation in der anderen Richtung vom Ramcontroller zum In-
terface laufen die Daten den Taktsignalen sozusagen entgegen, was eine doppelte
Verzogerung der Daten mit sich bringt. Die Signale vom Interface besitzten eine
Verzogerung von Tdif . Das bedeutet, daß bei der Kommunikation vom Ram-
controller zum Interface der Ramcontroller erst mit einer Verzogerung von Tdif
31

Kapitel 4 Die Komponenten von PAr2
IFBUS(READ)(Interface)
Data validRC out(RCPAD)
Tokpo Tbza
RC in(RCPAD)
Data valid Data valid
Tbza
BOE
Buskontrolle bei diesem Ramcontroller
RCBOE
IFBUS(WRITE)(Ramcontroller)
Data valid (falsche Daten)
Tbd
ComCLK
τ
IFBUS(READ)(Ramcontroller)
ComCLK
Tdif Tpick
IFBUS(WRITE)(Interface)
Data valid (falsche Daten)
Tpick
Tdif
t0 t1 t2
Tfza
t3
Tokpo
Tfaz
Bild 17 Vollstandiges Timingdiagramm fur die Kommunikation zwischen Ramcontroller und Interface
gegenuber dem Interface die Daten absendet. Ebenfalls mit dieser Verzogerung
wird das Register des Steuersignals RCBOE getriggert. Bis dieses Signal tatsach-
lich am Pad erscheint, vergehen Tokpo Sekunden. Weitere Tbza Sekunden dauert
es, bis der Treiber XU2 von den hochohmigen Zustand in den aktiven Zustand
gewechselt ist. Nun ist das Signal bis zum Interface wieder Tdif lang unter-
wegs und muß dort wieder Tpick Sekunden anstehen, bevor ComCLK auf high
32

Kapitel 4 Die Komponenten von PAr2
wechselt. Somit ergibt sich als Bedingung:
Tdif + Tpick + Tdif + Tokop + Tbza < t2 � t1
Auch hier muß eine Bedingung bezuglich der Durchlaufzeit berucksichtigt wer-
den:
Tdif + Tfza + Tdif + Tpick < t2 � t1
ComCLK
Data valid
ComCLK
BOE
RAMWE
RC out
Data valid Data valid
Trdoe
Tfza
Ram out
Adresse Read Adresse ReadAdresse WriteRamadresse
Taa
Tdw Twr
Tsat4
t0 t1 t2
t5
Tpar Tpaw
Tfaz
Bild 18 Vollstandiges Timingdiagramm fur die Kommunikation zwischen Ramcontroller und Ram.
Als dritter Teil soll nun die Kommunikation zwischen RAM und Ramcontrol-
ler untersucht werden. Da hier die Leitungslangen relativ kurz sind, wurden keine
Signallaufzeiten berucksichtigt. Das zeitkritischste Element ist der Adreßmulti-
plexer, da hier auch interne Laufzeiten auf dem FPGA berucksichtigt werden
mussen. Die Verzogerungszeiten zwischen den Flanken von ComCLK und dem
Erscheinen der Daten am PAD wurden mittels des XILINX-Tool XDELAY be-
stimmt. Dabei ist Tpar die Zeit, die es dauert, bis nach positiver Flanke von
ComCLK die Leseadressen gultig sind. Tpaw ist die entsprechende Zeit fur die
Schreibdaten nach fallender Flanke von ComCLK.
Daraus lassen sich im wesentlichen schon die Bedingungen formulieren. Fur
den Lesezugriff auf das RAM muß die Adresse mindestens Taa Sekunden stabil
33

Kapitel 4 Die Komponenten von PAr2
sein, bevor die Daten gultig sind. Diese Daten mussen wiederum Tpick Sekunden
am Ramcontroller anstehen, bevor ComCLK auf High wechselt:
Tpar + Taa + Tpick < t1 � t0
Das Umschalten des Datenbusses nimmt Trdoe Sekunden nach der negativen
Flanke von BOE (t4) in Anspruch:
Trdoe + Tpick < t1 � t4
Auch soll eine maximale Kurzschlußzeit zweier Ausgange von Tshort garantiert
werden:
Tfaz � Tshort < t4 � t0 + Trdoe
Fur den Schreibzugriff erhalt man die analogen Bedingungen:
Tpaw + Tsa < t5 � t1
Tfza + Tdw < t5 � t1
Twr < t2 � t5
wobei t5 der Zeitpukt ist, wenn das Signale WE von High auf Low wechselt.
Fur konkrete Zahlenwerte sind naturlich die meisten der angegebenen Unglei-
chungen redundant, aber das lineare Programm sollte so allgemein wie moglich
formuliert werden.
Da alle Signale von dem gemeinsamen Takt BSCLK (� ) abgeleitet werden,
mussen die Schaltzeitpunkte an ganzzahligen Vielfachen von � liegen:
t1 � t0 = a � �t2 � t0 = b � �t3 � t0 = c � �t4 � t0 = d � �t5 � t0 = e � �a; b; c; d; e 2 N
34

Kapitel 4 Die Komponenten von PAr2
Insgesamt ergibt sich durch Zusammenfugen aller Bedingungen folgendes
Optimierungsproblem:
min �;
(b� a) � � � Tfza � Tpick
a � � � 2 � Tdrf(a� c) � � � Tbza + Tpick
a � � � Tokop + Tbd + Tpick
c � � � Tfaz � Tshort � Tbza
(b� a) � � � 2 � Tdif + Tpick + Tokop + Tbza
(b� a) � � � 2 � Tdif + Tfza + Tpick
a � � � Tpar + Taa + Tpick
(a� d) � � � Trdoe + Tpick
d � � � Tfaz � Tshort � Trdoe
(e� a) � � � Tpaw + Tsa
(e� a) � � � Tfza + Tdw
(b� e) � � � Twr
a; b; c; d; e 2 N
Ein Problem hierbei ist, daß nicht nur � , sondern auch die ganzzahligen Va-
riablen a; b; c; d; e zu bestimmen sind. Da sie als Faktoren vor der unabhangigen
Variablen � stehen, handelt es sich eigentlich nicht mehr um ein linerares Pro-
gramm, sondern um ein quadratisches Optimierungsproblem mit teilweise ganz-
zahligen Variablen. Ein solches Optimierungsproblem ist im allgemeinen schwer
zu losen. Deshalb werden alle sinnvollen Werte fur a bis e durch Enumerieren
eingesetzt. “Sinnvoll” heißt hierbei Werte zwischen eins und einer Obergrenze
(im Programm die Variable resolution). Fur b wird dabei immer die Ober-
grenze resolution eingesetzt, da b die Periode aller Taktsignale bestimmt
(b � � = t2 � t0). Fur jede Kombination der Variablen a; c; d; e muß dann ein
einfaches lineares Programm gelost werden. Das minimale � aller gefundenen
Losungen liefert die maximale Taktfrequenz der BSCLK und die Werte fur die
Faktoren a bis e.
Im Programm wurde resolution=8 gesetzt, da sich eine Zweierpotenz
leicht als Binarzahler realisieren laßt. Hohere Werte konnen zwar eventuell
ein besseres Ergebnis liefern, sind aber praktisch nicht mehr realisierbar. Denn
ein Faktor von beispielsweise zehn wurde bedeuten, daß die BSCLK zehn mal
schneller lauft als die resultierende ComCLK. Solch hohe Frequenzen fur das
BSCLK-Signal sind aber praktisch nicht mehr handhabbar.
35

Kapitel 4 Die Komponenten von PAr2
Das Enumerieren der moglichen Werte mag unelegant erscheinen. Da aber
das lineare Programm nur eine Variable zu bestimmen hat, handelt es sich faktisch
um eine Maximumbildung. Diese braucht sehr wenig Rechenzeit und so fallt die
Enumeration selbst bei 4096 Durchlaufen (resolution=8) kaum ins Gewicht.
Das entsprechende Programm zur Bestimmung der Zeiten ist im Anhang A
abgedruckt. Fur die dort eingesetzten Werte ergab sich eine maximale Frequenz
von ComCLK von 8.62 MHz. In der Realisierung wurde 8 MHz gewahlt,
entsprechend einem BSCLK-Quarz von 64 MHz. Der resultierende Verlauf der
Signale zeigt Bild 19.
ComCLK
BOE
BSCLK[64 MHz]
0 15.6
31.3
5
46.8
8
62.5
78.1
93.7
5
109.
4
125
Zeit [ns]
RAMWE
T = 8 MHz
Bild 19 Resultiernder Verlauf der globalen Taktsignale von PAr2
4.4 Modellierung der Kommunikation
Aus den in den vorangegangenen Abschnitten vorgestellten Kommunika-
tionsschaltungen laßt sich ein Modell fur die Kommunikationsvorgange auf
Registerebene ableiten.
Die Taktverschiebung zwischen Interface und Rechenfeld auf der einen Seite
und Ramcontroller auf der anderen soll dabei naher betrachtet werden. Interface
und Rechenfeld arbeiten wie erwahnt auf steigende Taktflanke von ComCLK, bil-
den also eine mit positiver Flanke getriggerte Logik, wahrend der Ramcontroller
auf steigende Taktflanke von ComCLK seine Daten taktet, also negativ getriggerte
Logik beinhaltet. An der Grenze folgt somit einem Register mit positiver Flanke
(Rechenfeld) ein Register mit negativer Flanke (Ramcontroller), wenn man den
36
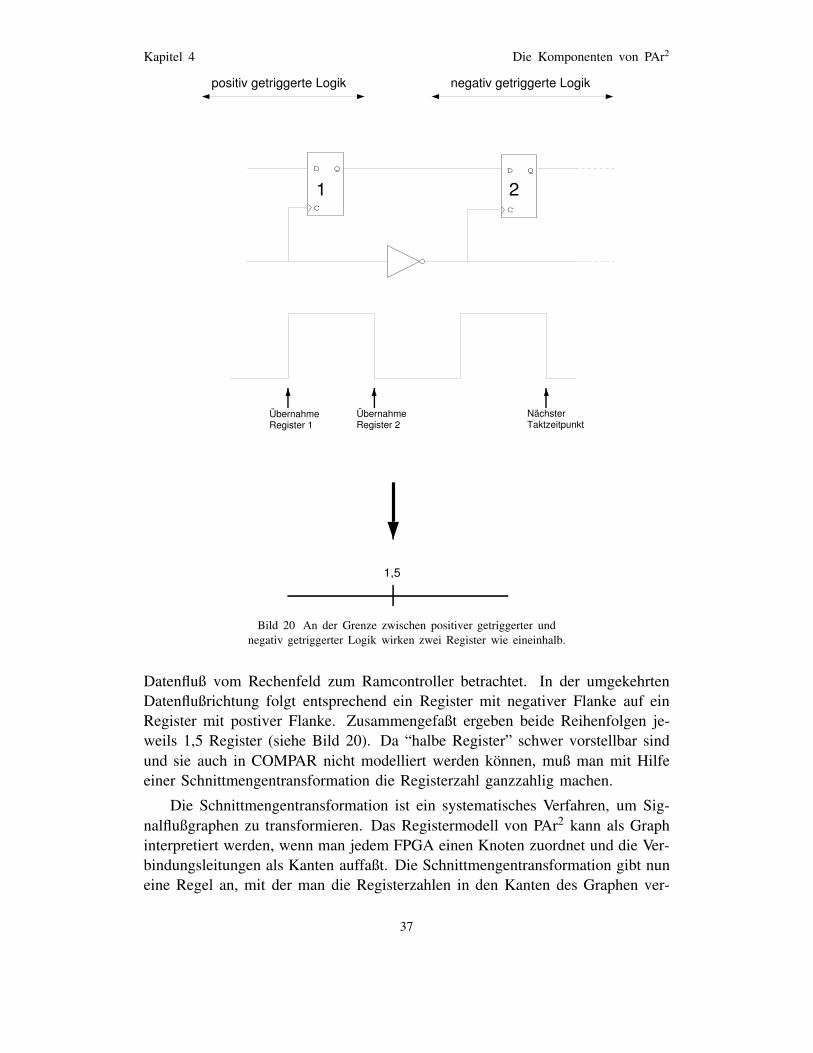
Kapitel 4 Die Komponenten von PAr2
C
D Q
C
D Q
1 2
NächsterTaktzeitpunkt
ÜbernahmeRegister 1
ÜbernahmeRegister 2
1,5
positiv getriggerte Logik negativ getriggerte Logik
Bild 20 An der Grenze zwischen positiver getriggerter und
negativ getriggerter Logik wirken zwei Register wie eineinhalb.
Datenfluß vom Rechenfeld zum Ramcontroller betrachtet. In der umgekehrten
Datenflußrichtung folgt entsprechend ein Register mit negativer Flanke auf ein
Register mit postiver Flanke. Zusammengefaßt ergeben beide Reihenfolgen je-
weils 1,5 Register (siehe Bild 20). Da “halbe Register” schwer vorstellbar sind
und sie auch in COMPAR nicht modelliert werden konnen, muß man mit Hilfe
einer Schnittmengentransformation die Registerzahl ganzzahlig machen.
Die Schnittmengentransformation ist ein systematisches Verfahren, um Sig-
nalflußgraphen zu transformieren. Das Registermodell von PAr2 kann als Graph
interpretiert werden, wenn man jedem FPGA einen Knoten zuordnet und die Ver-
bindungsleitungen als Kanten auffaßt. Die Schnittmengentransformation gibt nun
eine Regel an, mit der man die Registerzahlen in den Kanten des Graphen ver-
37

Kapitel 4 Die Komponenten von PAr2
andern kann, ohne die Funktionsweise der Schaltung zu andern [14]. Dazu wahlt
man sich eine Menge G von Knoten. Wenn man nun in alle Leitungen (Kanten),
die in diese Menge G hineinfuhren, c Register hinzufugt und bei den Leitungen
(Kanten), die hinausfuhren, c Register wegnimmt, hat sich an der Schaltungs-
funktion nichts geandert.
Diese Registerzahlen c mussen nicht notwendigerweise ganzzahlig sein.
Wahlt man als Menge G alle Ramcontroller mit Adreßmultiplexer und RAM und
setzt c = 12 , ergeben sich im Hinpfad zwei Register und im Ruckpfad eines (siehe
Bild 21). Naturlich konnte man auch c = �12 setzten und erhielte so im Hinpfad
eines und im Ruckpfad zwei Register. Dies macht fur die Funktionsweise keinen
Unterschied.
Die in Bild 21 eingezeichneten Hin- und Ruckleitungen mussen naturlich nicht
bei jedem implementierten Algorithmus vorkommen. Es ist auch ein Datenfluß
in nur eine Richtung bei einigen FPGAs denkbar. Das Bild soll jedoch alle
Spezialfalle abdecken.
Das Rechenfeld ist also nicht vollig homogen, die Rander mussen immer
uber den Ramcontroller kommunizieren, auch wenn sie eigentlich die Daten
nur an ein anderes FPGA des Rechenfeldes weitergeben wollen. Denn selbst
bei einer direkten Durchverbindung der Leitungen im Ramcontroller sind in
diesen Leitungen drei Register im Gegensatz zu zwei Registern innerhalb des
Rechenfeldes.
Das Beschreiben des RAMs erfolgt mit einer Verzogerung von einem Takt,
entsprechend befinden sich in Adreß- und Datenbus in Schreibrichtung jeweils
ein Register. Die Daten, die man beim RAM-Zugriff lesen kann, sind immer die
Daten der Adresse, die zum Zeitpunkt vorher angelegen hat. Entsprechend liegt in
der Adreßleitung ein Register, in der ruckfuhrenden Datenleitung jedoch keines.
Die Partitionierung in COMAR muß den Algorithmus so aufteilen, daß er
nicht mehr Ressourcen benotigt, als das Rechenfeld insgesamt zur Verfugung
stellen kann. Außerdem darf keinem einzelnen FPGA mehr Hardware zugeordnet
werden, als ein XILINX-Baustein fassen kann. Und drittens muß die Aufteilung
des Algorithmus so erfolgt sein, daß die Register, die durch die Kommunika-
tion entsprechend Bild 21 vorhanden sind, im Algorithmus im entsprechenden
Datenpfad auch vorgegeben sind.
Mit Hilfe des vorgestellten Registermodells wird es moglich, die Kommuni-
kation innerhalb von PAr2 zu modellieren und dem implementierten Algorithmus
fest definierte Schnittstellen zur Verfugung zu stellen. Dies kann abstrahiert von
der tatsachlichen physikalischen Realisierung der Kommunikation geschehen, der
implementierte Algorithmus muß davon nichts wissen.
38

Kapitel 4 Die Komponenten von PAr2
RF RF RF RC
RA
M
Adressm
ux
RF RF RF RC
RA
M
Adressm
ux
RF RF RF RC
RA
M
Adressm
ux
RAM
Adressmux
RC
RAM
AdressmuxR
C
RAM
Adressmux
RC
WA
WD
RA
RD
WA
WD
RA
RD
WA
WD
RA
RD
WA
WD
RA
RD
WA
WD
RA
RD
WA
WD
RA
RD
Interface
RF = Rechenfeld FPGARC = Ramcontroller FPGAWA= Write AdresseWD= Write DataRA = Read AdresseRD = Read Data
Bild 21 Registermodell von PAr2
4.5 Programmierung und Debugging
4.5.1 Vorbereiten der Programmierung
Der zu implementierende Algorithmus muß, wie im vorangegangenen Kapi-
tel dargelegt, erst von COMPAR so partitioniert werden, daß einzelne Segmente
entstehen, die nicht mehr Schaltunglogik beinhalten, als ein FPGA aufnehmen
kann. Ebenso muß die Schaltung fur die Ramcontroller spezifiziert werden. So
erhalt man 15 Beschreibungen fur die verschiedenen FPGAs. Die Beschreibung
der Chipinhalte erfolgt mit einem lesbaren Netzlistenformat, das von XILINX
39

Kapitel 4 Die Komponenten von PAr2
entwickelt wurde, dem sogenannten XNF-Format. Aus diesem Format wird mit
Hilfe des PPR-Programms (Partition, Place & Route) ein Zwischenformat erzeugt,
das mittels des Programms MAKEBITS in den Bitstrom zur Programmierung ei-
nes FPGAs umgewandelt wird. Das Programm PPR hat dabei relativ komplexe
Aufgaben zu losen, denn es muß die Netzliste, die es als Eingabe erhalt, so par-
titionieren, daß die CLBs optimal genutzt werden und die Verdrahtung zwischen
den CLBs durchfuhren. Dieser Vorgang kann fur ein gut ausgelastetes XC4005
FPGA durchaus mehr als eine Stunde Rechenzeit in Anspruch nehmen.
Die Beschreibung der Kommunikationsvorgange hat gezeigt, daß unterschied-
liche Inhalte in die Input/Output-Blocke der FPGAs des Rechenfeldes program-
miert werden mussen. Die Rander des Rechenfeldes benotigen in ihren Aus-
gangspins zusatzlich Tristatetreiber, die innerhalb des Rechenfeldes nicht benotigt
werden. Um diese Unregelmaßigkeit vor dem implementierten Algorithmus zu
verbergen, werden einheitliche Signalbezeichungen innerhalb des Chips im XNF-
Netzlistenformat eingefuhrt. Fur die neun unterschiedlichen Zuordnungen der
Rander zu den FPGAs des Rechenfeldes mussen an die Netzliste nur noch die
IOB-Belegungen angefugt werden, die fur die neun Chips in neun Dateien spe-
zifiziert sind. Die Festlegung der Namen ist in Tabelle 1 fur das Rechenfeld
aufgefuhrt. Es existieren pro Pin zwei Datenrichtungen (READ und WRITE),
es kann an den implementieren Algorithmus jedoch immer nur eines der beiden
Signale – abhangig von der Datenrichtung – angeschlossen werden. Die zweite,
nicht benotigte Richtung wird von dem Programm PPR unter Ausgabe einer War-
nung entfernt, weil entweder der Ausgang eines Flipflops (bei READ) oder der
Eingang eines Flipflops (bei WRITE) nicht angeschlossen ist.
Signalbezeichnungen des Rechenfeld-FPGA
Datenbus links Datenbus rechts Datenbus oben
(up)
Datenbus unten
(down)
Pinbelegung D3 - N2 C15 - N14 A1 - A14 R3 - R13
Signal in
FPGA hinein
(READ)
DLR0 - DLR23 DRR0 - DRR23 DUR0 - DUR23 DDR0 - DDR23
Signal aus
FPGA hinaus
(WRITE)
DLW0 - DLW23 DRW0 - DRW23 DUW0 -
DUW23
DDW0 -
DDW23
Tabelle 1 Signalbezeichnungen im Rechenfeld-FPGA
Ebenso kann man bei den Ramcontroller-FPGAs vorgehen. Diese sind zwar
alle identisch in der Pinbelegung, aber die Programmierung der IOBs sowie der
Adreßmultiplexer brauchen nicht fur jedes FPGA noch zusatzlich von COMPAR
erzeugt zu werden. Diese immer gleichen, der Hardware entsprechenden Beschrei-
40
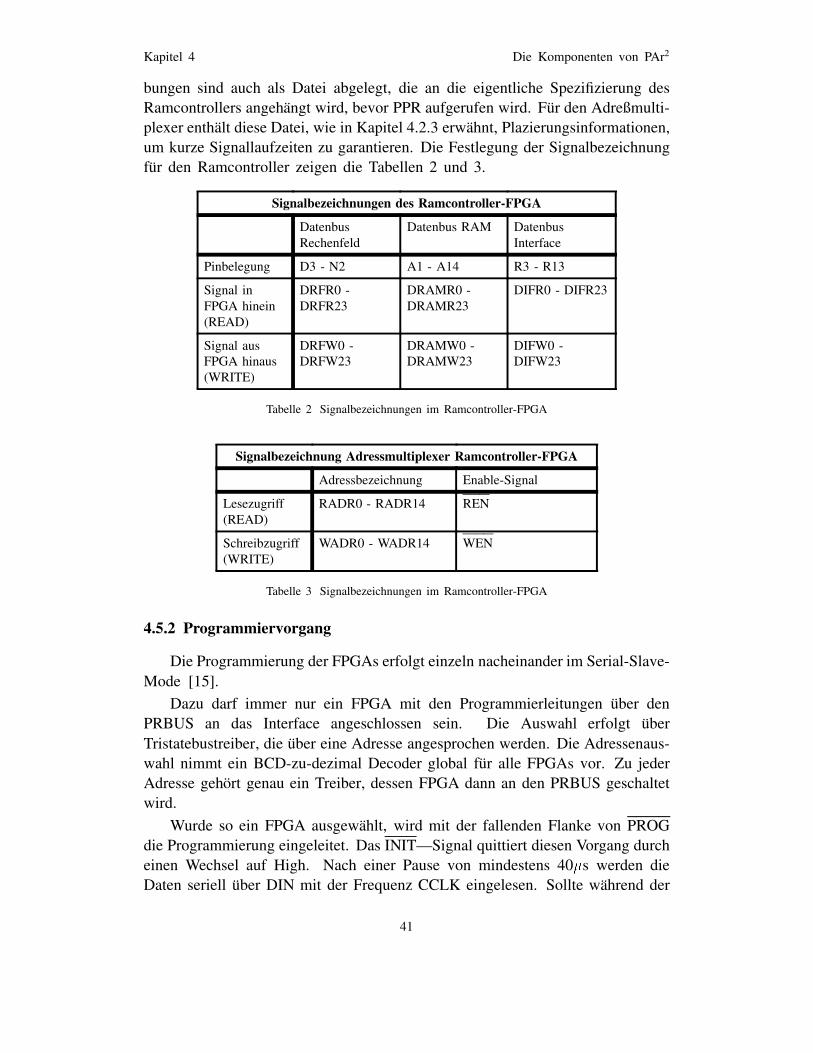
Kapitel 4 Die Komponenten von PAr2
bungen sind auch als Datei abgelegt, die an die eigentliche Spezifizierung des
Ramcontrollers angehangt wird, bevor PPR aufgerufen wird. Fur den Adreßmulti-
plexer enthalt diese Datei, wie in Kapitel 4.2.3 erwahnt, Plazierungsinformationen,
um kurze Signallaufzeiten zu garantieren. Die Festlegung der Signalbezeichnung
fur den Ramcontroller zeigen die Tabellen 2 und 3.
Signalbezeichnungen des Ramcontroller-FPGA
Datenbus
Rechenfeld
Datenbus RAM Datenbus
Interface
Pinbelegung D3 - N2 A1 - A14 R3 - R13
Signal in
FPGA hinein
(READ)
DRFR0 -
DRFR23
DRAMR0 -
DRAMR23
DIFR0 - DIFR23
Signal aus
FPGA hinaus
(WRITE)
DRFW0 -
DRFW23
DRAMW0 -
DRAMW23
DIFW0 -
DIFW23
Tabelle 2 Signalbezeichnungen im Ramcontroller-FPGA
Signalbezeichnung Adressmultiplexer Ramcontroller-FPGA
Adressbezeichnung Enable-Signal
Lesezugriff
(READ)
RADR0 - RADR14 REN
Schreibzugriff
(WRITE)
WADR0 - WADR14 WEN
Tabelle 3 Signalbezeichnungen im Ramcontroller-FPGA
4.5.2 Programmiervorgang
Die Programmierung der FPGAs erfolgt einzeln nacheinander im Serial-Slave-
Mode [15].
Dazu darf immer nur ein FPGA mit den Programmierleitungen uber den
PRBUS an das Interface angeschlossen sein. Die Auswahl erfolgt uber
Tristatebustreiber, die uber eine Adresse angesprochen werden. Die Adressenaus-
wahl nimmt ein BCD-zu-dezimal Decoder global fur alle FPGAs vor. Zu jeder
Adresse gehort genau ein Treiber, dessen FPGA dann an den PRBUS geschaltet
wird.
Wurde so ein FPGA ausgewahlt, wird mit der fallenden Flanke von PROG
die Programmierung eingeleitet. Das INIT—Signal quittiert diesen Vorgang durch
einen Wechsel auf High. Nach einer Pause von mindestens 40�s werden die
Daten seriell uber DIN mit der Frequenz CCLK eingelesen. Sollte wahrend der
41

Kapitel 4 Die Komponenten von PAr2
Programmierung ein Fehler auftreten, wird das INIT—Signal vom FPGA auf
Low gezogen.
Da sich bei einer Neuprogrammierung des Rechenfeldes die Richtungen der
Leitungen andern konnen, muß ein Mechanismus vorgesehen werden, der verhin-
dert, daß wahrend einer Programmierphase zwei Ausgange aufeinander treffen.
Dazu dient das Signal GTS (Global TriState), das an jedes FPGA gefuhrt wird.
Bevor die Programmierung gestartet wird, wird dieses Signal aktiviert, worauf alle
FPGA-Ausgange in den hochohmigen Zustand gehen. Jetzt konnen die FPGAs
der Reihe nach programmiert werden, ohne daß die Gefahr besteht, daß zwei Aus-
gange gegeneinander geschaltet werden. Außerdem muß garantiert werden, daß
das gesamte Rechenfeld gleichzeitig loslauft. Wahrend der Programmierung sorgt
das DONE–Signal dafur, das die Ausgange von bereits programmierten FPGAs
hochohmig bleiben, bis alle FPGAs programmiert wurden. Dazu ist das Signal
nicht wie die anderen Leitungen uber die Tristatetreiber geschaltet, sondern alle
DONE-Leitungen aller FPGAs sind direkt parallel verbunden. Dies ist moglich,
da es sich um Open-Kollektor-Ausgange handelt. Der Ausgangspegel dient dem
FPGA nach der Programmierung gleichzeitig als Information, ob die Ausgange
aktiviert werden durfen. Dazu “halt” man das DONE-Signal von außen, also
durch das Interface auf Low.
Ein Programmiervorgang soll deshalb folgendermaßen ablaufen:
• Anhalten des globalen Taktes ComCLK.
• Alle Pins aller FPGAs durch Umschalten von GTS auf High hochohmig
machen.
• DONE-Signal auf Low ziehen.
• Selektieren und Programmieren der einzelnen FPGAs.
• DONE-Signal “loslassen”; geht es auf High, ist kein Fehler wahrend der
Programmierung aufgetreten.
• GTS=Low.
• ComCLK starten.
4.5.3 Readback
Der READBACK-Mechanismus der XILINX FPGAs ermoglicht ein Auslesen
der internen Registerzustande. Die so erhaltenen Informationen konnen Debug-
gingzwecken dienen.
Um die Informationen aus einem bestimmten FPGA auszulesen, wird der-
selbe Adressierungsmechanismus verwendet wie bei der Programmierung. Die
Tristatetreiber schalten also nicht nur die Leitungen fur die Programmierung an
das Interface, sondern auch die Leitungen RTRIG, RIP, RCLK und RDATA fur
das READBACK.
42

Kapitel 4 Die Komponenten von PAr2
Fur weitere Einzelheiten zum Programmier- bzw. Readbackvorgang sei auf
[15] und [7] verwiesen.
43

Kapitel 5 Realisierung der Hardware
5 Realisierung der Hardware
Am Anfang der Uberlegungen stand unter anderem, das Konzept des Re-
chenfeldes moglichst modular zu halten, um es bei Bedarf vergroßern zu konnen.
Deshalb wurde fur die Realisierung zuerst versucht, eine Platine fur jedes FPGA
des Rechenfeldes vorzusehen, die uber Stecker einen beliebigen Ausbau des Re-
chenfeldes ermoglichen.
Der Aufwand an Steckverbindungen ware aber auf dem Rechenfeld enorm
gewesen. Denn bei einem zweidimensionalen Rechenfeld sind die vier moglichen
Richtungen in der Ebene bereits durch die Anschlusse der Nachbarprozessoren
belegt. Da aber auch globale Leitungen fur den Takt und die Programmierung der
FPGAs benotigt werden, hatte man diese von unten oder oben fur jedes FPGA
extra zufuhren mussen und so Probleme bei der Verteilung dieser Signale auf
dem Rechenfeld bekommen.
Deshalb wurde in der Realisierung ein Kompromiß eingegangen: Die Ram-
controller, die bereits eine relativ hohe Komplexitat aufweisen, wurden jeweils auf
einer Platine aufgebaut, auf die das RAM mit einer zusatzlichen Platine (Ram-
card) eingesteckt wird. Das gesamte Rechenfeld mit den neun FPGAs wurde aber
auf einer großen Platine untergebracht. Diese Platine ist nicht erweiterbar, d.h.
sollte man ein großeres Rechenfeld wunschen, mußte dafur eine komplett neue
Rechenfeld-Platine gebaut werden. Allerdings kann man durch die vorhandenen
Kurzschlußverbindungen das Rechenfeld beliebig verkleinern. Die Ramcontroller
konnen in einer vergroßerten Version des Rechenfeldes aber weiterhin genutzt
werden.
Alle Platinen wurden zweiseitig durchkontaktiert gefertigt. Fur die Anpassung
an die Schnittstelle des Interfaces ist eine zusatzliche Platine (Interface-Adapter)
notig. Diese wurde in Fadel-Technik realisiert.
5.1 Uberblick
Der Aufbau gliedert sich in drei große Teile: das eigentliche Rechenfeld mit
neun FPGAs, die sechs Ramcontroller am Rand zur Steuerung von Speicherzu-
griffen und der Kommunikation mit dem Interface, sowie dem Interface-Adapter,
der die physikalische Schnittstelle zum Interface bildet.
Die Datenbusbreite betragt 24 Bit, dementsprechend sind die RAMs auch
zu 3x8 Bit breiten Daten angeordnet. In der momentanen Ausstattung sind pro
Ramcontroller 24 x 8k Ram, also insgesamt 144 kB Speicher auf dem gesamten
Rechenfeld aufgebaut. Es ist aber ein Ausbau mit bis zu 24 x 128k RAM je
Ramcontroller moglich, was einem Gesamtspeicher von 2304 kB entspricht.
44

Kapitel 5 Realisierung der Hardware
Der Rechentakt betragt 8 MHz. Wegen des getrennten Busses fur READ und
WRITE zwischen Interface und Ramcontroller konnen somit maximal 3 * 2 * 8
= 48MByte Daten pro Sekunden zum Transport fur das Interface anfallen.
Bild 22 zeigt das Blockschaltbild von PAr2. Das Rechenfeld mit den neun
FPGAs befindet sich auf einer großen Rechenfeldplatine. Jeder Ramcontroller
befindet sich mit RAM auf einer eigenen Platine, die uber eine VG64-Leiste an
das Rechenfeld angeschlossen wird. Der horizontale, 60 Leitungen umfassenden
IFBUS verbindet alle Ramcontroller am oberen Rand des Rechenfeldes mit der
Interface-Adapter Platine. Durch den entsprechenden vertikalen Bus sind die
Ramcontroller am rechten Rand der Rechenfeldplatine mit dem Interface-Adapter
verbunden. Eine 40polige Verbindung zwischen Interface-Adapter und Rechenfeld
dient hauptsachlich der Programmierung der FPGAs, sowie der Verteilung der
globalen Signale PRBUS, GPBUS und ComCLK. Auf dem Interface-Adapter ist
des weiteren die Grundtakterzeugung, sowie die Takttreiber und Taktverteilung
untergebracht. Zusatzlich sind in Bild 22 die Adressen der FPGAs fur die
Programmierung und das Readback eingezeichnet.
Rechenfeld
Ramcontroller
Ram
controller
Interface-Adapter
Interface
IFBUS vertikal
IFBUShorizontal
PRBUSGPBUSComCLKFADR
1
2
3
456
7
8
9
10
11
12
13
14
15
Bild 22 Blockschaltbild mit Verteilung der globalen Signale sowie der Adressen der FPGAs
45

Kapitel 5 Realisierung der Hardware
5.2 Rechenfeld
Das Rechenfeld aus den 3 x 3 FPGAs befindet sich auf einer großen Pla-
tine von ca 40 x 42 cm. Sie ist sehr regelmaßig aufgebaut. Zu jedem FPGA
existiert ein Tristate-Treiber, der die Programmierleitungen und Readbackleitung
des entsprechenden FPGAs auf den Program&Readback-Bus schaltet. Die An-
steuerung dieser Treiber erfolgt uber einen BCD-zu-dezimal-Dekoder 74154, der
16 Adressen auswahlen kann. So werden durch diesen Decoder nicht nur die
Rechenfeld-FPGAs adressiert, sondern sechs Leitungen werden an die Ramcon-
troller weitergeleitet. Die freibleibende Adresse 0 soll immer dann adressiert sein,
wenn keines der FPGAs programmiert werden soll.
Die Verteilung der globalen Signale (ComCLK, PRBUS, GPBUS) erfolgt nach
dem in Bild 22 angegebenen Schema. Die Ramcontroller werden also von dem
Rechenfeld her mit den globalen Signalen versorgt (siehe auch Steckerbelegung
im Anhang).
FPGA1,1
FPGA3,1
FPGA
FPGA1,2
FPGA3,2
FPGA2,2
FPGA1,3
FPGA3,3
FPGA2,3 2,1
U
D
L R
U
D
L R
U
D
L R
U
D
L R
U
D
L R
U
D
L R
U
D
L R
U
D
L R
U
D
L R
Bild 23 Phyikalische Verdrahtung der lokalen Verbindungen der FPGAs auf dem Rechendfeld.
Jedes FPGA ist mit seinen vier Nachbarn uber einen 24 Bit breiten Bus ver-
bunden. Die FPGAs am Rand sind uber lange Ruckleitungen an den entsprechen-
46

Kapitel 5 Realisierung der Hardware
den Partner auf der anderen Seite der Platine angeschlossen. Ausserdem werden
diese Leitungen auf die Ramcontrolleranschlusse gefuhrt (Bild 23). Die langen
Ruckleitung bewirken Signallaufzeiten. Erschwerend kommt hinzu, daß gerade
diese Ruckleitungen auch zum Ramcontroller fuhren und somit gemultiplext sind,
d.h. eine hohere Datenrate fassen mussen. Es gibt ein Verbindungsschema, das
den Nachteil der langen Ruckleitungen nicht aufweist: uberspringt man bei der
Verdrahtung immer ein FPGA, so ergibt sich zwischen allen FPGAs ungefahr
dieselbe Leitungslange (Bild 24). Somit konnten beliebig große Rechenfelder
realisiert werden, ohne daß es zu Laufzeitproblemen auf dem Rechenfeld kame.
Aus mehreren Grunden wurde diese Schema aber trotzdem nicht verwen-
det. Zum einen ist die Verdrahtung auf der Platine wesentlich schwieriger, weil
die Leitungen oft schrag gefuhrt werden mussen, was bei einem Bus von 24
Leitungen einen erheblichen Platzbedarf bedeutet. Des weiteren ist der Gewinn
dieses Verdrahtungsschemas bei einem 3x3–Rechenfeld relativ bescheiden, denn
die Ruckleitungen nach dem einfachen Verdrahtungsschema sind nur unwesentlich
langer, als bei der Verdrahtung nach Bild 24. Und drittens fuhrt die Umplazie-
rungen der einzelnen FPGA zu erheblichen Komplikationen bei der Zuordung der
Busse am FPGA.
Wenn man davon ausgeht, daß der implementierte Algorithmus regelmaßig
aufgebaut ist, wird jedes FPGA auf der Rechenfeldplatine annahernd denselben
Inhalt bekommen. Verdrahtet man die FPGAs nach dem in Bild 24 gezeigten
Schema, andern sich nicht nur ihre Positionen auf dem Rechenfeld, sondern es
drehen sich teilweise die Zuordungen von ”links” und “rechts” bzw. “oben” und
“unten” um. Betrachten wir dazu FPGA (1,2). Verglichen mit Bild 23 zeigt
sich, daß die Anschlusse links und rechts vertauscht sind. Das bedeutet, daß man
entweder den Inhalt des Chips entsprechend “umdrehen”, oder den Chip auf der
Platine anders anschließen muß.
Dreht man den Chipinhalt um, handelt man sich interne Unregelmaßigkeiten
ein, weil die FPGAs nicht vollig homogen aufgebaut sind. Die Anschlusse auf
der Platine zu andern ist aber auch relativ unrealistisch, denn um die Anordnung
entsprechend Bild 24 zu erreichen, mußten die Chip teilweise spiegelverkehrt,
d.h. von der Unterseite der Platine eingelotet werden. Außerdem verliert man
so die Regelmaßigkeit im Layout. Deshalb wurde das einfachere Layout nach
Bild 23 gewahlt.
An jeden der vier Busse eines FPGA ist ein 26pol Pfostenstecker angeschlos-
sen (JM10 – JM42). Er kann einerseits zu Meßzwecken dienen, andererseits
ermoglicht er es, das Rechenfeld zu verkleinern. Dazu uberbruckt man die nicht
benotigten Rechenfeld-FPGA—Sockel (die FPGAs sollten in diesem Fall aus den
Sockeln ausgebaut werden !) an ihren Pfostensteckern mit Flachbandkabeln. So
ist es einfach moglich, auch ein beliebig kleineres Rechenfeld zu erhalten.
47

Kapitel 5 Realisierung der Hardware
FPGA FPGA FPGA
FPGA FPGA FPGA
FPGA FPGA FPGA
1,11,31,2
3,2 3,3 3,1
2,2 2,3 2,1
U
D
U
D
U
D
U
D
U
D
U
D
D
U
D
U
D
U
L R
L R
L R
L R
L R
L R
R L
R L
R L
Bild 24 Mogliches Verdrahtungsschema der FPGAs des Rechenfeldes mit konstanten Leitungslangen.
5.3 Ramcontroller
Der Ramcontroller ist die komplexeste Platine des Projekts. Sie enthalt ne-
ben dem eigentlichen Ramcontroller-FPGA mit Program&Readback Buffer den
Demultiplexer zum Anschluß an den IFBUS, zwei Steckplatze zur Aufnahme der
Ramkarten, sowie den Anschluß an das Rechenfeld. Der Rechenfeld-Anschluß
ist als VG64–Leiste ausgefuhrt und liefert den lokalen Datenbus vom Rechen-
feld sowie den PRBUS, den GPBUS und das ComCLK-Signal. Ein 60poliges
Flachbandkabel fuhrt den IFBUS und die Signale BOE und RAMWE direkt vom
Interface zum Ramcontroller.
Die Steckerbelegungen sind im Anhang aufgefuhrt. Ebenfalls im Anhang ist
der Schaltplan abgedruckt.
Der Ramausbau sollte moglichst flexibel moglich sein. Dies wurde im Kapitel
4.2.3 bereits mit der Einfuhrung des Bankings ermoglicht. Um in der Realisierung
die durch das Banking gewonnene Flexibilitat nicht zu verlieren, wurden die
Rambausteine nicht direkt auf der Ramcontroller-Platine untergebracht, sondern
werden uber zwei 50poligen Steckplatze angeschlossen. Diese konnen jeweils
eine Platine aufnehmen, die die RAMs tragt (Ramcard). Da diese Ramcard nur
48

Kapitel 5 Realisierung der Hardware
die gewunschten Speicherbausteine ohne Zusatzbauteile tragen muß, ist sie einfach
zu entwerfen und einfach an die gewunschten Verhaltnisse anpaßbar.
Die realisierte ”Ramcard I” stellt die einfachste Moglichkeit dar, die RAMs
anzuschließen. Sie ist in der Lage, entweder drei 8Kx8 RAMs oder drei 32Kx8
RAMs aufzunehmen, also genau eine Bank. Jumper ermoglichen die Auswahl
einer der vier Banks, an die die RAMs gelegt werden sollen. Mit einer zweiten
Karte diesen Typs laßt sich der Speicher verdoppeln, indem man dort einfach die
nachste Bank durch Jumpern auswahlt. Erst wenn mehr als zwei Banks genutzt
werden sollen, muß eine neue Platine entworfen werden, die mindesten zwei
Banks auf einmal ansprechen kann.
Alle Daten- und Adreßleitungen sind mit Abschlußwiderstanden versehen,
um die Reflektionen am Leitungsende so gering wie moglich zu halten. Diese
Abschlußwiderstande sind mit den Widerstandsnetzwerden RN1 - RN10, sowie
den Widerstanden R4 - R8 realisiert (siehe auch Kapitel 5.5).
Die fur das Demultimplexen des IFBUS benotigten Tristatetreiber sind eben-
falls auf der Platine untergebracht (IC 2– IC 7). IC 2 bis IC 4 puffern den
Zugriff auf den IFBUS(WRITE), also die Datenausgabe vom Ramcontroller zum
Interface. Ihre Freigabe erfolgt durch das RCBOE-Signal wie in Kapitel 4.2.2
erlautert. Die Treiber IC 5 bis IC7 sind fur die Gegenrichtung zustandig und
werden von dem globalen Signal BOE gesteuert. Der Widerstand R11 sorgt im
nichtprogrammierten Zustand des FPGAs dafur, das die Treiber inaktiv sind.
Fur Meß– und Kontrollzwecke sind die Stecker JM1 bis JM3 vorgesehen. An
JM1 liegt der Datenbus Richtung Rechenfeld, wahrend JM2 die Daten vor den
Demultiplexern zum Interface fuhrt. JM3 schließlich stellt die Anschlusse des
PRBUS hinter dem Tristatetreiber direkt am FPGA zur Verfugung. Die Belegung
dieser Meßpunktstecker ist am Anhang aufgefuhrt (JM1 und JM2 sind vom Typ
B, JM3 vom Typ A).
5.4 Interface Adapter
Beim Interface-Adapter laufen alle Faden der Kommunikation zusammen.
Der Anschluß an das Interface erfolgt uber zwei VG64 Leisten, wovon eine
zum FPGA fur die Leserichtung, die andere zum FPGA fur die Schreibrichtung
fuhrt. Die Belegungen dieser Stecker ist zusammen mit den Schaltplanen wie
ublich im Anhang aufgefuhrt.
5.4.1 Signalverteilung
Die Ramcontroller werden uber den horizontalen (mittels CN4) und den verti-
kalen (mittels CN5) IFBUS angeschlossen. Diese Busse sind als Flachbandverbin-
49

Kapitel 5 Realisierung der Hardware
dungen ausgefuhrt und am Ende mit Terminierungswiderstanden abgeschlossen,
um die Reflektionen am Leitungsende so gering wie moglich zu halten.
Die Verbindung CN3 zum Rechenfeld umfaßt den GPBUS und PRBUS mit
den Adreßleitungen zum Selektieren der FPGAs (FADR0–7), sowie den globalen
Takt ComCLK.
5.4.2 Taktverteilung
Neben der Verteilung der Signale auf die Rechenfeld– und Ramcontrollerpla-
tinen, wird auf der Interface–Adapter–Platine der globale Takt BSCLK erzeugt,
und uber Treiber werden die einzelnen Taktsignale verstarkt.
Die Grundtakterzeugung geschieht mittels eines TTL-Quarzoszillators, dessen
Ausgang direkt uber den Interface-Anschluß #2 (CN2) zum FPGA #2 des Interface
fuhrt. Dort ist, wie in Kapitel 4.3 beschrieben, die programmierbare Takterzeu-
gung untergebracht. Als Signale kommen von dort die Leitungen RAMWE_out,
ComCLK_out, BOE_out, CLKa_out bis CLKd_out, sowie GTBUF zuruck. Alle
Signale werden durch Tristate-Treiber 74F245 verstarkt. Dies bewirkt eine einheit-
liche Verzogerung aller Taktsignale ohne Phasenverschiebung. Deshalb werden
die fur den Betrieb des Interface benotigten Taktsignale von hier auch wieder
an das Interface zuruckgegeben und nicht direkt innerhalb der Interface-FPGAs
geroutet.
Das Signal GTBUF dient dazu, den Treiber U2 zu deaktivieren, wodurch
wegen der nachgeschalteten Pullup-Widerstande alle Ausgange auf high gehen.
Damit ist es moglich, das Rechenfeld anzuhalten (Schaltbild Anhang F, Bild 41).
An U2 werden die Signale BOE_out und RAMWE_out geteilt und jeweils uber
einen eigenen Treiber verstarkt. Die Signale fuhren dann zum horizontalen bzw.
vertikalen IFBUS. Somit muß nicht ein Treiber alle RAMs ansteuern, sondern zwei
konnen sich die Arbeit teilen, was einen weniger stark verzerrten Signalverlauf
zur Folge hat.
Die Signale, die uber U3 gefuhrt werden, konnen nicht abgeschaltet werden.
Dies muß so sein, da hiervon auch der Takt des Interface selbst herkommt, der
naturlich nicht mit angehalten werden darf, wenn das Rechenfeld stehen bleibt.
5.4.3 General Purpose Bus
Fur den GPBUS wurde ein Jumper-Feld auf der Interface-Adapter-Platine
vorgesehen, um diese Leitungen moglichst flexibel nutzen zu konnen.
So sollen zum einen zusatzliche Clocksignale verteilt werden konnen. Eine
denkbare Anwendung eines weiteren Clocksignals konnte beispielsweise in der
Verwendung als Takt fur die neun FPGAs des Rechenfeldes liegen. Diese FPGAs
konnten dann mit einer hoheren Frequenz arbeiten. Auch einen Datenaustausch
50

Kapitel 5 Realisierung der Hardware
zwischen diesen FPGAs ware noch moglich, da sich die Kommunikation der
Rechenfeld-FPGAs untereinander relativ einfach gestaltet (vgl. 4.1.2). Nur die
Kommunikation mit den Ramcontrollern mußte mit der langsameren Frequenz
ComCLK erfolgen.
Zum andern sollen globale Signale vom Interface an die FPGAs weitergeleitet
werden konnen oder umgekehrt globale Signale von den FPGAs zum Interface
gelangen. Da das Interface getrennte FPGAs fur Lese- und Schreibrichtung hat,
sollte der IFBUS teilweise an das eine oder andere Interface-FPAG angeschlossen
werden konnen.
Diese Aufgaben werden mit einem Jumper-Feld (vgl. Bild 42) realisiert. Die
Bits 0–3 des GPBUS konnen mittels der Jumper JP22–JP25 an die zusatzlichen
Clocksignale CLKa-CLKd angeschlossen werden. Sollte dies nicht erwunscht
sein, konnen diese Bits uber die Jumper JP18–JP21 zur Aufteilung an den GPin–
bzw. GPout-Bus weitergeleitet werden. Das Interface stellt zwei Richtungen
fur die moglichen globalen Leitungen des GPBUS zur Verfugung : acht Leitun-
gen fuhren zum Rechenfeld hin (GPin0–7), acht weitere vom Rechenfeld weg
(GPout0–7). Die Zuordnung des GPBUS zu dem GPin- bzw. GPout-Bus erfolgt
uber die Jumper JP2–JP17.
5.5 Layout
5.5.1 Stromversorgung
Da das gesamte System von PAr2 synchron arbeitet, wurde bei der Verteilung
der Stromversorgung mit Sorgfalt gearbeitet. Das gleichzeitige Schalten aller
Bauteile kann namlich erhebliche Stromspitzen mit sich bringen.
So wurde die Stromversorgung fur jeden Ramcontroller extra gefuhrt, fur
das Rechenfeld wurden drei Stromversorungsanschlusse vorgesehen. Die Versor-
gungsleitungen treffen sich erst direkt am Netzteil. Es gilt namlich, die gemein-
samen Leitungswege zweier Stromkreise so kurz wie moglich zu halten, um die
galvanische Kopplung zu minimieren. Optimal ware hierfur eine streng sternfor-
mige Spannungsverteilung, bei der alle Verbraucher direkt an einem gemeinsamen
Punkt angeschlossen sind. Dies laßt sich bei einem so umfangreichen Projekt wie
dem Rechenfeld aber nicht realisieren. So wurden die VCC-Versorungsleitungen
sternformig zu den einzelnen Platinen gefuhrt und dort moglichst gunstig ver-
teilt. Insbesondere wurde darauf geachtet, daß sich keine Schleifen in der VCC-
Versorung ausbilden.
Zusatzlich wurde vor jedem Anschluß eines Zweiges an das Netzteil ein
Tiefpaß in Form eines �-Gliedes zwischengeschaltet (Bild 25). Diese Tiefpasse
sollen hochfrequente Storsignale, die durch das Schalten der Treiber entstehen,
51

Kapitel 5 Realisierung der Hardware
auf den lokalen Versorgungszweig beschranken, in dem sie entstehen. Die Spule
L besteht dabei nur aus funf Windungen Kupferdraht. Da neben den sechs
Ramcontrollern und den drei Anschlussen des Rechenfeldes auch der Interface-
Adapter mit Spannung versorgt werden muß, wurde dieser Tiefpaß insgesamt
zehnmal benotigt.
C1 100nF C2 100nF
L
C3 100uF
Net
ztei
l
VCC
GND
Bild 25 �-Tiefpaßfilter in den Versorgungsleitungen
Die Stromversorgung des Oszillators, der das BSCLK-Signal erzeugt, wurde
noch einmal zusatzlich gefiltert. Dies erwies sich als notwendig, da sich die sehr
hohen Frequenzen des Grundtaktes sonst zu stark auf die Versorgungsspannung
ubertragen hatten. Dieser Filter ist in Bild 26 zu sehen.
C2 100nF C3 1000nF C5 10uF
Net
ztei
l
VCC
C4 100nFC1 100uF
Oszillator
Dr
Bild 26 Zusatzlicher Filter in der Stromversorungsleitung des Grundtaktoszillators
Eine weitere Schutzmaßnahme vor Spannungsspitzen bieten die reichlich vor-
handene Abblockkondensatoren. Es wurden nicht nur IC-Sockel mit eingebautem
Abblockkondensator verwendet, sondern zusatzlich moglichst nah an “Storquel-
len” wie RAMs und FPGA Kondensatoren angeschlossen.
5.5.2 Signalleitungen
Da auf allen Taktleitungen sowie dem Interface-Bus relativ hohe Frequen-
zen auftauchen, wurden diese Leitungen mit Abschlußwiderstanden versehen, um
Reflektion am Leitungsende zu minimieren. Fur die Berechnung dieser Abschluß-
widerstande, muß man den Wellenwiderstand der Leitungen berucksichtigen und
versuchen, einen Abschluß moglichst nahe an diesem Wellenwiderstand zu fin-
den. Denn nur bei einem Abschluß mit dem Wellenwiderstand entstehen keine
52

Kapitel 5 Realisierung der Hardware
Reflektionen am Leitungsende. Dabei muß als zweite Beschrankung der maxi-
male Ausgangsstrom der Treiber berucksichtigt werden, der nicht uberschritten
werden darf.
Bild 27 zeigt das Prinzip des Abschlusses, der als Thevenin-Terminierung
bezeichnet wird [3]. Hochfrequenzmaßig sind VCC und GND kurzgeschlossen,
wodurch sich als Abschlußwiderstand die Parallelschaltung der beiden Wider-
stande ergibt:
Ra =R1 �R2
R1 +R2
Als Belastung fur den Ausgang ergibt sich im Low-Zustand (UoL am Ausgang
des Treibers) der Strom IL, zu :
IL =UV CC � UoL
R1� UoL
R2� UV CC
R1
fur UoL � 0. Entsprechend erhalt man fur den High-Zustand (UoH ) die Belastung
zu
IH =UV CC � UoH
R1� UoH
R2� �UV CC
R2
fur UoH � UV CC
R1
R2
VCC
I
Uo
Leitung
Bild 27 Thevenin-Terminierung eines Gatterausgangs
Eine genaue Berechnung des Wellenwiderstandes der Leitung ist sehr auf-
wendig, da die Geometrie der Leiterbahn berucksichtigt werden muß. Da das
Signal im allgemeinen uber mehrere Stecker und somit auch unterschiedliche
Leitungsformen gefuhrt wird, wurde der Einfachheit halber ein Schatzwert von
100 zugrunde gelegt [3].
Die Treiber der 74F-Serie konnen leicht 24 mA treiben, so daß sich fur
R1 = 180 und R2 = 220 ergeben. Der Wellenwiderstand ergibt sich dann
zu Ra = 99. Die Ausgange der FPGAs konnen aber nur 12mA treiben, womit
sich rechnerisch R1 = 360 und R2 = 440 ergibt. Um nicht bis an die
53

Kapitel 5 Realisierung der Hardware
Belastungsgrenze der FPGAs zu gehen, wurden beide Widerstande zu R1 = R2 =470 gewahlt. Daraus folgt eine hochfrequenzmaßiger Abschlußwiderstand von
235. Einige Leitungen wie der Bus zwischen Ramcontroller und Rechenfeld
sind bidirektional, deshalb wurden in einem solchen Fall Abschlußwiderstande an
beiden Enden der Leitung vorgesehen, die dann jeweils den Wert 1k haben. Der
selbe Wert wurde fur die beiden Abschlusse des Interface-Bus gewahlt, der sich
in einen horizontalen und einen vertikalen Bus aufteilt und deshalb auch zweimal
abgeschlossen wird.
Die resultierende Abschlußwiderstande weichen zwar relativ stark von dem
zugrundegelegeten Wellenwiderstand von 100 ab, fur die Praxis erwiesen sich
diese Abschlusse jedoch als ausreichend.
Ein besonderes Problem stellt die Leitung fur BSCLK dar, die 64 MHz uber
ein Flachbandkabel vom Interface-Adapter zum Interface transportieren muß. Dies
fuhrte in der Testphase zu erheblichen Problemen. Deshalb wurde fur dieses
Signal das Flachbandkabel maßgeschneidert: Die Leitung, die das Signal BSCLK
transportiert, wurde an beiden Enden aufgeschnitten und durch ein abgeschirmtes
Kabel ersetzt.
Bei der Konzeption der Platinen wurde die Wichtigkeit der Abschlußwider-
stande unterschatzt, weshalb keine Abschlußwiderstande auf dem Bus zwischen
Rechenfeld und Ramcontroller vorgesehen wurden. Sie werden jetzt nachtraglich
uber die Meßstecker auf der Ramcontroller- bzw. Rechenfledplatine angeschlos-
sen. Ebenfalls nachtraglich wurden die Abschlußwiderstande fur das Taktsignal
ComCLK auf der Unterseite der Rechenfeldplatine eingebaut. Das Signal ist jetzt
dreimal mit jeweils 1k gegen Masse und VCC abgeschlossen. Problematisch ist
der Abschluß der zusatzlichen Taktsignale, die uber den global Bus transportiert
werden sollen. Da hier nicht klar ist, welches Signal von einem 74F-Treiber an-
gesteuert wird (im Fall des Clocksignals) und welches von einem FPGA-Ausgang
(im Fall eines globalen Steuersignals), konnen nicht alle Abschlusse festgelegt
werden. So wurde fur die Verteilung des CLKa-Signals die entsprechende Lei-
tung terminiert, wahrend alle anderen GPBUS-Signale offen sind.
5.6 Test
Da zum Zeitpunkt der Fertigstellung dieser Diplomarbeit das Interface noch
nicht verfugbar war, konnten nur einige grundlegende Tests in der Kommunikation
durchgefuhrt werden, wobei das XC4000 Demoboard von XILINX als Interface-
Ersatz diente [16]. Die Programmierung erfolgte mit Hilfe der XChecker Soft-
und Hardware von XILINX [17]. Sie ermoglicht es, ein FPGA uber die serielle
Schnittstelle eines Rechner zu programmieren.
54

Kapitel 5 Realisierung der Hardware
Im einzelnen wurden folgende Tests durchgefuhrt:
• Testen der Adreßdecodierung und Programmierung mehrerer FPGAs
nacheinander.
• Test der Kommunikation zwischen Interface und Ramcontroller. Es
wurden auf denselben Bits des IFBUS Daten gelesen und geschrieben, um
den Multiplexmechanismus zu testen. Die Datenubertragung lief auch mit
dem “letzten” Ramcontroller am Interfacebus erfolgreich bei 8 MHz.
• Test der Kommunikation zwischen Ramcontroller und Rechenfeld. Auch
hier wurde auf denselben Bits Daten in beide Richtungen geschickt, um den
Multiplexmechanismus zu uberprufen, sowie die am weitesten auseinander-
liegenden FPGAs angeschlossen, um den Fall der langsten Signallaufzeit ab-
zudecken. Dabei erwies es sich als notwendig, am Ramcontroller Abschluß-
widerstande an den Bus anzuschließen (vgl. vorangegangenen Abschnitt).
Dieser Test lief ebenfalls bei 8MHz erfolgreich.
• Test der Kommunikation zwischen Ramcontroller und RAM. Auch dieser
Test verlief bei 8MHz erfolgreich, sowohl bezuglich des Adreß- als auch des
Datenmultiplexens.
• Test der Kommunikation innerhalb des Rechenfeldes. Diese Kommuni-
kation ist die einfachste, da sie ohne Multiplexen auskommt. Deshalb war
der erfolgreiche Test bei 8MHz zu erwarten. Als weitergehender Test wurde
diese Kommunikation mit Hilfe eines zusatzlichen Taktsignals, das mit CLKa
erzeugt und uber GPBUS0 verteilt wurde, bei 16MHz getestet und verlief
ebenfalls erfolgreich. Damit ist es prinzipiell moglich, den inneren Teil des
Rechenfeldes mit der doppelten Taktfrequenz laufen zu lassen wie die Ran-
der bzw. die Ramcontroller. Dies stellt aber hohe Anforderungen bei der
Entwicklung eines Algorithmus, die in jedem Fall in COMPAR zu erbringen
waren.
Da die Korrektheit der Signale nur mit einem Logic Analyser festgestellt werden
konnte, wurden jeweils nur vier Bit der 24 Bit breiten Busse getestet.
5.7 Verbesserungsvorschlage zur Realisierung
Hardwaretechnisch mußte mehr Gewicht auf den korrekten Abschluß aller
Leitungen mit Abschlußwiderstanden gelegt werden. Der Hochfrequenzaspekt
der Signale bei 8 MHz wurde unterschatzt. Schließt man an den Treiber eines
8MHz-Signales nur offenes Stuck Kabel von 40–50 cm wird die Signalform
durch Reflektionen am Leitungsende so stark uberlagert und mit Uberschwingern
versehen, daß von der ursprunglichen Signalform faßt nichts mehr ubrig bleibt.
Als Verbesserung sollten bei kunftigen Platinenlayouts alle Leitungen, die von
FPGAs gesteuert werden mit mindestens jeweils ein 1k gegen VCC und GND
55

Kapitel 5 Realisierung der Hardware
abgeschlossen werden. Diese Fehleinschatzung ist aber nicht so gravierend, da die
Terminierungen ohne Probleme an den vorhandenen Meßsteckern angeschlossen
werden konnen.
56

Kapitel 6 Zusammenfassung
6 Zusammenfassung
In der vorliegenden Arbeit wurde ein zweidimensionales, synchrones Rechen-
feld entworfen und realisiert, auf dem Algorithmen abgearbeitet werden konnen,
die mit dem Entwurfssystem COMPAR erzeugt werden.
Das Rechenfeld basiert auf XILINX FPGAs vom Typ XC4005. Es stellt eine
Gatterkapazitat von 45000 Gattern bei einer Taktrate von 8 MHz zur Verfugung.
Die Datenbusbreite betragt 24 Bit. Pro Ramcontroller konnen maximal 384kB
RAM angeschlossen werden, was einem Gesamtspeicher von 2304kB entspricht.
Die maximale Datenrate zum Interface betragt 24 MB/s sowohl fur die Lese- als
auch die Schreibrichtung, insgesamt also 48 MB/s.
In dieser Arbeit wurden die Kommunikationsschemata der Teilprozessoren
(FPGAs) aus dem Gesamtkonzept von PAr2 entwickelt. Durch eine Beschrei-
bung der Hardware auf Registerebene und der Einfuhrung einheitlicher Signalbe-
zeichnungen als Schnittstellen innerhalb der FPGAs wurde eine Modellierung des
Rechenfeldes unabhangig von der tatsachlichen Hardwarerealisierung gefunden.
Dieses Registermodell (Bild 21,Kapitel 4.4) dient als Ausgangspunkt fur die Re-
prasentation der Hardware in abstrakteren Beschreibungen wie sie in COMPAR
notwendig sind.
Neben der realisierten Hardware ist zum Betrieb des Rechenfeldes eine
Schnittstelle in COMPAR notig, sowie ein Interface, um das Rechenfeld an einem
Host betreiben zu konnen. Momentan wird an diesem Interface gearbeitet, die
Fertigstellung in Kurze wird dann auch ein umfangreiches Testen der Hardware
von PAr2 ermoglichen.
57

Kapitel 6 Zusammenfassung
Literaturverzeichnis
[1] U. Arzt, J. Teich, and L. Thiele. The concepts of COMPAR: A compiler for
massive parallel architectures. In Proc. International Symposium on Circuits
and Systems (ISCAS), pages 681–684, San Diego, May 1992.
[2] K.M. Chandy and J. Misra. Parallel Program Design. Addison-Wesley Publ.
Comp., Reading, Mass., 1988.
[3] R. Dreyer. Strahenschutz, EMV-Aspekte beim Leiterplattendesign. ELRAD,
pages 56–61, Sept. 1992.
[4] M. Gokhale et.al. Building and using a highly parallel programmable logic
array. IEEE Computer, pages 81–89, Jan. 1992.
[5] Fairchild. Fast Fairchild Advanced Schottky TTL. Fast Data Book. Fairchild,
1985.
[6] H.-J. Herpel and M. Glesner. A rapid prtoryping approach to requirements
validation of application specific embedded controllers. In ITG-Fachberich
122 , ITG-Fachtagung, pages 23–34, Nov. 1992.
[7] P. Knapp. Konzept und Implementierung einer Steuerung des PAr2-
Rechenfeldes durch das PSI-Interface. Diplomarbeit am Lehrstuhl fur Mi-
kroelektronik, Universitat, des Saarlandes, Saarbrucken, 1993.
[8] J. Konig. Programmable SBus Interface. Lehrstuhl fur Mikroelektronik,
Universitat des Saarlandes, 6600 Saarbrucken, 1993.
[9] J. N. Morris. Hardware design of a rapid prototyping reconfigurable logic
system. North Carolina State University, ECE Dept., Box 7911, Raleigh, NC
27695-7911, 1992.
[10]V. Roychowdhury, L. Thiele, S. K. Rao, and T. Kailath. On the localization
of algorithms for VLSI processor arrays. in: VLSI Signal Processing III, IEEE
Press, New York, pages 459–470, 1989.
[11]Cypress Semiconductor. CMOS/BiCMOS Data Book. Cypress Semiconduc-
tor,3901 North First St., San Jose, CA 95134, 1992.
[12]J. Teich and L. Thiele. Control generation in the design of processor arrays.
Int. Journal on VLSI and Signal Processing, 3(2):77–92, 1991.
[13]J. Teich and L. Thiele. A transformative approach to the partitioning of
processor arrays. In Proc. Int. Conf. on Application Specific Array Processors,
IEEE Computer Society Press, pages 4–20, Berkeley, August 1992.
[14]L. Thiele. Materialien zur Vorlesung Mikroelektronik 3. Lehrstuhl fur
Mikroelektronik, Universitat des Saarlandes, 6600 Saarbrucken, 1991.
58

Kapitel 6 Zusammenfassung
[15]XILINX. The XC4000 Data Book. XILINX, 2100 Logic Drive, San Jose, CA
95124, 1991.
[16]XILINX. XACT Reference Guide, The XC4000 Design Demonstration Board.
XILINX, 2100 Logic Drive, San Jose, CA 95124, 1992.
[17]XILINX. XACT Reference Guide, XChecker Universal Download/Readback
Cable and Logic Probe. XILINX, 2100 Logic Drive, San Jose, CA 95124,
1992.
[18]XILINX. The XC4000 Design Implementation User Guide. XILINX, 2100
Logic Drive, San Jose, CA 95124, 1992.
59

Anhang A Programm zur Bestimmung des Timing
Anhang A Programm zurBestimmung des Timing
Zur Bestimmung des optimalen Timings wurde ein C-Programm geschrieben,
das im folgenden abgedruckt ist. In der Datei calctime.h (Listing 1) sind alle
Zeiten vordefiniert, die Datei calctime.c (Listing 2) enthalt das eigentliche
Programm. Es entspricht den in Kapitel 4.3 hergeleiteten Zeitabhangigkeiten.
Das Ergebnis des Programmlaufs zeigt Listing 3.
/* CALCTIME.H */
/* Delaytime-definitions follow */
#define Tshort 3 /*max time two outputs connected
while switching to tristate */
#define Tch 0 /*min data hold after clock */
#define Tfza 20 /*max FPGA PAD clock to PAD tristate
to active (empirisch) */
#define Tfaz 20
#define Tpick 16 /*min FPGA data vaild before clock */
#define Tokop 12
#define Tpar 20 /*max delay RAM adresse read from
RCMux to PAD (empirisch)*/
#define Tpaw 37 /*max delay clk low to RAM adresse
write valid on PAD (empirisch)*/
/* External Buffers of the IFBus 74F245*/
#define Tbza 8 /*max Buffer tristate to active */
#define Tbd 6 /*max Buffer propagation delay */
#define Tboz Tfza-Tbza /*min Buffer outputs disable */
/* RAM-Specifications: 12ns RAM CY7B185/186 */
#define Trdoe 6 /*max: RAM OE low to data valid */
#define Taa 12 /*min: RAM adress to data valid */
#define Tsa 0 /*min: Adress set-up to write start */
#define Twr 8 /*min: RAM write pulse width */
#define Tdw 0 /*min: Data valid to WE */
#define Tdh Tpick+Tbd /*min: data hold valid before clock */
#define Tdrf 8 /* Propagation delay on RF-LOOP wire */
#define Tdif 11 /* Propagation delay on IFBUS wire */
#define resolution 8 /* Number of Segments between one Clocktime */
Listing 1 calctime.h
60

Anhang A Programm zur Bestimmung des Timing
/*
Optimal timing computation for FPGA-Array
Tobias Blickle 11.9.92
*/
#include "calctime.h"
#include <stdio.h>
#define rows 13
#define LARGE 1E20
set_up_table(LPA,LPb,a,b,c,d,e)
int *LPA;
int *LPb;
int a,b,c,d,e;
{
/*input data follows , see documentation*/
LPA[0]=b-a; LPb[0]=Tfza-Tpick;
LPA[1]=a; LPb[1]=2*Tdrf+Tpick+Tfza;
LPA[2]=a-c; LPb[2]=Tbza+Tpick;
LPA[3]=a; LPb[3]=Tokop+Tbd+Tpick;
LPA[4]=c; LPb[4]=Tfaz-Tshort-Tbza;
LPA[5]=b-a; LPb[5]=2*Tdif+Tpick+Tokop+Tbza;
LPA[6]=b-a; LPb[6]=2*Tdif+Tfza+Tpick;
LPA[7]=a; LPb[7]=Tpar+Taa+Tpick;
LPA[8]=a-d; LPb[8]=Trdoe+Tpick;
LPA[9]=d; LPb[9]=Tfaz-Tshort-Trdoe;
LPA[10]=e-a; LPb[10]=Tpaw+Tsa;
LPA[11]=e-a; LPb[11]=Tfza+Tdw;
LPA[12]=b-e; LPb[12]=Twr;
}
main()
{
int *A=(int *)calloc(rows,sizeof(int));
int *b=(int *)calloc(rows,sizeof(int));
int rueck;
int am,cm,dm,em;
int aopt,copt,dopt,eopt;
double val=LARGE;
double minimum;
char *command="cat calctime.h\n";
printf("Computing optimal timing for FPGA array.\n\n");
printf("The maximal overlay time of two outputs beeing active\n");
printf("at the same time ist set to %d ns.\n",Tshort);
printf("The following restrictions are set:\n\n");
fflush(stdout);
system(command);
/* Enumerate all possible values */
for (am=1;am<resolution;++am)
for (cm=1; cm<resolution;++cm)
for (dm=1;dm <resolution;++dm)
61

Anhang A Programm zur Bestimmung des Timing
for (em=1;em <resolution;++em)
{
set_up_table(A,b,am,resolution,cm,dm,em);
rueck=get_minimum(A,b,rows,&minimum);
if (rueck==0 && minimum<val)
{
val=minimum;aopt=am;copt=cm;dopt=dm;eopt=em;
}
}
if (val==LARGE)
{
printf("No solution was found !\n");
printf("Please check restrictions !\n");
}
else
{
printf("Soloution found:\n");
printf("\ta\tb\tc\td\te\t tau[ns]\t BSCLK[MHz]\t ComCLK[Mhz]\n");
printf("\t%d\t%d\t%d\t%d\t%d\t%10.5f\t%10.5f\t%10.5f\n",
aopt,resolution,copt,dopt,eopt,val,1000/val,125/val);
}
printf("\nTo edit other restrictions change the file ’calctime.h’\n");
printf("and re-run ’make calctime’ to compute output.\n");
return(0);
}
/*
Determines the minimum x,
subj. to a*x >= b
returns 0, if solution is valid
*/
int get_minimum(a,b,r,min)
int *a,*b,r;
double *min;
{
register int i;
*min=-LARGE;
for (i=0;i<r;++i)
{
if (a[i]==0) return (-2);
if (a[i]<0 && b[i]>0) return (-3);
if ((double)b[i]/(double)a[i]>=*min)
*min=(double)b[i]/(double)a[i];
}
if (*min==-LARGE) return -1;
return 0;
}
Listing 2 calctime.c
62

Anhang A Programm zur Bestimmung des Timing
Computing optimal timing for FPGA array.
The maximal overlay time of two outputs beeing active
at the same time ist set to 3 ns.
The following restrictions are set:
/* Delaytime-definitions follow */
#define Tshort 3 /*max time two outputs connected
while switching to tristate */
#define Tch 0 /*min data hold after clock */
#define Tfza 20 /*max FPGA PAD clock to PAD tristate
to active (empirisch) */
#define Tfaz 20
#define Tpick 16 /*min FPGA data vaild before clock */
#define Tokop 12
#define Tpar 20 /*max delay RAM adresse read from
RCMux to PAD (empirisch)*/
#define Tpaw 37 /*max delay clk low to RAM adresse
write valid on PAD (empirisch)*/
/* External Buffers of the IFBus 74F245*/
#define Tbza 8 /*max Buffer tristate to active */
#define Tbd 6 /*max Buffer propagation delay */
#define Tboz Tfza-Tbza /*min Buffer outputs disable */
/* RAM-Specifications: 12ns RAM CY7B185/186 */
#define Trdoe 6 /*max: RAM OE low to data valid */
#define Taa 12 /*min: RAM adress to data valid */
#define Tsa 0 /*min: Adress set-up to write start */
#define Twr 8 /*min: RAM write pulse width */
#define Tdw 0 /*min: Data valid to WE */
#define Tdh Tpick+Tbd /*min: data hold valid before clock */
#define Tdrf 8 /* Propagation delay on RF-LOOP wire */
#define Tdif 11 /* Propagation delay on IFBUS wire */
#define resolution 8 /* Number of Segments during one Clocktime */
Soloution found:
a b c d e tau[ns] BSCLK[MHz] ComCLK[Mhz]
4 8 1 1 7 14.50000 68.96552 8.62069
To edit other restrictions change the file ’calctime.h’
and re-run ’make calctime’ to compute output.
Listing 3 Ergebnis des Programmlaufes von calctime
63

Anhang B Technische Angaben Rechenfeld
Anhang B Technische Angaben Rechenfeld
Der Schaltplan des Rechenfeldes ist auf der folgenden Seite abgedruckt. Die
Reproduktionsqualitat ist leider nicht sehr gut, da das Orginal im Format DIN A0
erstellt ist. Dieser Plan enthalt nicht die auf der Platine vorhandenen Meßstecker.
An jedem FPGA ist fur jede Richtung ein Meßstecker vorhanden, der den lokalen
Bus in einem 26poligen Wannenstecker zuganglich macht. Mit diesen Stecker ist
es moglich, auch kleinere Rechenfelder zu realiseren, indem die nicht benotigten
FPGAs uberbruckt.
Der Schaltplan des Blocks PRGRBK, der die Tristatetreiber enthalt, ist in
Bild 36 im Anhang E gezeigt. Er gilt gleichermaßen fur die Rechfeld- wie fur
die Ramcontrollerplatine.
Auf den folgenden Seiten sind die Pinbelegungen der Stecker CN1–CN7 der
Rechenfeld-Platine aufgelistet. Die Belegungen der Meßstecker JM1 – JM45
sind in Anhang G gegeben. Die Stecker JM1–JM9 sind vom Typ A, wahrend
JM10–JM45 vom Typ B sind.
Zu den Verbindungen CN2–CN7, die zu den Ramcontroller fuhren ist folgen-
des zu bemerken: Da es sich bei diesen Stecker und seinem Gegenstuck auf der
Ramcontroller-Platine um VG64–Verbinder mit 90� Anschlussen handelt, ist die
Nummerierung — obwohl die Stecker miteinander verbunden werden — spiegel-
verkehrt. Dies ist bereits in der hier aufgefuhrten Belegungstabelle berucksichtigt.
64

Anhang B Technische Angaben Rechenfeld
Bild 28 Schaltplan des Rechenfeldes
65

Anhang B Technische Angaben Rechenfeld
B3
A1
A2
C5
B4
A3
B5
B6
A5
C7
B7
A6
A7
A8
C9
B9
A9
B10
C10
A10
A11
B11
B12
A13
A14
C12
B13
B14
T2
P4
R3
R4
P5
T3
T4
R6
T5
P7
R7
T6
T7
T8
P9
R9
T9
R10
P10
T10
T11
R11
T13
T14
P12
R13
T15
T16
B2
B1
D3
C2
C!
E3
E2
E1
F2
F1
G3
G2
G1
H1
J3
J2
J1
K1
K2
K3
L1
L2
N1
P1
M3
N2
P2
R1
B16
D14
C15
D15
E14
C16
F15
E16
F16
G14
G15
G16
H16
H15
J15
J16
K16
K15
K14
L16
M16
L15
P16
M14
N15
P15
N14
R16
PG
CK
4,A
1
CS
1,A
2A8
A9
A10
A11
A12
A13
A14
SG
CK
1,A
15
PGCK1,A16
A17
TDI
TCK
TMS
SGCK2
PG
K2
HD
C
LD
C
ER
R,IN
IT
SG
KC
3
PGCK3
D7
D6
D5
CS0
D4
D3
RS
D2
D1
RDY/BUSY
D0,DIN
SGCK4,DOUT
A0,W
SA3
A4
A5
A6
A7
XC4005-PG156
DL
3
DL
4
DL
5
DL
6
DL
7
DL
8
DL
9
DL
10
DL
11
DL
12
DL
13
DL
14
DL
15
DL
16
DL
17
DL
18
DL
19
DL
20
DL
21
DL
22
GP 0 (ICLK)
DIN
DD 0
DD 1
DD 2
DD 3
DD 4
DD 5
DD 6
DD 7
DD 8
DD 9
DD 10
DD 11
DD 12
DD 13
DD 14
DD 23
DD 22
DD 21
DD 20
DD 19
DD 18
DD 17
DD 16
DD 15
GP 3
GP 7
DR
0
DR
1
DR
2
DR
3
DR
4
DR
5
DR
6
DR
7
DR
8
DR
9
DR
10
DR
11
DR
12
DR
13
DR
14
DR
15
DR
16
DR
17
DR
18
DR
19
DR
20
DR
21
DR
22
DR
23
INIT
GP
1
GP
4
RIP
DU 0
DU 1
DU 2
DU 3
DU 4
DU 5
DU 6
DU 7
DU 8
DU 9
DU 10
DU 11
DU 12
DU 13
DU 14
DU 15
DU 16
DU 17
DU 18
DU 20
DU 21
DU 22
DU 23
DU 19
GTS
GSR
GP 2
GP 5
GP
8
Co
mC
lk
DL
0
DL
1
DL
2
DL
23
GP
6
GP
9
Rechenfeld
Bild 29 Pinbelegung eines Rechenfeld-FPGAs (Sicht entsprechend dem XILINX-Tool XACT)
66

Anhang B Technische Angaben Rechenfeld
DONER15
CCLKR2
PROGR14
DINP4
INITH15
RTRIG(M0)A16
RDATA(M1)A15
RCLK(M2)B15
RIPD14
COMCLK
B2
GSR
B13
GTS
C12
GP0 GSCK4T2
GP1 GSCK3R16
GP2 GSCK2B14
GP3 GPCK3T15
GP4 GPCK2B16
GP5 GPCK1B3
GP6 GPCK4P2
DU0
A1
DU1
A2
DU2
C5
DU3
B4
DU4
A3
DU5
B5
DU6
B6
DU7
A5
DU8
C7
DU9
B7
DU10
A6
DU11
A7
DU12
A8
DU13
C9
DU14
B9
DU15
A9
DU16
B10
DU17
C10
DU18
A10
DU19
A11
DU20
B11
DU21
B12
DU22
A13
DU23
A14
DL0D3
DL1C2
DL2C1
DL3E3
DL4E2
DL5E1
DL6F2
DL7F1
DL8G3
DL9G2
DL10G1
DL11H1
DL12J3
DL13J2
DL14J1
DL15K1
DL16K2
DL17K3
DL18L1
DL19L2
DL20N1
DL21P1
DL22M3
DL23N2
DD0
R3
DD1
R4
DD2
P5
DD3
T3
DD4
T4
DD5
R6
DD6
T5
DD7
P7
DD8
R7
DD9
T6
DD10
T7
DD11
T8
DD12
P9
DD13
R9
DD14
T9
DD15
R10
DD16
P10
DD17
T10
DD18
T11
DD19
R11
DD20
T13
DD21
T14
DD22
P12
DD23
R13
DR0C15
DR1D15
DR2E14
DR3C16
DR4F15
DR5E16
DR6F16
DR7G14
DR8G15
DR9G16
DR10H16
DR11J15
DR12J16
DR13K16
DR14K15
DR15K14
DR16L16
DR17M16
DR18L15
DR19P16
DR20M14
DR21N15
DR22P15
DR23N14
GP7T16
GP8B1
GP9R1
XC4005PG156
Rechenfeld - FPGA
Bild 30 Pinbelegung eines Rechenfeld-FPGAs
67
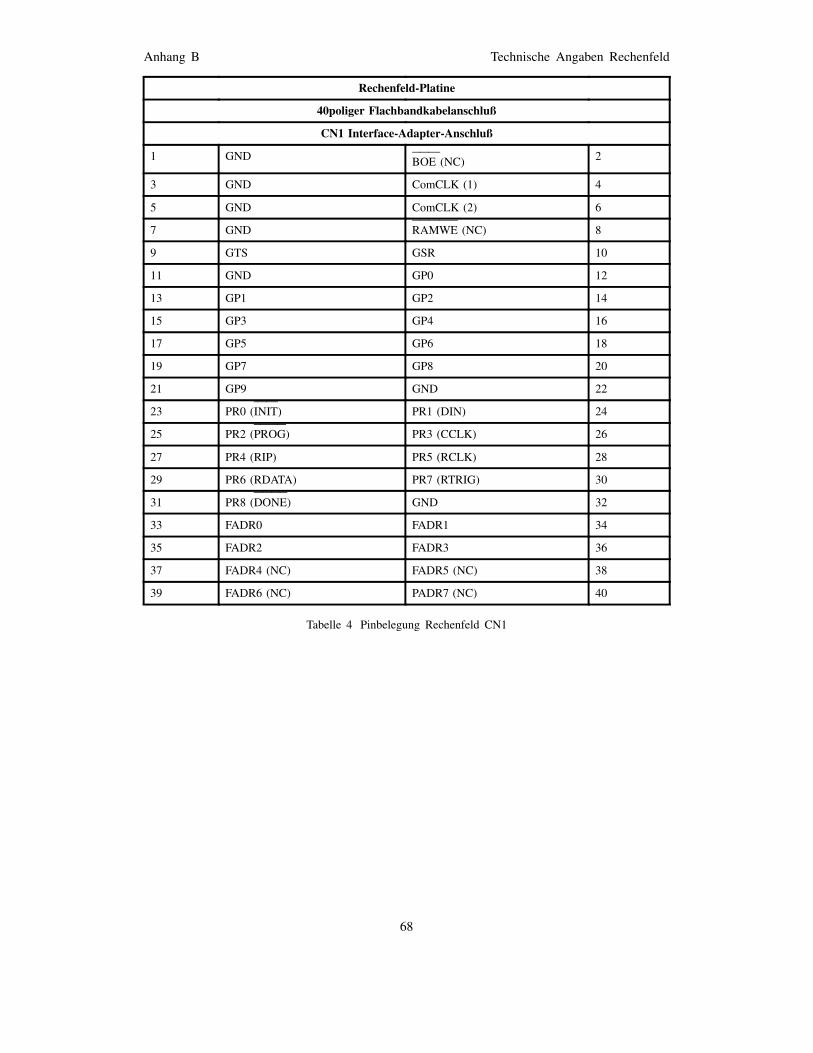
Anhang B Technische Angaben Rechenfeld
Rechenfeld-Platine
40poliger Flachbandkabelanschluß
CN1 Interface-Adapter-Anschluß
1 GNDBOE (NC)
2
3 GND ComCLK (1) 4
5 GND ComCLK (2) 6
7 GND RAMWE (NC) 8
9 GTS GSR 10
11 GND GP0 12
13 GP1 GP2 14
15 GP3 GP4 16
17 GP5 GP6 18
19 GP7 GP8 20
21 GP9 GND 22
23 PR0 (INIT) PR1 (DIN) 24
25 PR2 (PROG) PR3 (CCLK) 26
27 PR4 (RIP) PR5 (RCLK) 28
29 PR6 (RDATA) PR7 (RTRIG) 30
31 PR8 (DONE) GND 32
33 FADR0 FADR1 34
35 FADR2 FADR3 36
37 FADR4 (NC) FADR5 (NC) 38
39 FADR6 (NC) PADR7 (NC) 40
Tabelle 4 Pinbelegung Rechenfeld CN1
68

Anhang B Technische Angaben Rechenfeld
Rechenfeld-Platine
VG 64 Leiste mannlich (s. Bemerkung im Text)
CN 2 - CN 7 Ramcontrolleranschluß
A1 GND GND C1
A2 DRF1 DRF0 C2
A3 DRF3 DRF2 C3
A4 DRF5 DRF4 C4
A5 DRF7 DRF6 C5
A6 GND GND C6
A7 DRF9 DRF8 C7
A8 DRF11 DRF10 C8
A9 DRF13 DRF12 C9
A10 DRF15 DRF14 C10
A11 GND GND C11
A12 DRF17 DRF16 C12
A13 DRF19 DRF18 C13
A14 DRF21 DRF20 C14
A15 DRF23 DRF22 C15
A16 GND GND C16
A17 GP8 GP9 C17
A18 GP6 GP7 C18
A19 GP4 GP5 C19
A20 GP2 GP3 C20
A21 GP0 GP1 C21
A22 GND GND C22
A23 SELECT GND C23
A24 RTRIG (PR7) DONE (PR8) C24
A25 RCLK (PR5) RDATA (PR6) C25
A26 CCLK (PR3) RIP (PR4) C26
A27 DIN (PR1) PROG (PR2) C27
A28 GND INIT (PR0) C28
A29 GSR GND C29
A30 GND GND C30
A31 ComCLK GTS C31
A32 GND GND C32
Tabelle 5 Pinbelegung Rechenfeld CN2 – CN7
69

Anhang C Technische Angaben Ramcontroller
Anhang C Technische AngabenRamcontroller
Auf der folgende Seite ist der Schaltplan des Ramcontrollers abgebildet,
anschließend folgt die Belegung des FPGAs sowie die Steckerbelegungen auf
der Platine.
Zu dem Stecker CN1 (Rechenfeldanschluß) gilt das gleiche wie beim Re-
chenfeld gesagte: Da es sich bei diesem Stecker und seinem Gegenstuck auf der
Rechenfeldseite um VG64 Verbinder mit 90� Anschlussen handelt, ist die Numme-
rierung — obwohl die Stecker miteinander verbunden werden — spiegelverkehrt.
Dies ist bereits in der hier aufgefuhrten Belegungstabelle berucksichtigt.
70

Anhang C Technische Angaben Ramcontroller
Bild 31 Schaltplan des Ramcontrollers
71
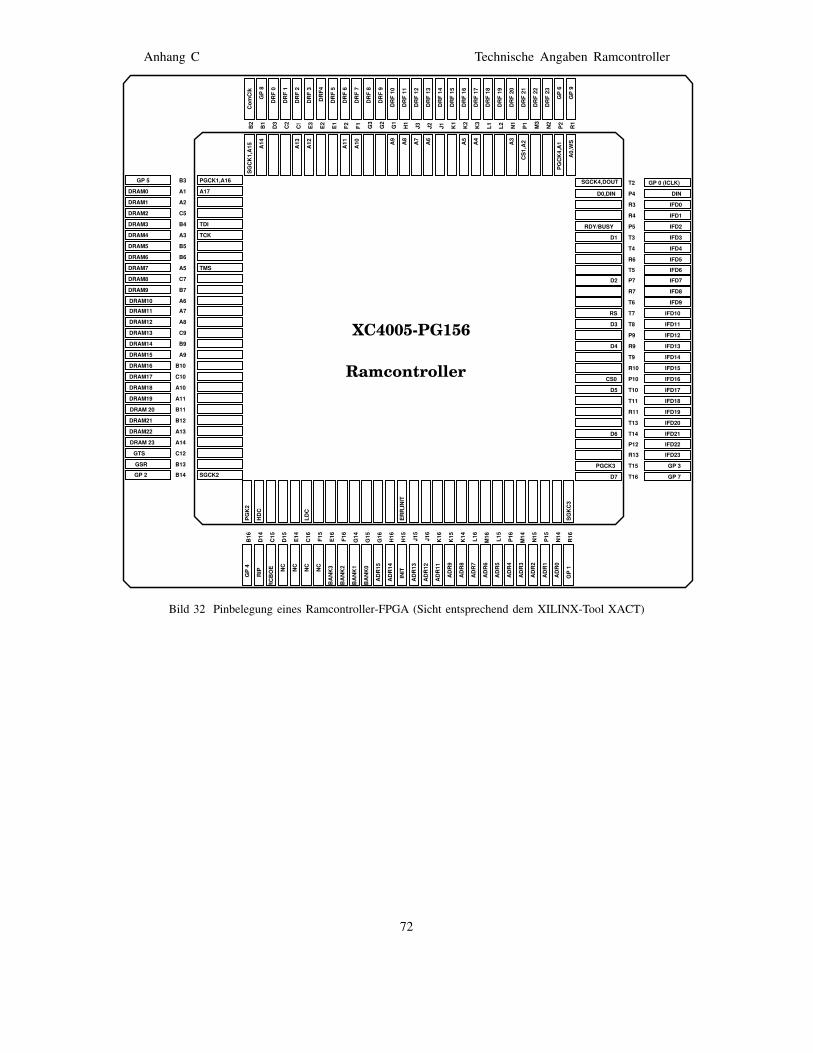
Anhang C Technische Angaben Ramcontroller
B3
A1
A2
C5
B4
A3
B5
B6
A5
C7
B7
A6
A7
A8
C9
B9
A9
B10
C10
A10
A11
B11
B12
A13
A14
C12
B13
B14
T2
P4
R3
R4
P5
T3
T4
R6
T5
P7
R7
T6
T7
T8
P9
R9
T9
R10
P10
T10
T11
R11
T13
T14
P12
R13
T15
T16
B2
B1
D3
C2
C!
E3
E2
E1
F2
F1
G3
G2
G1
H1
J3
J2
J1
K1
K2
K3
L1
L2
N1
P1
M3
N2
P2
R1
B16
D14
C15
D15
E14
C16
F15
E16
F16
G14
G15
G16
H16
H15
J15
J16
K16
K15
K14
L16
M16
L15
P16
M14
N15
P15
N14
R16
PG
CK
4,A
1
CS
1,A
2A8
A9
A10
A11
A12
A13
A14
SG
CK
1,A
15
PGCK1,A16
A17
TDI
TCK
TMS
SGCK2
PG
K2
HD
C
LD
C
ER
R,IN
IT
SG
KC
3
PGCK3
D7
D6
D5
CS0
D4
D3
RS
D2
D1
RDY/BUSY
D0,DIN
SGCK4,DOUT
A0,W
SA3
A4
A5
A6
A7
XC4005-PG156
DR
F 3
DR
F4
DR
F 5
DR
F 6
DR
F 7
DR
F 8
DR
F 9
DR
F 1
0
DR
F 1
1
DR
F 1
2
DR
F 1
3
DR
F 1
4
DR
F 1
5
DR
F 1
6
DR
F 1
7
DR
F 1
8
DR
F 1
9
DR
F 2
0
DR
F 2
1
DR
F 2
2
GP 0 (ICLK)
DIN
IFD0
IFD1
IFD2
IFD3
IFD4
IFD5
IFD6
IFD7
IFD8
IFD9
IFD10
IFD11
IFD12
IFD13
IFD14
IFD23
IFD22
IFD21
IFD20
IFD19
IFD18
IFD17
IFD16
IFD15
GP 3
GP 7
RC
BO
E NC
NC
NC
NC
BA
NK
3
BA
NK
2
BA
NK
1
BA
NK
0
AD
R15
AD
R14
AD
R13
AD
R12
AD
R11
AD
R9
AD
R8
AD
R7
AD
R6
AD
R5
AD
R4
AD
R3
AD
R2
AD
R1
AD
R0
INIT
GP
1
GP
4
RIP
DRAM0
DRAM1
DRAM2
DRAM3
DRAM4
DRAM5
DRAM6
DRAM7
DRAM8
DRAM9
DRAM10
DRAM11
DRAM12
DRAM13
DRAM14
DRAM15
DRAM16
DRAM17
DRAM18
DRAM 20
DRAM21
DRAM22
DRAM 23
DRAM19
GTS
GSR
GP 2
GP 5
GP
8
Co
mC
lk
DR
F 0
DR
F 1
DR
F 2
DR
F 2
3
GP
6
GP
9
Ramcontroller
Bild 32 Pinbelegung eines Ramcontroller-FPGA (Sicht entsprechend dem XILINX-Tool XACT)
72
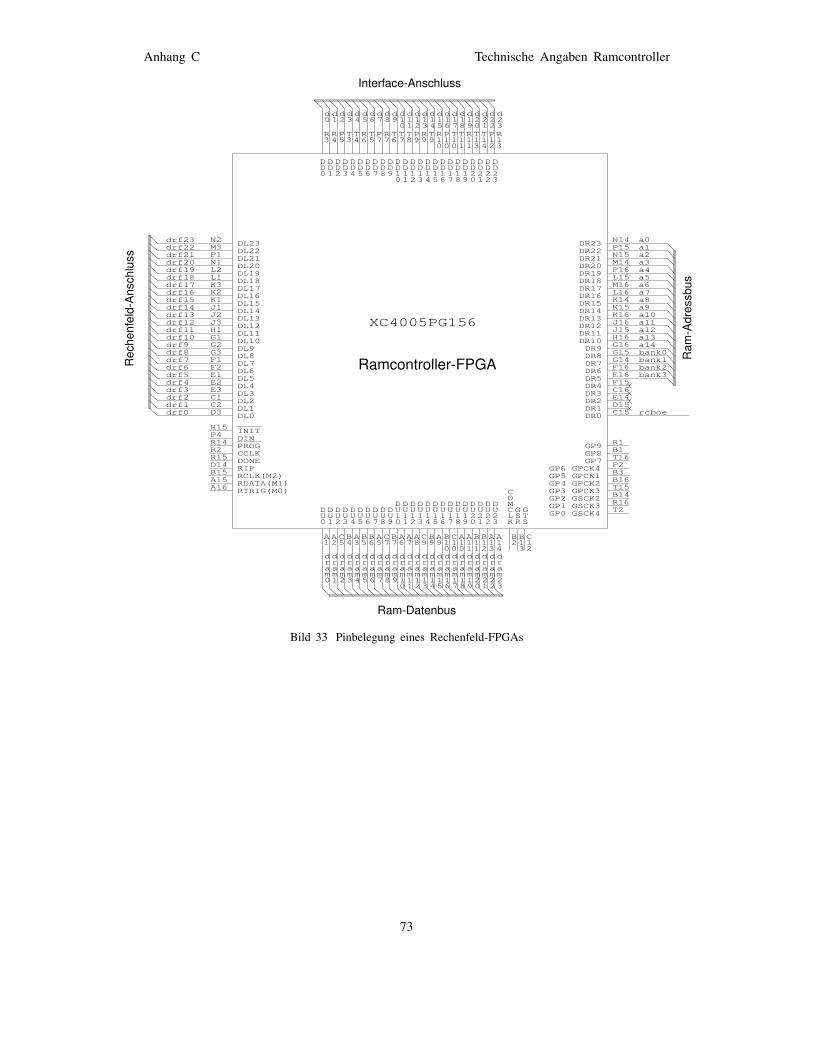
Anhang C Technische Angaben Ramcontroller
XC4005PG156
d15
d16
d17
d18
d19
d20
d21
d22
d23
d2d3d4d5d6d7d8d9d10
d11
d12
d13
d14
d0d1
DONER15
CCLKR2
PROGR14
DINP4
INITH15
RTRIG(M0)A16
RDATA(M1)A15
RCLK(M2)B15
RIPD14
COMCLK
B2
GSR
B13
GTS
C12
GP0 GSCK4T2
GP1 GSCK3R16
GP2 GSCK2B14
GP3 GPCK3T15
GP4 GPCK2B16
GP5 GPCK1B3
GP6 GPCK4P2
DU0
A1
DU1
A2
DU2
C5
DU3
B4
DU4
A3
DU5
B5
DU6
B6
DU7
A5
DU8
C7
DU9
B7
DU10
A6
DU11
A7
DU12
A8
DU13
C9
DU14
B9
DU15
A9
DU16
B10
DU17
C10
DU18
A10
DU19
A11
DU20
B11
DU21
B12
DU22
A13
DU23
A14
DL0D3
DL1C2
DL2C1
DL3E3
DL4E2
DL5E1
DL6F2
DL7F1
DL8G3
DL9G2
DL10G1
DL11H1
DL12J3
DL13J2
DL14J1
DL15K1
DL16K2
DL17K3
DL18L1
DL19L2
DL20N1
DL21P1
DL22M3
DL23N2
DD0
R3
DD1
R4
DD2
P5
DD3
T3
DD4
T4
DD5
R6
DD6
T5
DD7
P7
DD8
R7
DD9
T6
DD10
T7
DD11
T8
DD12
P9
DD13
R9
DD14
T9
DD15
R10
DD16
P10
DD17
T10
DD18
T11
DD19
R11
DD20
T13
DD21
T14
DD22
P12
DD23
R13
DR0C15
DR1D15
DR2E14
DR3C16
DR4F15
DR5E16
DR6F16
DR7G14
DR8G15
DR9G16
DR10H16
DR11J15
DR12J16
DR13K16
DR14K15
DR15K14
DR16L16
DR17M16
DR18L15
DR19P16
DR20M14
DR21N15
DR22P15
DR23N14
GP7T16
GP8B1
GP9R1
a0a1a2a3a4a5drf18
drf19drf20drf21drf22drf23
drf17
drf9drf10drf11drf12drf13drf14drf15drf16
a6a7a8a9a10a11a12a13a14bank0bank1bank2bank3
drf1drf2drf3drf4drf5drf6drf7drf8
drf0 rcboe
dram0
dram1
dram2
dram3
dram4
dram5
dram6
dram7
dram8
dram9
dram10
dram11
dram12
dram13
dram14
dram15
dram16
dram17
dram18
dram19
dram20
dram21
dram22
dram23
Ramcontroller-FPGA
Interface-Anschluss
Rec
henf
eld-
Ans
chlu
ss
Ram-Datenbus
Ram
-Adr
essb
us
Bild 33 Pinbelegung eines Rechenfeld-FPGAs
73
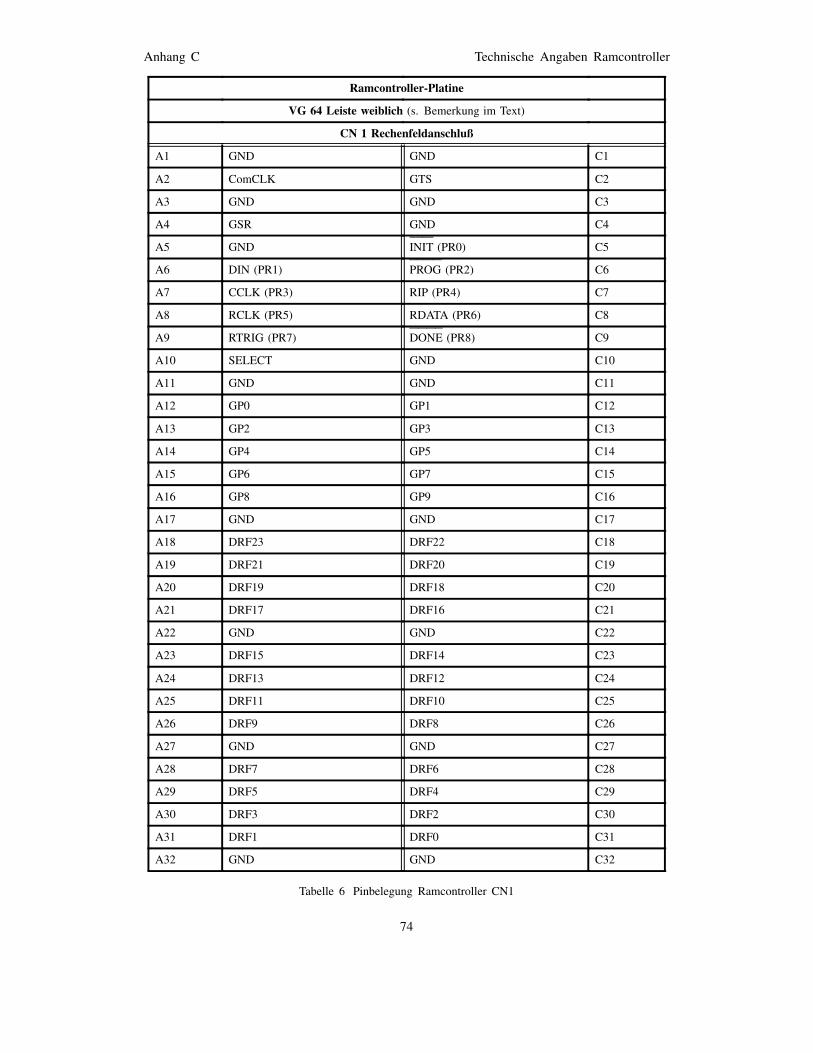
Anhang C Technische Angaben Ramcontroller
Ramcontroller-Platine
VG 64 Leiste weiblich (s. Bemerkung im Text)
CN 1 Rechenfeldanschluß
A1 GND GND C1
A2 ComCLK GTS C2
A3 GND GND C3
A4 GSR GND C4
A5 GND INIT (PR0) C5
A6 DIN (PR1) PROG (PR2) C6
A7 CCLK (PR3) RIP (PR4) C7
A8 RCLK (PR5) RDATA (PR6) C8
A9 RTRIG (PR7) DONE (PR8) C9
A10 SELECT GND C10
A11 GND GND C11
A12 GP0 GP1 C12
A13 GP2 GP3 C13
A14 GP4 GP5 C14
A15 GP6 GP7 C15
A16 GP8 GP9 C16
A17 GND GND C17
A18 DRF23 DRF22 C18
A19 DRF21 DRF20 C19
A20 DRF19 DRF18 C20
A21 DRF17 DRF16 C21
A22 GND GND C22
A23 DRF15 DRF14 C23
A24 DRF13 DRF12 C24
A25 DRF11 DRF10 C25
A26 DRF9 DRF8 C26
A27 GND GND C27
A28 DRF7 DRF6 C28
A29 DRF5 DRF4 C29
A30 DRF3 DRF2 C30
A31 DRF1 DRF0 C31
A32 GND GND C32
Tabelle 6 Pinbelegung Ramcontroller CN1
74
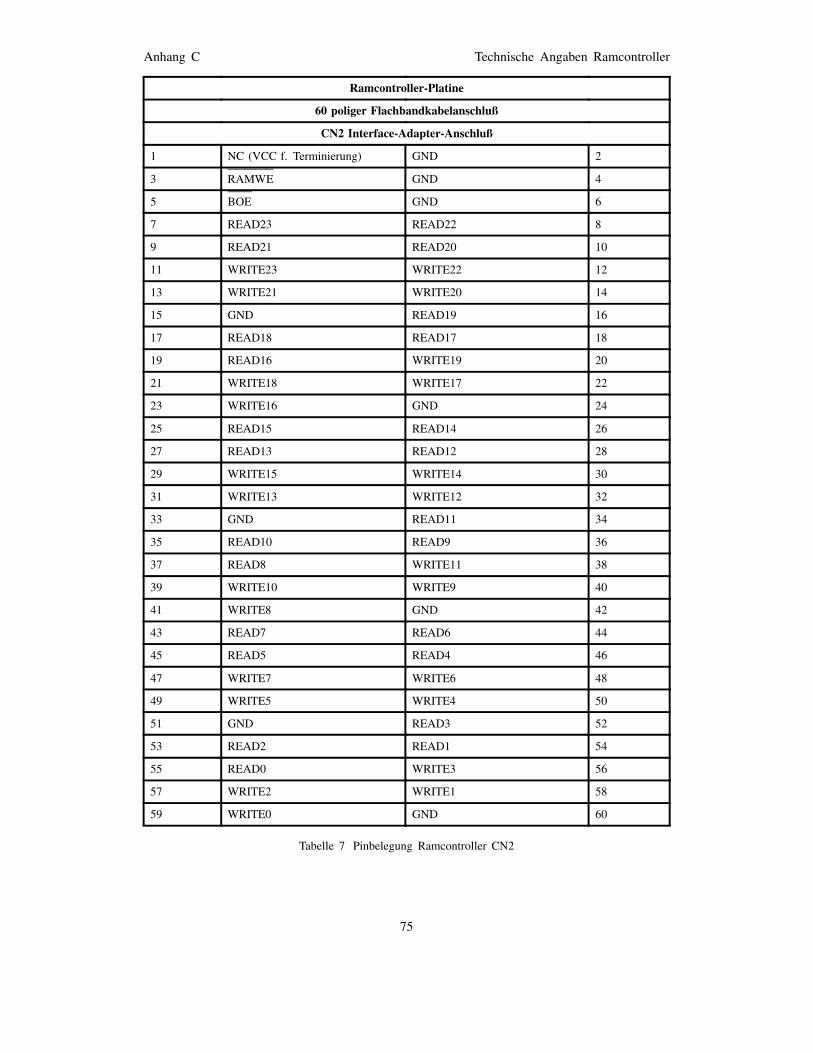
Anhang C Technische Angaben Ramcontroller
Ramcontroller-Platine
60 poliger Flachbandkabelanschluß
CN2 Interface-Adapter-Anschluß
1 NC (VCC f. Terminierung) GND 2
3 RAMWE GND 4
5 BOE GND 6
7 READ23 READ22 8
9 READ21 READ20 10
11 WRITE23 WRITE22 12
13 WRITE21 WRITE20 14
15 GND READ19 16
17 READ18 READ17 18
19 READ16 WRITE19 20
21 WRITE18 WRITE17 22
23 WRITE16 GND 24
25 READ15 READ14 26
27 READ13 READ12 28
29 WRITE15 WRITE14 30
31 WRITE13 WRITE12 32
33 GND READ11 34
35 READ10 READ9 36
37 READ8 WRITE11 38
39 WRITE10 WRITE9 40
41 WRITE8 GND 42
43 READ7 READ6 44
45 READ5 READ4 46
47 WRITE7 WRITE6 48
49 WRITE5 WRITE4 50
51 GND READ3 52
53 READ2 READ1 54
55 READ0 WRITE3 56
57 WRITE2 WRITE1 58
59 WRITE0 GND 60
Tabelle 7 Pinbelegung Ramcontroller CN2
75
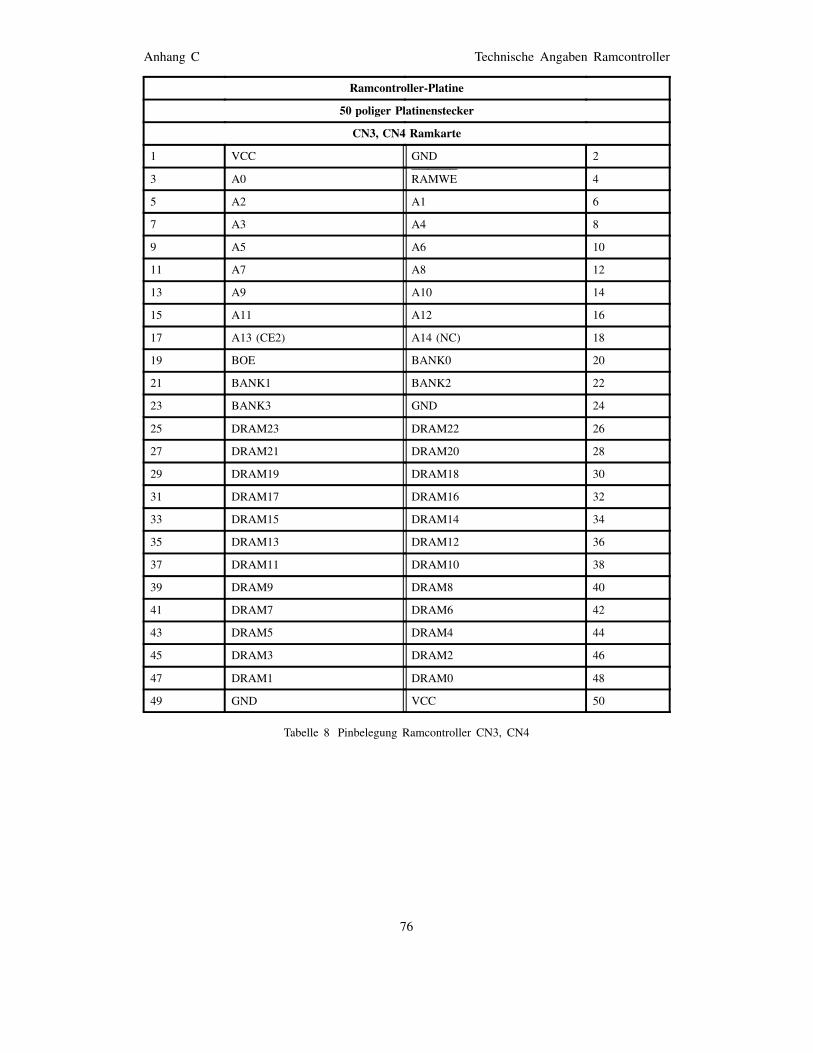
Anhang C Technische Angaben Ramcontroller
Ramcontroller-Platine
50 poliger Platinenstecker
CN3, CN4 Ramkarte
1 VCC GND 2
3 A0 RAMWE 4
5 A2 A1 6
7 A3 A4 8
9 A5 A6 10
11 A7 A8 12
13 A9 A10 14
15 A11 A12 16
17 A13 (CE2) A14 (NC) 18
19 BOE BANK0 20
21 BANK1 BANK2 22
23 BANK3 GND 24
25 DRAM23 DRAM22 26
27 DRAM21 DRAM20 28
29 DRAM19 DRAM18 30
31 DRAM17 DRAM16 32
33 DRAM15 DRAM14 34
35 DRAM13 DRAM12 36
37 DRAM11 DRAM10 38
39 DRAM9 DRAM8 40
41 DRAM7 DRAM6 42
43 DRAM5 DRAM4 44
45 DRAM3 DRAM2 46
47 DRAM1 DRAM0 48
49 GND VCC 50
Tabelle 8 Pinbelegung Ramcontroller CN3, CN4
76
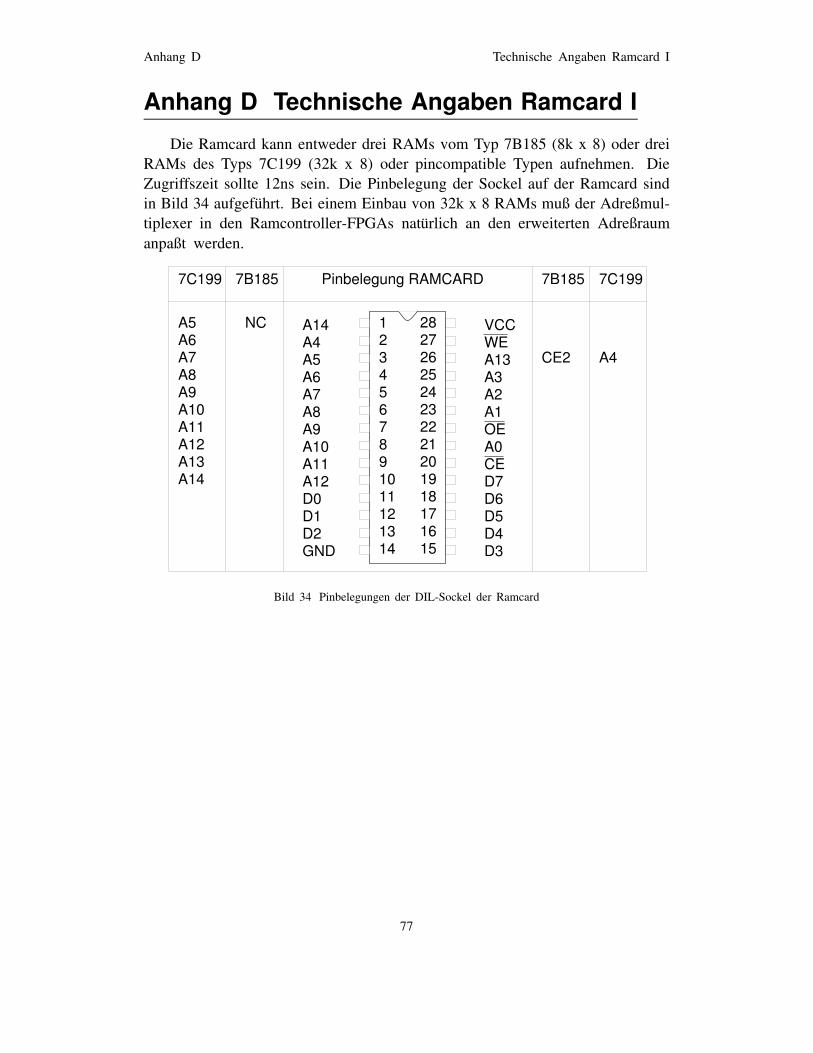
Anhang D Technische Angaben Ramcard I
Anhang D Technische Angaben Ramcard I
Die Ramcard kann entweder drei RAMs vom Typ 7B185 (8k x 8) oder drei
RAMs des Typs 7C199 (32k x 8) oder pincompatible Typen aufnehmen. Die
Zugriffszeit sollte 12ns sein. Die Pinbelegung der Sockel auf der Ramcard sind
in Bild 34 aufgefuhrt. Bei einem Einbau von 32k x 8 RAMs muß der Adreßmul-
tiplexer in den Ramcontroller-FPGAs naturlich an den erweiterten Adreßraum
anpaßt werden.
VCCWEA13A3A2A1OEA0CED7D6D5D4D3
A14A4A5A6A7A8A9A10A11A12D0D1D2GND
1234567891011121314
2827262524232221201918171615
NC
CE2
A5A6A7A8A9A10A11A12A13A14
A4
Pinbelegung RAMCARD 7B1857B185 7C1997C199
Bild 34 Pinbelegungen der DIL-Sockel der Ramcard
77
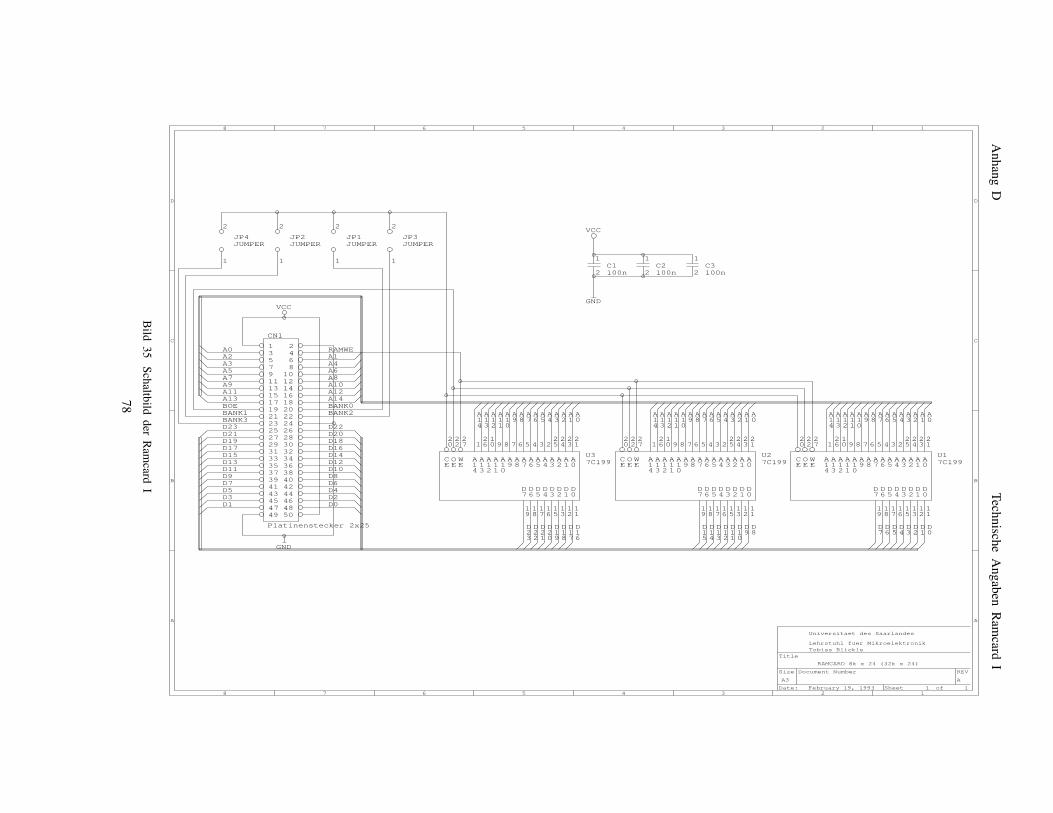
An
han
gD
Tech
nisch
eA
ng
aben
Ram
cardI
8 7 6 5 4 3 2 1
A
B
C
D
12345678
D
C
B
A
Date: February 19, 1993 Sheet 1 of 1
Size Document Number REV
A3 A
Title
RAMCARD 8k x 24 (32k x 24)
Tobias Blickle
Lehrstuhl fuer Mikroelektronik
Universitaet des Saarlandes
1
2
JP1JUMPER
1
2
JP3JUMPER
VCC
1
2
JP2JUMPER
1
2
JP4JUMPER
BOE
A0A2A3A5A7A9A11A13
1 23 45 67 89 1011 1213 1415 1617 1819 2021 2223 2425 2627 2829 3031 3233 3435 3637 3839 4041 4243 4445 4647 4849 50
CN1
Platinenstecker 2x25
BANK0
RAMWEA1A4A6A8A10A12A14
A0
A1
A2
A3
A4
A5
A6
A7
A8
A9
A10
A11
A12
A13
A0
A1
A2
A3
A4
A5
A6
A14
A0
21
A1
23
A2
24
A3
25
A4
2
A5
3
A6
4
A7
5
A8
6
A9
7
A10
8
A11
9
A12
10
A13
26
A14
1
WE
27
OE
22
CE
20
D0
11
D1
12
D2
13
D3
15
D4
16
D5
17
D6
18
D7
19
U17C199
A0
21
A1
23
A2
24
A3
25
A4
2
A5
3
A6
4
A7
5
A8
6
A9
7
A10
8
A11
9
A12
10
A13
26
A14
1
WE
27
OE
22
CE
20
D0
11
D1
12
D2
13
D3
15
D4
16
D5
17
D6
18
D7
19
U27C199
A0
A7
A8
A9
A10
A11
A12
A13
A14
A1
A2
A3
A4
A5
A6
A7
A8
A9
A10
A11
A12
A13
A14
BANK2
A0
21
A1
23
A2
24
A3
25
A4
2
A5
3
A6
4
A7
5
A8
6
A9
7
A10
8
A11
9
A12
10
A13
26
A14
1
WE
27
OE
22
CE
20
D0
11
D1
12
D2
13
D3
15
D4
16
D5
17
D6
18
D7
19
U37C199
D2D4D6D8D10D12D14D16D18D20D22
BANK1BANK3
D3D5D7D9D11D13D15D17D19D21D23
GND
D1 D0
D17
D18
D19
D20
D21
D22
D23
D15
D16
D8
D9
D10
D11
D12
D13
D14
D0
D1
D2
D3
D4
D5
D6
D7
VCC
GND
1
2C1100n
1
2C2100n
1
2C3100n
Bild
35
Sch
altbild
der
Ram
cardI
78

Anhang E Technische Angaben Program&Readback Buffer
Anhang E Technische AngabenProgram&Readback Buffer
Der Program&Readback-Bus (PRBUS) darf immer nur an hochstens ein
FPGA gleichzeig angeschlossen sein. Deshalb besitzt jedes FPGA einen Pro-
gram&Readback Treiber, der die entsprechenden Anschlusse des FPGAs erst dann
zum PRBUS durchschaltet, wenn ein Adressierungssignal (SELECT) dies erlaubt.
Im nicht selektierten Zustand sorgt ein Widerstandsnetzwerk fur den richtigen
logischen Pegel an den Eingangen des FPGAs.
Den Schaltplan zeigt Bild 36 . Das DONE-Signal wird nicht uber Treiber
geschaltet, sondern fuhrt direkt zu allen FPGAs, da dadurch ein synchrones Um-
schalten aller FPGAs vom Programmiermodus in den Ablaufmodus gewahrleistet
wird.
Zu Meß- und Testzwecken sind einige Signale auf den Meßstecker JM gefuhrt
(genauers siehe Meßsteckerbelegung in Anhang G).
Der Plan enthalt keine feste Nummerierung der Bauelement, da sie unter-
schliedlich fur Ramcontroller und Rechenfeld ausfallt, bzw. das Rechenfeld diese
Schaltung neun mal enthalt.
79

An
han
gE
Tech
nisch
eA
ng
aben
Pro
gram
&R
eadb
ackB
uffer
8 7 6 5 4 3 2 1
A
B
C
D
12345678
D
C
B
A
Date: February 19, 1993 Sheet of 1
Size Document Number REV
A4
Title
PRGRBK - Program & Readback Buffer
Tobias Blickle
Lehrstuhl fuer Mikroelektronik
Universitaet des Saarlandes
1 2 3 4 5 6 7 8 9
RN?8 x 4k7
Messpunkte
13579
2468
10
JM?
CON10A
i\n\i\t\out
GND
VCC
rclkincclkin
rtrigin
dininp\r\o\g\in
A1
2
A2
3
A3
4
A4
5
A5
6
A6
7
A7
8
A8
9
G
19
DIR
1
B1
18
B2
17
B3
16
B4
15
B5
14
B6
13
B7
12
B8
11
U?74F245
ripoutrdataout
GNDi\n\i\t\in
ripinrdatain
s\e\l\
D?LED
R?470
rtrigoutrclkoutcclkoutp\r\o\g\outdinout
VCC
Bild
36
Sch
altbild
des
Pro
gram
&R
eadback
Buffer
80

Anhang F Technische Angaben Interface-Adapter
Anhang F Technische AngabenInterface-Adapter
Der Interface-Adapter in Fadel-Technik realisiert. Das Layout der Platine
zeigt Bild 38. Die Belegung des Jumper-Blocks fur die Signalzuordung im
GPBUS ist in Bild 37 zu sehen. Die Schaltplane des Interface-Adapters sind
in Bild 39, 40, 41 und 42 gezeigt.
JP25
JP24
JP23
JP22
JP18
JP19
JP20
JP21
JP3
JP4
JP5
JP6
JP16
JP15
JP14
JP13
JP7
JP8
JP12
JP9
JP10
JP11
JP2
JP1
Bild 37 Lage der GPBUS Jumper im Jumperfeld
81

Anhang F Technische Angaben Interface-Adapter
CN
2 In
terf
ace
Writ
e C
ontr
olC
N1
Inte
rfac
e R
ead
Con
trol
CN
3 R
eche
nfel
d
CN
4 IF
BU
S h
oriz
onta
l
CN5 IFBUS vertikal
JM4
JM3
JM1
JM2
U3 U2
JumperfeldGPSWITCH
J1
U1
Bild 38 Layout der Interface-Adapter-Platine
82

Anhang F Technische Angaben Interface-Adapter
Bild 39 Schaltbild des Interface-Adapters
83

An
han
gF
Tech
nisch
eA
ng
aben
Interface-A
dap
ter
8 7 6 5 4 3 2 1
A
B
C
D
12345678
D
C
B
A
Date: February 19, 1993 Sheet 2 of 4
Size Document Number REV
A4 A
Title
IFADAPMP - Messpunkte am Interface-Adapter
Tobias Blickle
Lehrstuhl fuer Mikroelektronik
Universitaet des Saarlandes
VCC
PR1PR2
PR3PR8
CCLKDONEDINPROG
XCHECKER
123456789
JM1
CON9
VCC
1 23 45 67 89 1011 1213 1415 1617 1819 2021 2223 2425 26
JM4
HEADER 13X2
CLKaCLKbIFCLKREAD1_CLKcCLKd
CLKBUS6CLKBUS7CLKBUS8CLKBUS9CLKBUS10CLKBUS11
CLKBUS[0..11]CLKBUS[0..11]
GND
PR0 INITGSR
PR[0..8]
GSR
PR[0..8]
RTRIGRDATA
PR7PR6
PR4PR5
123456789
JM2
CON9
CLKBUS0CLKBUS1CLKBUS2CLKBUS3CLKBUS4CLKBUS5
ComCLK_1ComCLK_2BOE_hBOE_vRAMWE_hRAMWE_v
GND
FADR712345678910
JM3
CON10
FADR0FADR1FADR2FADR3FADR4FADR5FADR6
FADR[0..7]FADR[0..7]
GND
Bild
40
Meß
punkte
des
Interface-A
dap
ters
84
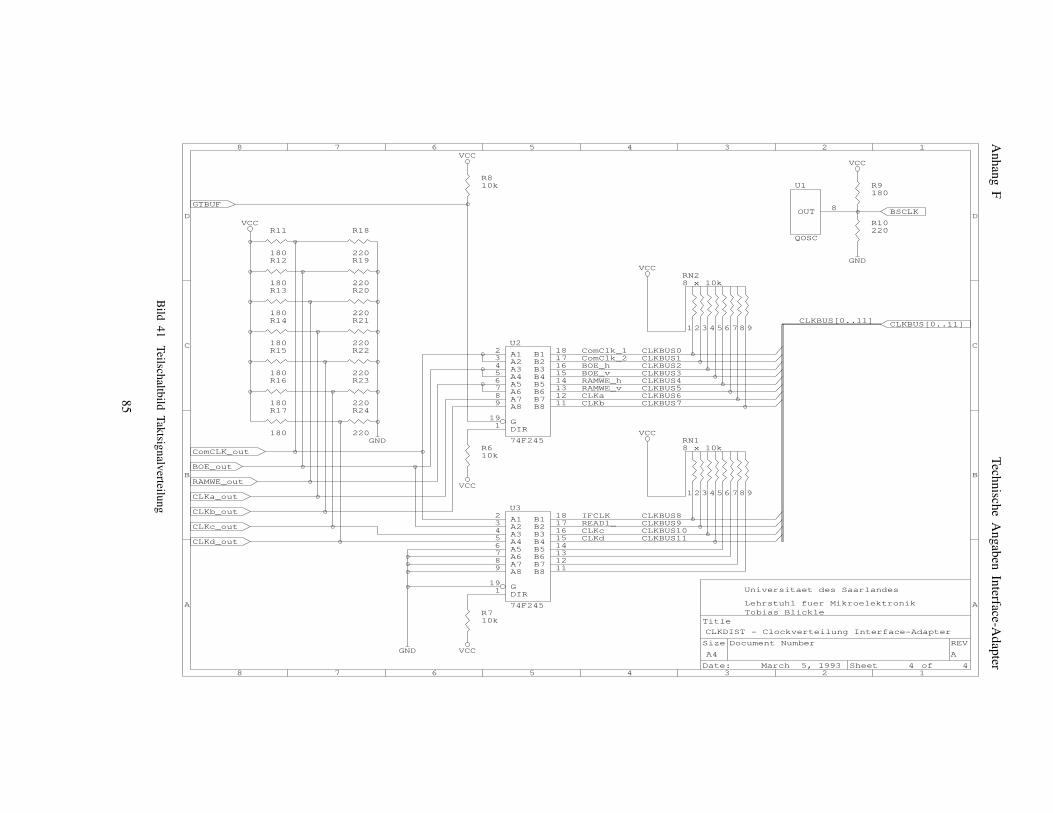
An
han
gF
Tech
nisch
eA
ng
aben
Interface-A
dap
ter
8 7 6 5 4 3 2 1
A
B
C
D
12345678
D
C
B
A
Date: March 5, 1993 Sheet 4 of 4
Size Document Number REV
A4 A
Title
CLKDIST - Clockverteilung Interface-Adapter
Tobias Blickle
Lehrstuhl fuer Mikroelektronik
Universitaet des Saarlandes
BSCLKOUT 8
U1
QOSC
VCC
R9180
VCC
R810k
GTBUF
VCCR11
180R12
180
R18
220R19
220
VCCGND
R10220
CLKBUS[0..11]CLKBUS[0..11]
1 2 3 4 5 6 7 8 9
RN28 x 10k
R20
220R21
220
R13
180R14
180R15
180R16
180
R22
220R23
220
A1 2
A2 3
A3 4
A4 5
A5 6
A6 7
A7 8
A8 9
G 19
DIR 1
B118
B217
B316
B415
B514
B613
B712
B811
U2
74F245
ComClk_1ComClk_2
CLKaCLKb
CLKBUS0CLKBUS1CLKBUS2CLKBUS3CLKBUS4CLKBUS5CLKBUS6CLKBUS7
BOE_hBOE_vRAMWE_hRAMWE_v
1 2 3 4 5 6 7 8 9
RN18 x 10k
VCC
R610k
GND
R24
220
ComCLK_out
BOE_out
R17
180
CLKa_out
CLKb_out
CLKc_out
RAMWE_outVCC
A1 2
A2 3
A3 4
A4 5
A5 6
A6 7
A7 8
A8 9
G 19
DIR 1
B118
B217
B316
B415
B514
B613
B712
B811
U3
74F245
IFCLK CLKBUS8CLKBUS9
CLKc CLKBUS10READ1_
CLKd CLKBUS11CLKd_out
VCC
R710k
GND
Bild
41
Teilsch
altbild
Tak
tsignalv
erteilung
85
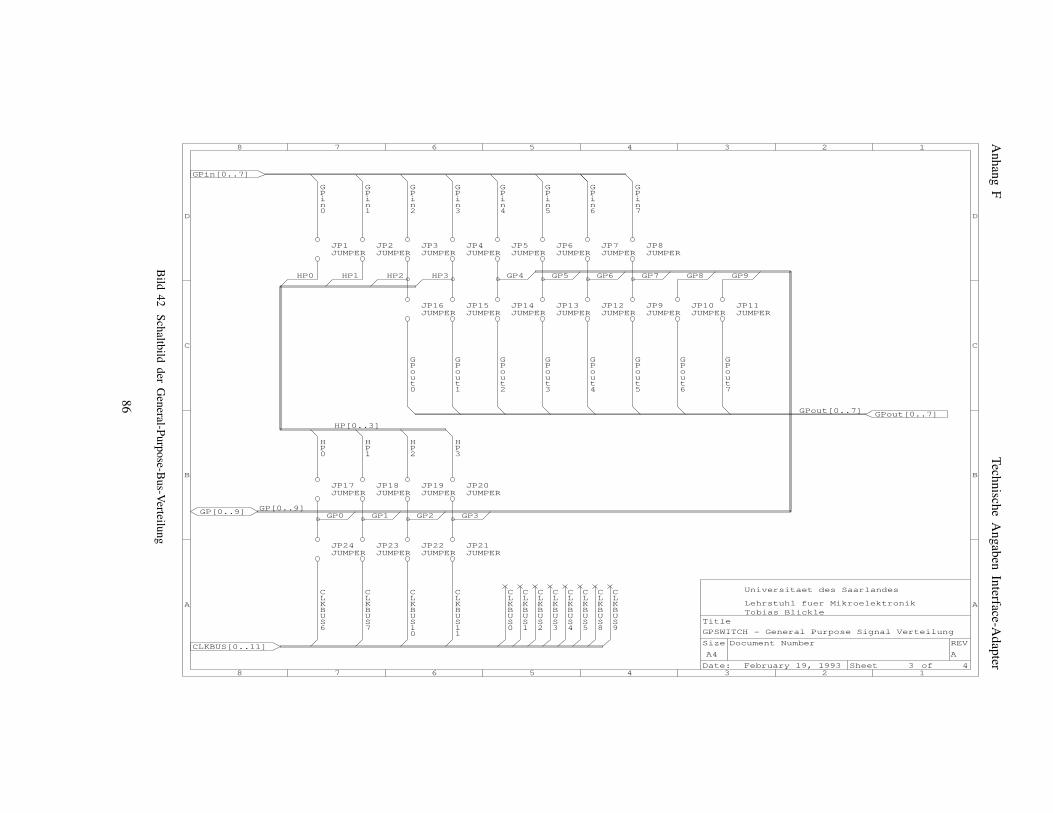
An
han
gF
Tech
nisch
eA
ng
aben
Interface-A
dap
ter
8 7 6 5 4 3 2 1
A
B
C
D
12345678
D
C
B
A
Date: February 19, 1993 Sheet 3 of 4
Size Document Number REV
A4 A
Title
GPSWITCH - General Purpose Signal Verteilung
Tobias Blickle
Lehrstuhl fuer Mikroelektronik
Universitaet des Saarlandes
GPin6
GPin7
GPin4
GPin5
GPin2
GPin3
GPin0
GPin1
GPin[0..7]
JP1JUMPER
JP2JUMPER
HP0 HP1
JP3JUMPER
JP4JUMPER
HP2 HP3
JP5JUMPER
JP6JUMPER
GP4 GP5
JP7JUMPER
JP8JUMPER
GP6 GP7 GP8 GP9
JP11JUMPER
JP9JUMPER
JP10JUMPER
JP12JUMPER
JP13JUMPER
JP14JUMPER
JP15JUMPER
JP16JUMPER
GPout0
GPout1
GPout2
GPout3
GPout4
GPout5
GPout6
GPout7
GPout[0..7]GPout[0..7]
HP2
HP3
HP0
HP1
HP[0..3]
GP[0..9]GP[0..9]
JP17JUMPER
JP18JUMPER
GP0 GP1
JP19JUMPER
JP20JUMPER
GP2 GP3
CLKBUS5
CLKBUS8
CLKBUS9
CLKBUS0
CLKBUS1
CLKBUS2
CLKBUS3
CLKBUS4
JP21JUMPER
JP22JUMPER
CLKBUS10
CLKBUS11
JP23JUMPER
JP24JUMPER
CLKBUS6
CLKBUS7
CLKBUS[0..11]
Bild
42
Sch
altbild
der
Gen
eral-Purp
ose-B
us-V
erteilung
86
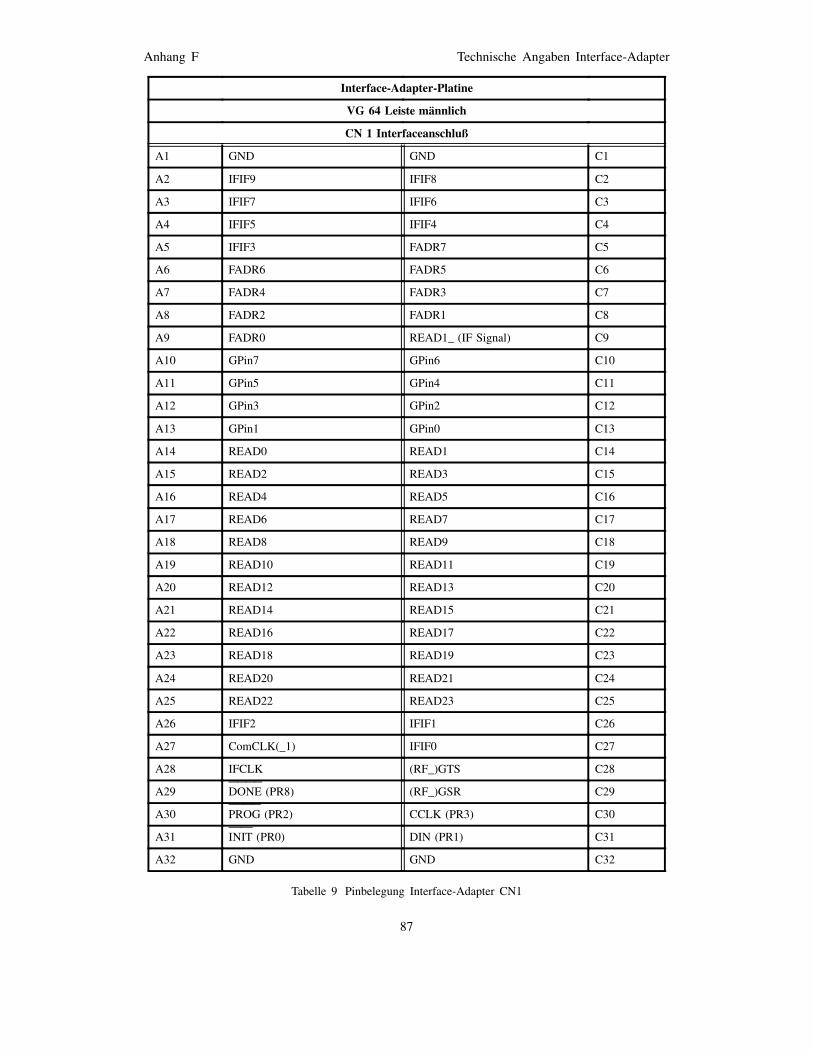
Anhang F Technische Angaben Interface-Adapter
Interface-Adapter-Platine
VG 64 Leiste mannlich
CN 1 Interfaceanschluß
A1 GND GND C1
A2 IFIF9 IFIF8 C2
A3 IFIF7 IFIF6 C3
A4 IFIF5 IFIF4 C4
A5 IFIF3 FADR7 C5
A6 FADR6 FADR5 C6
A7 FADR4 FADR3 C7
A8 FADR2 FADR1 C8
A9 FADR0 READ1_ (IF Signal) C9
A10 GPin7 GPin6 C10
A11 GPin5 GPin4 C11
A12 GPin3 GPin2 C12
A13 GPin1 GPin0 C13
A14 READ0 READ1 C14
A15 READ2 READ3 C15
A16 READ4 READ5 C16
A17 READ6 READ7 C17
A18 READ8 READ9 C18
A19 READ10 READ11 C19
A20 READ12 READ13 C20
A21 READ14 READ15 C21
A22 READ16 READ17 C22
A23 READ18 READ19 C23
A24 READ20 READ21 C24
A25 READ22 READ23 C25
A26 IFIF2 IFIF1 C26
A27 ComCLK(_1) IFIF0 C27
A28 IFCLK (RF_)GTS C28
A29 DONE (PR8) (RF_)GSR C29
A30 PROG (PR2) CCLK (PR3) C30
A31 INIT (PR0) DIN (PR1) C31
A32 GND GND C32
Tabelle 9 Pinbelegung Interface-Adapter CN1
87
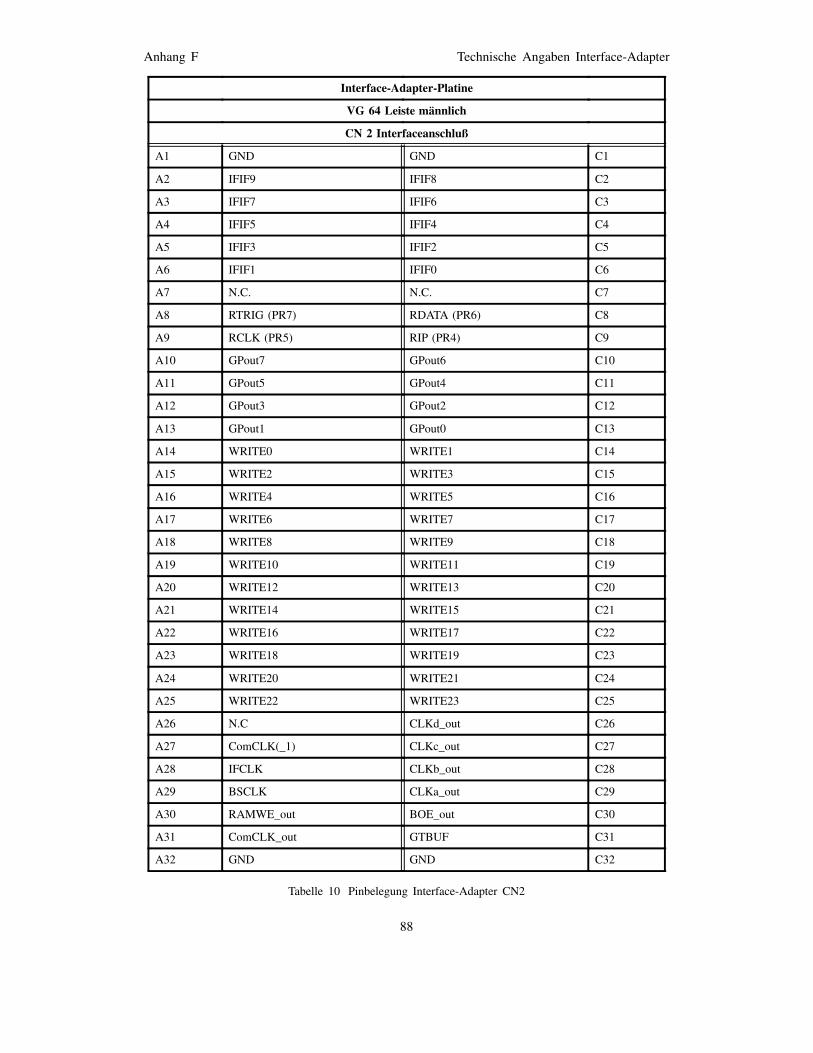
Anhang F Technische Angaben Interface-Adapter
Interface-Adapter-Platine
VG 64 Leiste mannlich
CN 2 Interfaceanschluß
A1 GND GND C1
A2 IFIF9 IFIF8 C2
A3 IFIF7 IFIF6 C3
A4 IFIF5 IFIF4 C4
A5 IFIF3 IFIF2 C5
A6 IFIF1 IFIF0 C6
A7 N.C. N.C. C7
A8 RTRIG (PR7) RDATA (PR6) C8
A9 RCLK (PR5) RIP (PR4) C9
A10 GPout7 GPout6 C10
A11 GPout5 GPout4 C11
A12 GPout3 GPout2 C12
A13 GPout1 GPout0 C13
A14 WRITE0 WRITE1 C14
A15 WRITE2 WRITE3 C15
A16 WRITE4 WRITE5 C16
A17 WRITE6 WRITE7 C17
A18 WRITE8 WRITE9 C18
A19 WRITE10 WRITE11 C19
A20 WRITE12 WRITE13 C20
A21 WRITE14 WRITE15 C21
A22 WRITE16 WRITE17 C22
A23 WRITE18 WRITE19 C23
A24 WRITE20 WRITE21 C24
A25 WRITE22 WRITE23 C25
A26 N.C CLKd_out C26
A27 ComCLK(_1) CLKc_out C27
A28 IFCLK CLKb_out C28
A29 BSCLK CLKa_out C29
A30 RAMWE_out BOE_out C30
A31 ComCLK_out GTBUF C31
A32 GND GND C32
Tabelle 10 Pinbelegung Interface-Adapter CN2
88

Anhang F Technische Angaben Interface-Adapter
Interface-Adapter-Platine
40pol Flachbandkabelanschluß
CN3 Rechenfeld-Anschluß
Belegung wie CN1 Rechenfeld (Tabelle 4)
Tabelle 11 Pinbelegung Interface-Adapter CN3
Interface-Adapter-Platine
60pol Flachbandkabelanschluß
CN4 Ramcontroller-Anschluß (IFBUS horizontal)
Belegung wie CN2 Ramcontroller (Tabelle 7)
Tabelle 12 Pinbelegung Interface-Adapter CN4
Interface-Adapter-Platine
60pol Flachbandkabelanschluß
CN5 Ramcontroller-Anschluß (IFBUS vertikal)
Belegung wie CN2 Ramcontroller (Tabelle 7)
Tabelle 13 Pinbelegung Interface-Adapter CN5
89
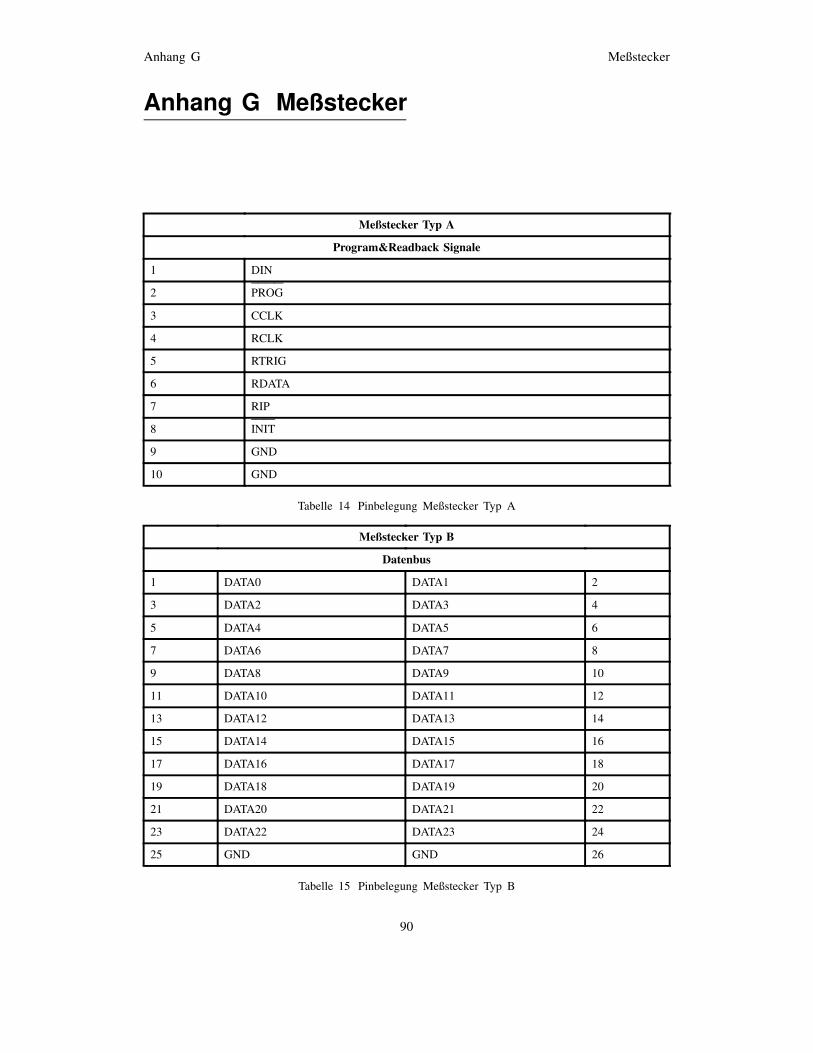
Anhang G Meßstecker
Anhang G Meßstecker
Meßstecker Typ A
Program&Readback Signale
1 DIN
2 PROG
3 CCLK
4 RCLK
5 RTRIG
6 RDATA
7 RIP
8 INIT
9 GND
10 GND
Tabelle 14 Pinbelegung Meßstecker Typ A
Meßstecker Typ B
Datenbus
1 DATA0 DATA1 2
3 DATA2 DATA3 4
5 DATA4 DATA5 6
7 DATA6 DATA7 8
9 DATA8 DATA9 10
11 DATA10 DATA11 12
13 DATA12 DATA13 14
15 DATA14 DATA15 16
17 DATA16 DATA17 18
19 DATA18 DATA19 20
21 DATA20 DATA21 22
23 DATA22 DATA23 24
25 GND GND 26
Tabelle 15 Pinbelegung Meßstecker Typ B
90