maskiertes semantisches priming - e-thesesothes.univie.ac.at/33909/1/2014-08-19_0808167.pdf · v...
TRANSCRIPT

Diplomarbeit
Titel der Diplomarbeit
Subliminales syntaktisches Priming:
Einfluss von maskierten Pronomen auf die Erkennung
von sichtbaren Verben in lexikalischen
Entscheidungsaufgaben
Verfasserin
Reyhan Vurgun
Angestrebter akademischer Grad
Magistra der Naturwissenschaften (Mag. rer. nat.)
Wien, 2014
Studienkennzahl: 298
Studienrichtung: Psychologie
Betreuer: Prof. Dr. Ulrich Ansorge

II

III
Danksagung
An dieser Stelle möchte ich denjenigen Personen danken, die mich während der Erstellung
meiner Diplomarbeit unterstützt und motiviert haben.
Ganz besonders danke ich meinem Betreuer Prof. Dr. Ulrich Ansorge für dessen
umfangreiche Unterstützung. Seine schnellen und ausführlichen Rückmeldungen und die
konstruktive Kritik waren bei der Anfertigung dieser Arbeit eine sehr große Hilfe. Vielen
Dank für die Zeit und Mühe.
Außerdem möchte ich mich bei Vladan bedanken, der viel Zeit für das Korrekturlesen dieser
Arbeit investiert hat.
Des Weiteren möchte ich meinen Geschwistern Elvan, Mustafa und Beyhan danken, die mich
stets unterstützt haben und in stressigen Zeiten immer für mich da waren.
Insbesondere danke ich meinen Eltern, ohne die das Studium kaum möglich gewesen wäre.
Ich danke euch für eure persönliche und emotionale Unterstützung während dieser gesamten
Zeit.

IV

V
Zusammenfassung
In dieser Studie wurde subliminales syntaktisches Priming untersucht. Es wurde der Einfluss
von maskierten Pronomen als Bahnungsreize auf die Erkennung von sichtbaren Verben im
Vergleich zu sichtbaren Substantiven als Zielreize erforscht. Das Ziel war es, herauszufinden,
ob Verben im Vergleich zu Substantiven in lexikalischen Entscheidungsaufgaben schneller
und fehlerfreier erkannt werden, wenn ihnen subliminal wahrnehmbare Pronomen als
Bahnungsreize vorausgingen. Die syntaktisch kongruenten Bedingungen waren jene, in denen
die Pronomen den Verben vorausgingen und die syntaktisch inkongruenten Bedingungen
jene, in denen die Pronomen den Substantiven vorausgingen. Neben der syntaktischen
Kongruenz wurde auch die morphosyntaktische Kongruenz untersucht. Es wurde überprüft,
ob Verben im Vergleich zu Substantiven auch schneller und fehlerfreier erkannt werden,
wenn ihnen subliminal wahrnehmbare Pronomen vorausgingen, die nicht der Wortbeugung
dieser Verben entsprachen (morphosyntaktisch inkongruent). Um die Wirkung der Pronomen
als Bahnungsreize eruieren zu können, wurden Pseudo-Pronomen kreiert und ebenso wie die
Pronomen als Bahnungsreize eingesetzt. Da für die lexikalische Entscheidungsaufgabe
Pseudo-Wörter benötigt wurden, wurden Pseudo-Verben aus den Verben und Pseudo-
Substantive aus den Substantiven abgeleitet. 35 Versuchspersonen nahmen an der
Untersuchung teil und mussten in den lexikalische Entscheidungsaufgaben bestimmen, ob es
sich bei den präsentierten Zielreizen um Wörter oder Pseudo-Wörter handelte. Bei der
Analyse der Ergebnisse wurden sowohl die Daten der Wörter als auch die Daten der Pseudo-
Wörter berücksichtigt. Es konnten keine syntaktischen oder morphosyntaktischen
Kongruenzeffekte nachgewiesen werden. Verben als Zielreize, denen Pronomen als
Bahnungsreize vorausgingen, wurden im Vergleich zu Substantiven als Zielreize, denen
Pronomen als Bahnungsreize vorausgingen, nicht signifikant schneller und/oder mit
signifikant weniger Fehlern erkannt. Ein Haupteffekt zeigte signifikante Reaktionszeitvorteile
für die Erkennung von Wörtern im Vergleich zu Pseudo-Wörtern. Eine Tendenz in Richtung
Signifikanz zeigte die Interaktion, in der Pseudo-Wörter schneller erkannt wurden, wenn
ihnen Pseudo-Pronomen vorausgingen als wenn ihnen Pronomen vorausgingen. Diese
Tendenz war ein Anzeichen für einen möglichen Reaktionsbahnungseffekt. Die Ergebnisse
wurden mit dem Hauptaugenmerk auf Designmaßnahmen, die Aufgabenstellung und einen
möglichen Reaktionsbahnungseffekt detailliert in der Diskussion erörtert und interpretiert.

VI
Abstract
In this study the principles of subliminal syntactic priming were investigated by testing
whether masked pronouns as primes had an influence on lexical decisions regarding visible
verbs as targets compared to visible nouns as targets. The aim of this study was to examine if
lexical decisions to verbs as targets compared to nouns as targets were faster and more
accurate, when they were preceded by subliminally presented pronouns as primes. Thus,
syntactic congruent conditions were those, where verbs were preceded by pronouns and
syntactic incongruent conditions were those, where nouns were preceded by pronouns. In
addition to syntactic congruence effects, morphosyntactic congruence effects were examined.
It was tested whether lexical decisions to verbs were faster and more accurate compared to
nouns if the preceded pronouns did not match the flexion of these verbs (morphosyntactic
incongruent). To examine the effect the pronouns had on the target verbs, pseudo-pronouns
were created and were also used as primes. For the lexical decision task pseudo-verbs were
created by using verbs as templates and pseudo-nouns were created by using nouns as
templates. In the lexical decision task 35 participants had to decide whether the presented
targets were words or pseudo-words. The analysis of the results included both the data
extracted from the words and the data extracted from the pseudo-words. No significant
syntactic or morphosyntactic congruence effects were found. Lexical decisions to verbs
preceded by pronouns were not significantly faster and/or significantly more accurate than
lexical decisions to nouns preceded by pronouns. A main effect for reaction time revealed
significantly faster reactions for words compared to pseudo-words. An interaction revealed a
tendency towards significance by showing that reaction times to pseudo-words were faster
when they were preceded by pseudo-pronouns than when they were preceded by pronouns.
This tendency possibly was due to a response priming effect. The results were discussed with
the focus on the design of this study, the task used in this study and a possible response
priming effect.

VII
Inhaltsverzeichnis
Danksagung ......................................................................................................................... III
Zusammenfassung ................................................................................................................ V
Abstract ................................................................................................................................ VI
Inhaltsverzeichnis ............................................................................................................... VII
Abbildungsverzeichnis ..................................................................................................... VIII
1. Theoretischer Hintergrund ........................................................................................... 1
1.01 Einleitung ............................................................................................................. 1
1.02 Priming: Definition .............................................................................................. 1
1.03 Semantisches Priming: Definition und Erläuterung ............................................. 2
1.04 Syntaktisches Priming: Definition und Erläuterung ............................................. 2
1.05 Ereigniskorrelierte Potentiale als Messemethode ................................................ 3
1.06 Erste Studien zu semantischem Priming .............................................................. 4
1.07 Unbewusste Wahrnehmung durch Maskierungstechniken .................................. 5
1.08 Forschung zu supraliminalem syntaktischen Priming .......................................... 6
1.09 Forschung zu subliminalem syntaktischen Priming ............................................. 8
1.10 Gegenstand und Ziele der vorliegenden Untersuchung ..................................... 10
2. Methode ..................................................................................................................... 12
2.01 Untersuchungsteilnehmer ................................................................................... 12
2.02 Instrumente und Messgeräte ............................................................................... 13
2.03 Reizmaterial ....................................................................................................... 13
2.04 Untersuchungsdesign ......................................................................................... 15
2.05 Untersuchungsdurchführung .............................................................................. 17
3. Ergebnisse .................................................................................................................. 20
3.01 Analyse der Reaktionszeiten .............................................................................. 20
3.02 Analyse der Fehlerraten ..................................................................................... 27
3.03. Primesichtbarkeitsaufgabe.................................................................................. 34
4. Diskussion ................................................................................................................. 35
5. Literatur ..................................................................................................................... 49
Appendix A.......................................................................................................................... 53
Verben im Singular und Plural ....................................................................................... 53
Appendix B .......................................................................................................................... 56
Pseudo-Verben im Singular ............................................................................................ 56
Pseudo-Verben im Plural ................................................................................................ 57
Appendix C .......................................................................................................................... 58
Substantive im Singular .................................................................................................. 58
Substantive im Plural ...................................................................................................... 59

VIII
Appendix D.......................................................................................................................... 60
Pseudo-Substantive im Singular ..................................................................................... 60
Pseudo-Substantive im Plural ......................................................................................... 61
Curriculum Vitae ................................................................................................................. 62
Abbildungsverzeichnis
Abbildung 1 Schematische Darstellung eines maskierten syntaktisch kongruenten
Primingdurchgangs ................................................................................................................... 16
Abbildung 2 Schematische Darstellung eines maskierten syntaktisch inkongruenten
Primingdurchgangs ................................................................................................................... 16
Abbildung 3 Schematische Darstellung der Tastenbelegung des Nummernblocks im
Experiment ............................................................................................................................... 19
Abbildung 4 Durchschnittliche Reaktionszeiten (in ms) des signifikanten Haupteffekts der
Variable Zielreizwort ............................................................................................................... 20
Abbildung 5 Durchschnittliche Reaktionszeiten (in ms) des signifikanten Haupteffekts der
Variable Zielwortklasse ............................................................................................................ 21
Abbildung 6 Durchschnittliche Reaktionszeiten (in ms) des signifikanten Haupteffekts der
Variable grammatikalische Numeri ......................................................................................... 22
Abbildung 7 Durchschnittliche Reaktionszeiten (in ms) der signifikanten Interaktion
zwischen Zielreizwort und Primereiz ....................................................................................... 23
Abbildung 8 Durchschnittliche Reaktionszeiten (in ms) der signifikanten Interaktion
zwischen Zielreizwort und grammatikalischer Numeri ........................................................... 24
Abbildung 9 Durchschnittliche Reaktionszeiten (in ms) der signifikanten Interaktion
zwischen Zielwortklasse und grammatikalischer Numeri........................................................ 25
Abbildung 10 Durchschnittliche Reaktionszeiten (in ms) der signifikanten Interaktion
zwischen Zielreizwort, Zielwortklasse und grammatikalischer Numeri .................................. 26
Abbildung 11 Durchschnittliche Fehlerraten (in %) des signifikanten Haupteffektes der
Variable Zielwortklasse ............................................................................................................ 27
Abbildung 12 Durchschnittliche Fehlerraten (in %) des signifikanten Haupteffektes der
Variable grammatikalische Numeri ......................................................................................... 28
Abbildung 13 Durchschnittliche Fehlerraten (in %) der signifikanten Interaktion zwischen
den Variablen Zielreizwort und morphosyntaktische Kongruenz ............................................ 29

IX
Abbildung 14 Durchschnittliche Fehlerraten (in %) der signifikanten Interaktion zwischen
den Variablen Zielreizwort und Zielwortklasse ....................................................................... 30
Abbildung 15 Durchschnittliche Fehlerraten (in %) der signifikanten Interaktion zwischen
den Variablen Zielreizwort und grammatikalische Numeri ..................................................... 31
Abbildung 16 Durchschnittliche Fehlerraten (in %) der signifikanten Interaktion zwischen
den Variablen Zielwortklasse und grammatikalische Numeri ................................................. 32
Abbildung 17 Durchschnittliche Fehlerraten (in %) der signifikanten Interaktion zwischen
den Variablen Zielreizwort, Zielwortklasse und grammatikalische Numeri ........................... 33

SUBLIMINALES SYNTAKTISCHES PRIMING 1
1. Theoretischer Hintergrund
1.01 Einleitung
Das Sprach- und Leseverständnis ist ein wesentlicher Bestandteil unseres Alltags. Für
das Verständnis von Sprache spielen Rechtschreibung, angelernte grammatikalische Regeln
und die Konstellation der entsprechenden, inhaltlich verwandten und aufeinander
abgestimmten Wörter eine wichtige Rolle. Werden diese Regeln verletzt, springt uns dies
meist sofort ins Auge. Beispielsweise fallen uns grammatikalisch inkorrekte Sätze auf
Hinweisschildern im Ausland wie „Tür öffnen nicht“ oder „Ich bin Haus“ sofort auf, da sie
gegen die uns bekannten grammatikalischen Regeln verstoßen. Ebenso fällt es uns sofort auf,
wenn es inhaltliche Unstimmigkeiten in einem Satz gibt. Ein Beispiel hierfür wäre der Fall,
wenn wir auf ein unerwartetes Wort in einem Satz stoßen. Der Satz „Er trank von einem
Wasserfall“ (engl. „He took a sip from the waterfall“) wäre sowohl inhaltlich abgestimmt als
auch grammatikalisch korrekt während der Satz „Er trank von einem Sender“ (engl. „He took
a sip from the transmitter“) zwar grammatikalisch korrekt, aber inhaltlich nicht abgestimmt
und somit falsch wäre (vgl. Kutas & Hillyard, 1980).
Bei der Verarbeitung von Sprache spielen somit semantische und syntaktische
Prozesse eine Rolle. Die Semantik befasst sich mit der Bedeutung von Wörtern während die
Syntax die korrekte grammatikalische Anordnung von Wörtern in Sätzen beschreibt
(„Cambridge Dictionaries Online“, 2014). Die Syntax setzt sich aus zwei Faktoren
zusammen, nämlich der Wortreihenfolge und der Wortflexion (Konjugation und Deklination)
(Ansorge & Becker, in Vorbereitung).
Wenn wir einen Satz lesen, erwarten wir gewisse Abfolgen und Konstellationen von
Wörtern, die diesen Regeln entsprechen. Beispielsweise erwarten wir nach dem Pronomen
„ich“ ein Verb wie „gehe“ und kein Substantiv wie „Haus“. Die Einhaltung dieser Regeln
spielt beim Sprach- und Leseverständnis eine wesentliche Rolle (vgl. Friederici, 2002).
Um zu überprüfen, ob und wie stark die Rollen der Semantik und der Syntax
tatsächlich im Sprachverständnis sind, kann man auf semantische und syntaktische
Primingexperimente zurückgreifen.
1.02 Priming: Definition
Generell wird beim Priming (dt. „Bahnung“) die Beeinflussung der Verarbeitung von
Nachfolgendem aufgrund der Repräsentation von etwas in der Vergangenheit liegendem
untersucht. Wenn ein Bahnungsreiz (engl. „Prime“) einem Zielreiz (engl. „Target“)

SUBLIMINALES SYNTAKTISCHES PRIMING 2
vorausgeht, wird die Verarbeitung des besagten Zielreizes in Abhängigkeit vom Grad der
Assoziation zwischen Bahnungs- und Zielreiz erleichtert oder erschwert (Neely, 1977). Es
gibt verschiedene Formen von Priming. Im Folgenden werden semantisches und syntaktisches
Priming näher erläutert.
1.03 Semantisches Priming: Definition und Erläuterung
Im Rahmen des semantischen Priming tritt ein erleichternder Effekt auf, wenn einem
Target ein inhaltlich verwandter Prime vorausgeht (Kiefer, 2002). Dieser erleichternde Effekt
kann beispielsweise mit Hilfe von lexikalischen Entscheidungsaufgaben untersucht werden
(Neely, 1976; Kiefer, 2002). In lexikalischen Entscheidungsaufgaben haben die
Versuchspersonen die Aufgabe so schnell und so genau wie möglich zu entscheiden, ob es
sich bei einem präsentierten Target um ein echtes Wort oder ein sogenanntes Pseudo-Wort
handelt (Neely, 1976). Pseudo-Wörter sind keine echten Wörter, verfügen jedoch über eine
wortähnliche Form und sind aussprechbar (Balota & Chumbley, 1984). Durch behaviorale
Messmethoden kann die Reaktionszeit und die Fehlerrate der lexikalischen Entscheidungen
gemessen werden (vgl. Kiefer, 2002; Kiefer & Brendel 2006). Die Reaktionen erfolgen
schneller und mit weniger Fehlern, wenn einem Target (z.B. „Zitrone“, engl. „lemon“) ein
inhaltlich verwandter Prime (z.B. „sauer“, engl. „sour“) vorausgeht, als wenn diesem ein
inhaltlich nicht verwandter Prime (z.B. „Haus“, engl. „house“) vorausgeht. Dies wird als
semantischer Priming Effekt bezeichnet (Kiefer, 2002). Die Bedingungen, in denen der Prime
und das Target inhaltlich verwandt sind, werden als semantisch kongruent bezeichnet,
während die Bedingungen, in denen der Prime und das Target nicht inhaltlich verwandt sind,
als semantisch inkongruent bezeichnet werden (Ansorge, Kiefer, Khalid, Grassl & König,
2010; vgl. Kiefer, 2002).
1.04 Syntaktisches Priming: Definition und Erläuterung
Im Rahmen des syntaktischen Primings wird ein Wort als Prime gewählt, welches die
syntaktische Wortklasse (z.B. Substantiv oder Verb) des folgenden Wortes voraussagbar
macht, aber nichts über dessen Bedeutung verrät (Goodman, McClelland & Gibbs, 1981).
Beispielsweise wird bei der Darbietung des Primes „ich“ ein Verb als Target erwartet, aber es
ist nicht vorhersehbar, welches Verb folgen wird. Die erwartete Zielwortklasse ist somit
eindeutig, aber die Bedeutung des Zielwortes nicht. Wenn ein Prime und ein Target nach den
Regeln der Satzlehre kombiniert werden, wird dies als syntaktisch kongruent und anderenfalls
als syntaktisch inkongruent bezeichnet. Ein syntaktisch kongruenter Fall wäre zum Beispiel
„ich gehe“, während ein syntaktisch inkongruenter Fall beispielsweise „ich Haus“ sein

SUBLIMINALES SYNTAKTISCHES PRIMING 3
könnte. Die syntaktische Inkongruenz entsteht in diesem Fall dadurch, dass einem Pronomen
ein Substantiv folgt und nicht, wie den Regeln der Syntax entsprechend, ein Verb. Wie
semantisches Priming kann auch syntaktisches Priming beispielsweise mit Hilfe von
lexikalischen Entscheidungsaufgaben untersucht werden (vgl. Goodman et al. 1981; Sereno,
1991). Hierbei müssen Versuchspersonen entscheiden, ob es sich bei einem Target (z.B.
„Haus“, engl. „house“) um ein echtes Wort oder ein Pseudo-Wort handelt. Die lexikalischen
Entscheidungen erfolgen schneller und genauer, wenn dem Target ein syntaktisch kongruenter
Prime (z.B. „das“, engl. „the“) vorausgeht als wenn diesem ein syntaktisch inkongruenter
Prime (z.B. „wir“, engl. „we“) vorausgeht (vgl. Goodman et al., 1981). Dieser Effekt wird
als syntaktischer Priming Effekt bezeichnet (Goodman et al. 1981; Sereno, 1991).
Überdies wird auch die dem Prime entsprechende Wortbeugung des Targets erwartet.
Wenn beispielsweise das Pronomen in der ersten Person Singular präsentiert wird, würde man
ebenfalls ein Verb in der ersten Person Singular, wie zum Beispiel. „ich gehe“, erwarten.
Würde ein Verb in einer anderen grammatikalischen Abwandlung, wie zum Beispiel „ich
gehen“ (1. Person Plural), folgen, wäre dies morphosyntaktisch inkongruent.
Morphosyntaktische Inkongruenz entsteht beispielsweise, wenn die Wortreihenfolge korrekt,
aber die Wortbeugung inkorrekt ist. Morphosyntaktische Kongruenz hängt somit von der
korrekten Flexion der Wörter in einem Satz ab (vgl. Ansorge, Reynvoet, Hendler, Oettl &
Evert, 2013). Eine Voraussetzung für die syntaktische Kongruenz ist somit neben der
korrekten Reihenfolge der Wörter auch die entsprechend korrekte Flexion dieser Wörter (vgl.
Cole & Segui, 1994; Nicol, 1996).
1.05 Ereigniskorrelierte Potentiale als Messemethode
Neben den bereits erwähnten behavioralen Messmethoden der Reaktionszeit- und
Fehlerratenmessung können ebenso mit Hilfe von ereigniskorrelierten Potentialen (EKP)
sowohl semantische Verarbeitungsprozesse (vgl. Kiefer & Brendel, 2006; Kiefer & Martens,
2010) als auch syntaktische Verarbeitungsprozesse (vgl. Guajardo & Wicha, 2014; Hinojosa
et al., 2014; Tanner & Van Hell, 2014) gemessen werden. EKP werden mittels
Elektroenzephalographie (EEG) gemessen und spiegeln die Gehirnaktivität wider. Hierdurch
kann man unter anderem die Eigenschaften und den Zeitverlauf von
Sprachverarbeitungsprozessen messen und beurteilen (Tanner & Van Hell, 2014). Bestimmte
EKP wurden in früheren Studien zu spezifischen linguistischen Prozessen bereits mit
bestimmten positiven oder negativen Amplituden des EEG in Verbindung gebracht
(Osterhout & Nicol, 1999).

SUBLIMINALES SYNTAKTISCHES PRIMING 4
In der Verarbeitung von Sprache sind einige EKP bekannt, wie zum Beispiel das
N400, das P600, welches auch als „late positive component“ (LPC) bekannt ist, sowie die
„left anterior negativity“ (LAN). Das N400 ist ein EKP, welches nach einer Dauer von 400
ms negativ ausschlägt, wenn einem vorausgehenden Satz ein nicht erwartetes oder
ungewöhnliches Wort folgt (Guajardo & Wicha, 2014). Das N400 wird mit semantischer
Verarbeitung in Verbindung gebracht. Die LPC sowie die LAN werden eher mit syntaktischer
als mit semantischer Verarbeitung in Verbindung gebracht. Die LAN ist ein EKP, welches
zwischen 300 und 450 ms negativ ausschlägt und die LPC ist ein EKP, welches nach 600 ms
positiv ausschlägt. Die LPC unterteilt sich laut Barber und Carreiras (2005) in zwei separate
Verarbeitungsstadien, die LPCa sowie die LPCb. Die LPCa-Amplitude schlägt bei einer
Verletzung der grammatikalischen Übereinstimmung der geschlechtsbedingten Wortbeugung
in einem Satz aus, aber nicht bei einer Verletzung des semantischen Inhaltes. Die LPCb-
Amplitude schlägt hingegen sowohl bei einer Verletzung der grammatikalischen
Übereinstimmung der geschlechtsbedingten Wortbeugung als auch bei einer Verletzung des
semantischen Inhaltes aus (Guajardo & Wicha, 2014). Die exakte funktionelle Interpretation
der soeben genannten EKP wird noch diskutiert (Tanner & Van Hell, 2014).
1.06 Erste Studien zu semantischem Priming
Historisch gesehen wurde semantisches Priming vor syntaktischem Priming
untersucht. Semantisches Priming basiert auf unserem semantischen Gedächtnis, welches laut
Hutchison (2003) wie ein Wortlexikon eine immense Menge an Informationen bezüglich der
Konzepte bzw. der Bedeutung von Wörtern beinhaltet. Das semantische Gedächtnis beinhaltet
außerdem Informationen darüber, welche Wörter ähnliche Bedeutungen haben (Hutchison,
2003).
Laut Collins und Loftus (1975) kann man sich die verschiedenen Konzepte der Wörter
wie separate Knoten in einem semantischen Netzwerk vorstellen, deren semantische
Verwandtheit durch die Stärke der Verbindungen und durch die Distanz zwischen diesen
Knoten abhängig ist. Semantisch verwandte Konzepte verfügen über stärkere und kürzere
Verbindungen als semantisch nicht verwandte Konzepte. Beispielsweise kann man davon
ausgehen, dass die Konzepte der Wörter „dunkel“ und „Nacht“ eine stärkere und nähere
Verbindung in diesem semantischen Netzwerk haben als die Konzepte der Wörter „dunkel“
und „Zitrone“.
Erstmals experimentell beschrieben wurde semantische Priming von Meyer und
Schvaneveldt (1971), welche in ihrer Studie untersuchten, inwieweit die Bedeutung von zwei
dargebotenen Wörtern die Reaktionsgeschwindigkeit bei einer lexikalischen

SUBLIMINALES SYNTAKTISCHES PRIMING 5
Entscheidungsaufgabe beeinflussen würde. Die Versuchspersonen mussten in dem besagten
Experiment eine lexikalische Entscheidungsaufgabe durchführen, indem sie bei zwei
gleichzeitig präsentierten Buchstabenketten bestimmen mussten, ob es sich um echte Wörter
oder Pseudo-Wörter handelte. Ihnen wurden entweder zwei echte Wörter, zwei Pseudo-
Wörter oder ein Wort und ein Pseudo-Wort präsentiert. Es zeigte sich, dass die
Versuchspersonen bei der Darbietung semantisch verwandter Wortpaare (z.B. „Brot“ &
„Butter“, engl. „bread“ & „butter“) schneller und genauer antworteten als bei der
Darbietung semantisch nicht verwandter Wortpaare (z.B. „Doktor“ & „Butter“, engl.
„doctor“ & „butter“).
Anknüpfende Untersuchungen konnten feststellen, dass semantisches Priming auch
auftrat, wenn die Wortpaare nacheinander präsentiert wurden (vgl. Neely, 1976; Goodman et
al. 1981). Weiterführende Untersuchungen konnten ebenfalls aufzeigen, dass semantische
Primingeffekte auch dann beobachtet werden konnten, wenn die Primes nur unbewusst
wahrgenommen wurden (vgl. Greenwald, Draine & Abrams, 1996; Kiefer, 2002; Kiefer &
Spitzer, 2000; Klinger & Greenwald, 1995; Marcel, 1983; Merikle & Daneman, 1998).
Bewusst wahrnehmbare Primes werden als supraliminal und unbewusst wahrnehmbare
Primes als subliminal bezeichnet (Kiesel, 2009).
1.07 Unbewusste Wahrnehmung durch Maskierungstechniken
Als unbewusste Wahrnehmung wird die Wirkung unterschwelliger und somit nicht
bewusst wahrnehmbarer Reize auf das Verhalten bezeichnet Kiesel (2009). Um die
unbewusste Wahrnehmung des Primes in einem Experiment sicherzustellen, kann auf
Maskierungstechniken zurückgegriffen werden. Bei diesen Maskierungstechniken werden die
Primes zum Beispiel sehr kurz präsentiert (10 bis 50 Millisekunden (ms)) und es werden
zufällige Buchstabenketten, welche als Masken dienen, vor und nach dem Prime eingeblendet
(Kiesel, 2009). Die Maske, die vor dem Prime auftritt, bezeichnet man als Vorwärtsmaske
und die Maske, die nach dem Prime auftritt, als Rückwärtsmaske. Obwohl der Prime durch
die Maskierungstechnik nicht mehr bewusst wahrgenommen wird, hat er dennoch Einfluss
auf die Verarbeitung des Targets (Kiesel, 2009).
Am Ende eines Durchgangs eines Experimentes oder nach Abschluss des gesamten
Experimentes, kann überprüft werden, ob die Darbietung des Primes tatsächlich für die
Versuchspersonen nur subliminal wahrnehmbar war. Die Versuchspersonen werden hierzu
instruiert, den Versuch zu unternehmen, den subliminalen Prime zu erkennen und ihn zu
kategorisieren (vgl. Kiesel, 2009).

SUBLIMINALES SYNTAKTISCHES PRIMING 6
In der Studie von Goodman et al. (1981) wurde beispielsweise gezeigt, dass
syntaktisches Priming mit supraliminalen Primes funktioniert. Sereno (1991) konnte in ihrer
Studie durch den Einsatz einer Maskierungstechnik aufzeigen, dass syntaktisches Priming
auch mit subliminalen Primes gelingt.
1.08 Forschung zu supraliminalem syntaktischen Priming
Goodman et al. (1981) haben eine Studie durchgeführt, in der speziell das syntaktische
Priming bezüglich der Worterkennung unabhängig vom semantischen Kontext untersucht
wurde. Laut Goodman et al. (1981) wurde bis dahin in keiner Studie die syntaktische Rolle
beim Priming getrennt vom semantischen Kontext untersucht. Der syntaktische Priming
Effekt wurde im Rahmen dieser Studie mit Hilfe von lexikalischen Entscheidungsaufgaben in
Zwei-Wort-Sätzen untersucht. Dabei wurde ein einzelnes Wort als Prime gezeigt, welches die
syntaktische Klasse des folgenden Targets voraussagbar machte, aber keinen Hinweis auf die
Bedeutung dieses Targets lieferte. Diese Methode sollte den Störfaktor der semantischen
Information in der Untersuchung des syntaktischen Primings minimieren (Goodman et al,
1981). Die beschriebenen Zwei-Wort-Sätze setzten sich aus einem führenden
Personalpronomen oder Artikel als Prime sowie einem folgenden Verb oder Substantiv als
Target zusammen. Die kongruenten Bedingungen in dieser Studie waren beispielsweise jene,
die aus Personalpronomen und Verben (z.B. „he exists“, dt. „er existiert“) bestanden sowie
jene, die aus Artikeln und Substantiven (z.B. „the tree“, dt. „der Baum“) bestanden. Die
inkongruenten Bedingungen waren beispielsweise jene, die aus Personalpronomen und
Substantiven (z.B. „he tree“, dt. „er Baum“) bestanden sowie jene, die aus Artikeln und
Verben (z.B. „the exists“, dt. „der existiert“) bestanden. Den Versuchspersonen wurde auf
einem Bildschirm in jedem Durchgang zunächst ein Fixationskreuz für 200 ms gezeigt,
welchem für 300 ms ein leerer Bildschirm folgte. Danach wurde der Prime für 200 ms
gezeigt, welchem wieder für 300 ms ein leerer Bildschirm folgte. Anschließend wurde das
Target solange gezeigt, bis die Versuchspersonen eine lexikalische Entscheidung trafen. Der
Prime war für die Versuchspersonen bewusst wahrnehmbar.
Die Ergebnisse dieser Studie zeigten, dass lexikalische Entscheidungen in syntaktisch
kongruenten Bedingungen signifikant schneller ausfielen als in syntaktisch inkongruenten
Bedingungen. Es konnte somit nachgewiesen werden, dass syntaktisch Kongruenz die
Erkennung von Wörtern in lexikalischen Entscheidungsaufgaben erleichtert (Goodman et al.,
1981).
Seidenberg, Waters, Sanders und Langer (1984) haben ebenfalls syntaktisches Priming
untersucht und haben in ihrer Studie in einem Experiment die Studie von Goodman et al.

SUBLIMINALES SYNTAKTISCHES PRIMING 7
(1981) repliziert. Sie haben dieselben Stimuli wie Goodman et al. (1981) verwendet,
allerdings wurde die Methode leicht abgewandelt. Die Stimuli wurden ebenfalls auf einem
Computerbildschirm gezeigt, jedoch mit einer anderen Präsentationsdauer. In jedem
Durchgang wurde zunächst ein Fixationskreuz für 2 Sekunden (s) gezeigt, gefolgt von einem
Prime für 600 ms. Danach wurde das Target so lange gezeigt, bis die Versuchspersonen eine
lexikalische Entscheidung abgaben oder 2 s vergingen. Der Prime war aufgrund der
Präsentationsdauer von 600 ms auch in dieser Studie für die Versuchspersonen supraliminal
wahrnehmbar. Die Ergebnisse dieser Studie zeigten, dass die Erkennung von Wörtern in
syntaktisch kongruenten Bedingungen signifikant schneller und mit signifikant weniger
Fehlern ausfielen, als die Erkennung von Wörtern in syntaktisch inkongruenten Bedingungen.
Somit konnten Seidenberg et al. (1984) die Ergebnisse der Studie von Goodman et al. (1981)
bestätigen.
In einer Studie von Wright und Garrett (1984) wurde mit Hilfe von lexikalischen
Entscheidungsaufgaben der syntaktische Einfluss auf die Worterkennung in Sätzen
untersucht. Den Versuchspersonen wurden in einem Experiment Sätze präsentiert, welche
Wort für Wort auf einem Computerbildschirm aufschienen. Das als letztes eingeblendete
Wort war zugleich das Target, bezüglich dessen die Versuchspersonen eine lexikalische
Entscheidung treffen mussten.
Die Methode sah im Detail wie folgt aus: Zu Beginn eines Durchgangs wurde den
Versuchspersonen ein Fixationskreuz auf der linken Seite des Computerbildschirms gezeigt.
Diesem folgte ein Satz, welcher Wort für Wort von links nach rechts eingeblendet wurde.
Jedes neue Wort, bis auf das Target, erschien nach genau 200 ms. Nach dem vorletzten Wort
erklang nach 100 ms ein kurzer Ton. Weitere 300 ms nach diesem Ton wurde das Target in
Großbuchstaben eingeblendet und die Versuchspersonen mussten bezüglich des Targets eine
lexikalische Entscheidung treffen. Syntaktisch korrekte Bedingungen waren beispielsweise
jene, die aus Modalverben und Verben bestanden sowie jene, die aus Präpositionen und
Substantiven bestanden. Syntaktisch inkorrekte Bedingungen waren jene, die aus
Modalverben und Substantiven bestanden sowie jene, die aus Präpositionen und Verben
bestanden. Zum Beispiel wurde der Satz „If your bicycle is stolen, you must“ (dt. „Wenn dein
Fahrrad gestohlen wurde, musst du“) eingeblendet und als Target konnten beispielsweise das
Verb „FORMULATE“ (dt. „FORMULIEREN“) oder das Substantiv „BATTERIES“ (dt.
„BATTERIEN“) folgen. Beide Targets, die zur Auswahl standen, ergaben in diesem
Beispielsatz semantisch keinen Sinn, aber aus syntaktischer Sicht wurde hier ein Verb
erwartet. Anders verhielt es sich beispielsweise bei dem Satz „For now, the happy family

SUBLIMINALES SYNTAKTISCHES PRIMING 8
lives with“ (dt. „Derzeit lebt die glückliche Familie mit“) und den soeben genannten Targets.
Auch bei diesem Beispielsatz ergaben beide Möglichkeiten semantisch keinen Sinn, aber aus
syntaktischer Sicht wurde ein Substantiv erwartet (Wright & Garrett, 1984). In der Studie von
Wright und Garrett (1984) wurde zwar nicht der syntaktische Priming-Effekt mit Zwei-Wort-
Sätzen wie bei Goodman et al. (1981) untersucht, die Ergebnisse zeigten aber, dass die
Erkennung der Targets unter syntaktisch korrekten Bedingungen signifikant schneller und mit
signifikant weniger Fehlern ausfiel als unter syntaktisch inkorrekten Bedingungen.
West und Stanovich (1986) untersuchten in ihrer Studie ebenfalls mit Hilfe von
lexikalischen Entscheidungsaufgaben den Einfluss syntaktischer Strukturen in Sätzen auf die
Worterkennung. Hierbei replizierten sie in ihren Experimenten die Studie von Wright und
Garrett (1984). Sie präsentierten den Versuchspersonen dieselben Stimuli unter leicht
abgewandelten Bedingungen. Die Sätze wurden den Versuchspersonen nicht Wort für Wort,
sondern in einem bis auf das Target vollständigen Satzfragment präsentiert. Außerdem
mussten die Versuchspersonen die Satzfragmente in einem Experiment laut vorlesen und in
einem weiteren Experiment für sich lautlos lesen. Bezüglich des Targets mussten sie in beiden
Experimenten eine lexikalische Entscheidung treffen. Wie in der Studie von Wright und
Garrett (1984) waren auch in dieser Studie die syntaktisch korrekten Bedingungen jene, die
aus Modalverben und Verben bestanden und jene, die aus Präpositionen und Substantiven
bestanden. Syntaktisch inkorrekte Bedingungen waren jene, die aus Modalverben und
Substantiven bestanden sowie jene, die aus Präpositionen und Verben bestanden. Es zeigte
sich auch in dieser Studie, dass die Erkennung der Targets unter syntaktisch korrekten
Bedingungen signifikant schneller und mit signifikant weniger Fehlern ausfiel als unter
syntaktisch inkorrekten Bedingungen. Die Ergebnisse dieser Studie konnten somit
demonstrieren, dass der Einfluss syntaktischer Strukturen auf die Worterkennung, wie schon
in der Studie von Wright und Garrett (1984) gezeigt wurde, robust ist (West & Stanovich,
1986).
1.09 Forschung zu subliminalem syntaktischen Priming
Sereno (1991) untersuchte in ihrer Studie in zwei Experimenten den syntaktischen
Priming-Effekt in lexikalischen Entscheidungsaufgaben. In dieser Studie wurden die Primes
allerdings nur für 60 ms präsentiert und waren durch diese kurze Präsentationsdauer nicht
mehr supraliminal, sondern nur noch subliminal wahrnehmbar. Sie nutzte im Gegensatz zu
Goodman el at. (1981) nicht Zwei-Wort-Sätze, sondern das „three-word masking“-Paradigma
nach Forster und Davis (1984) für ihre Studie. Bei dieser Prozedur wurden drei Wörter
nacheinander in derselben Position auf einem Bildschirm dargestellt. Der erste Stimulus, ein

SUBLIMINALES SYNTAKTISCHES PRIMING 9
neutrales Wort, erschien für 500 ms; der zweite Stimulus, der Prime, wurde für 60 ms
präsentiert und der dritte Stimulus, das Target, wurde solange gezeigt, bis die
Versuchspersonen antworteten. Der Prime wurde durch das erste Wort vorwärts und durch
das dritte Wort rückwärts maskiert und war somit für die Versuchspersonen nicht mehr
bewusst wahrnehmbar. Ein syntaktisch kongruentes Beispiel aus dem Experiment war der
Satz „begin this CIRCUS“ (dt. „beginn diesen ZIRKUS“), da hier einem Artikel ein
Substantiv folgte. Der Artikel „this“ (dt. „diesen“) diente als Prime, während das Substantiv
„CIRCUS“ (dt. „ZIRKUS“) als Target fungierte. Alle Targets in dieser Studie wurden in
Großbuchstaben dargestellt. Die Satzfragmente ergaben semantisch keinen Sinn, damit
sichergestellt werden konnte, dass ausschließlich der syntaktische Effekt gemessen wurde.
Ein Beispiel für ein syntaktisch inkongruentes Satzfragment war „begin could CIRCUS“ (dt.
„beginn könnte ZIRKUS“), da hier einem Modalverb ein Substantiv folgte. Die
Versuchspersonen mussten bezüglich des Zielreizes eine lexikalische Entscheidung treffen.
Es zeigte sich, dass lexikalische Entscheidungen in syntaktisch kongruenten Bedingungen
signifikant schneller erfolgten als in syntaktisch inkongruenten Bedingungen. Sereno (1991)
konnte damit zeigen, dass syntaktische Priming-Effekte auch unter subliminalen Bedingungen
auftreten können.
Ansorge und Becker (in Vorbereitung) haben in ihrer Studie semantisches und
syntaktisches Priming unter supraliminalen und subliminalen Bedingungen anhand einer
Wortklassifikationsaufgabe untersucht. Die deutschsprachigen Versuchspersonen mussten in
einer Wortklassifikationsaufgabe entscheiden, ob es sich bei den sichtbaren Targets um
Substantive oder Verben handelte. Als subliminale und supraliminale Primes wurden die
deutschen Pronomen „ich“, „du“ und „wir“ herangezogen. Neben der Kongruenz der
Wortklassen spielte auch die morphosyntaktische Kongruenz eine Rolle. Die Bedingungen,
die aus Pronomen und Verben bestanden, waren Wortklassen-kongruent (z.B. „ich gehe“)
während die Bedingungen, die aus Pronomen und Substantiven (z.B. „ich Haus“) bestanden,
Wortklassen-inkongruent waren. Die morphosyntaktische Kongruenz zwischen Prime und
Target bezog sich auf deren Übereinstimmung hinsichtlich der grammatikalischen Numeri.
Eine morphosyntaktisch kongruente sowie Wortklassen-kongruente Bedingung war
beispielsweise der Zwei-Wort-Satz „wir gehen“, da die aufeinanderfolgenden Wortklassen
syntaktisch korrekt waren und die grammatikalischen Numeri von Prime und Target
übereinstimmten. Eine morphosyntaktisch inkongruente, aber Wortklassen-kongruente
Bedingung war beispielsweise der Zwei-Wort-Satz „wir gehe“, da die aufeinanderfolgenden

SUBLIMINALES SYNTAKTISCHES PRIMING 10
Wortklassen syntaktisch korrekt waren, aber die grammatikalischen Numeri von Prime und
Target nicht übereinstimmten.
Es wurde gezeigt, dass es unter subliminalen Bedingungen zu einer Erleichterung der
Wortklassifikation von Verben im Vergleich zu der Wortklassifikation von Substantiven kam,
wenn ihnen Pronomen vorausgingen. Es gab keine Anzeichen dafür, dass der subliminale
Wortklassen-Kongruenzeffekt von einer morphosyntaktischen Übereinstimmung (d.h.,
korrekte Deklination oder Konjugation) von Prime und Target abhängig war, da die
morphosyntaktische Kongruenz zwischen Prime und Target keinen signifikanten Einfluss auf
die subliminale Wortklassifikationsaufgabe hatte.
1.10 Gegenstand und Ziele der vorliegenden Untersuchung
In der vorliegenden Studie wurde subliminales syntaktisches Priming untersucht.
Dabei wurde der Einfluss von maskierten Pronomen als Primes (folgend als „Pronomen-
Primes“ bezeichnet) auf die Erkennung von sichtbaren Verben oder Substantiven als Targets
erforscht. Das Ziel dieser Untersuchung war es herauszufinden, ob Verben (folgend als
„Target-Verben“ bezeichnet) im Vergleich zu Substantiven (folgend als „Target-Substantive“
bezeichnet) in lexikalischen Entscheidungsaufgaben signifikant schneller und mit signifikant
weniger Fehlern erkannt werden, wenn ihnen subliminal wahrnehmbare Pronomen-Primes
vorausgehen. Hierbei wurden sowohl die Reaktionszeiten als auch die Fehlerraten der
lexikalischen Entscheidungen bezüglich der Target-Verben und der Target-Substantive
erfasst. Syntaktisch kongruent waren die Bedingungen, in denen die Pronomen-Primes den
Target-Verben vorausgingen und syntaktisch inkongruent waren jene Bedingungen, in denen
die Pronomen-Primes den Target-Substantiven vorausgingen.
Wenn es zu einer schnelleren und fehlerfreieren lexikalischen Entscheidung der
syntaktisch kongruenten Bedingungen im Vergleich zu den syntaktisch inkongruenten
Bedingungen kommen würde, müsste außerdem untersucht werden, ob die Pronomen-Primes
der Grund für diesen Vorteil waren. Um dies überprüfen zu können, wurden als
Vergleichsmaßstab zu den Pronomen sogenannte Pseudo-Pronomen entwickelt und ebenfalls
als Primes (folgend als „Pseudo-Pronomen-Primes“ bezeichnet) eingesetzt.
Wenn es zu einer schnelleren und fehlerfreieren Erkennung der Targets in den
syntaktisch kongruenten Bedingungen bestehend aus Pronomen-Primes und Target-Verben,
aber zu keiner schnelleren und fehlerfreieren Erkennung der Targets in den syntaktisch
inkongruenten Bedingungen bestehend aus Pseudo-Pronomen-Primes und Target-Verben
käme, dann könnte man folglich davon ausgehen, dass die Pronomen-Primes eine
Auswirkung auf die schnellere und fehlerfreiere Erkennung der Target-Verben gehabt hätten.

SUBLIMINALES SYNTAKTISCHES PRIMING 11
Es wurde daher angenommen, dass es zu einer Erleichterung der lexikalischen Entscheidung
führen würde, wenn den Target-Verben Pronomen-Primes vorausgingen und es zu keiner
Erleichterung der lexikalischen Entscheidung führen würde, wenn den Target-Verben Pseudo-
Pronomen-Primes vorausgingen. Demzufolge wurde erwartet, dass die Reaktionszeiten und
die Fehlerrate in lexikalischen Entscheidungen bezüglich der Target-Verben signifikant
geringer wären, wenn ihnen Pronomen-Primes als wenn ihnen Pseudo-Pronomen-Primes
vorausgingen.
Für die lexikalischen Entscheidungsaufgaben wurden neben echten Wörtern auch
Pseudo-Wörter benötigt. Daher wurden sowohl Pseudo-Wörter für die Target-Verben als auch
Pseudo-Wörter für die Target-Substantive entwickelt. Folgend werden echte Wörter als
„Targets“, Pseudo-Wörter generell als „Pseudo-Targets“, Pseudo-Wörter für Target-Verben
als „Pseudo-Target-Verben“ und Pseudo-Wörter für Target-Substantive als „Pseudo-Target-
Substantive“ bezeichnet.
In Anlehnung an die Studie von Ansorge und Becker (in Vorbereitung), in der gezeigt
wurde, dass die korrekte Deklination oder Konjugation von Prime und Target in einer
Wortklassifikationsaufgabe keine signifikante Rolle spielte, wurde in der vorliegenden Studie
ebenfalls angenommen, dass die korrekte Deklination oder Konjugation von Pronomen-
Primes und Target-Verben keinen signifikanten Einfluss auf die Reaktionszeiten und
Fehlerraten in lexikalischen Entscheidungen haben würde. Es wurde demnach erwartet, dass
es sowohl in lexikalischen Entscheidungsaufgaben, in denen die Wortbeugungen der Target-
Verben den vorausgehenden Pronomen-Primes entsprachen (morphosyntaktisch kongruent),
als auch in lexikalischen Entscheidungsaufgaben, in denen die Wortbeugungen der Target-
Verben nicht den vorausgehenden Pronomen-Primes entsprachen (morphosyntaktisch
inkongruent), zu einer signifikanten Erleichterung der lexikalischen Entscheidung im
Vergleich zu syntaktisch inkongruenten Bedingungen kommen würde. Es wurde somit
angenommen, dass die Reaktionszeiten und die Fehlerraten in lexikalischen
Entscheidungsaufgaben nicht nur in morphosyntaktisch kongruenten (z.B. „ich GEHE“),
sondern auch in morphosyntaktisch inkongruenten Bedingungen (z.B. „ich GEHEN“) im
Vergleich zu syntaktisch inkongruenten Bedingungen (z.B. „ich HAUS“) geringer wären.
Als syntaktisch inkongruente Bedingungen wurden neben der Bedingung, in der
Pronomen-Primes den Target-Substantiven vorausgingen, alle folgenden Bedingungen
betrachtet: Pseudo-Pronomen-Primes, denen Target-Verben folgten; Pseudo-Pronomen-
Primes, denen Target-Substantive folgten; Pseudo-Pronomen-Primes, denen Pseudo-Target-
Verben folgten und Pseudo-Pronomen-Primes, denen Pseudo-Target-Substantive folgten. Es

SUBLIMINALES SYNTAKTISCHES PRIMING 12
wurden keine signifikanten Veränderungen bezüglich der Reaktionszeiten und der Fehlerraten
in diesen Bedingungen erwartet.
Abschließend ist zu erwähnen, dass im Rahmen der Untersuchung anhand einer
Primesichtbarkeitsaufgabe kontrolliert wurde, ob die Pronomen-Primes und die Pseudo-
Pronomen-Primes tatsächlich nicht bewusst wahrnehmbar waren. Hierbei mussten die
Versuchspersonen in jedem Durchgang entscheiden, ob es sich bei dem subliminal
präsentieren Prime um einen Pronomen-Prime oder um einen Pseudo-Pronomen-Prime
handelte. Es wurde erwartet, dass die Antworten der Versuchspersonen bezüglich der
Erkennung der maskierten Primes dem Zufall entsprechen und die Untersuchung somit unter
subliminalen Bedingungen erfolgen würde.
2. Methode
2.01 Untersuchungsteilnehmer
Insgesamt nahmen 35 Versuchspersonen freiwillig an dieser Untersuchung teil. Von
diesen 35 Versuchspersonen waren 28 weiblich und 7 männlich. Alle Versuchspersonen
waren zu dem Zeitpunkt der Testung Psychologiestudentinnen und Psychologiestudenten an
der Universität Wien und wurden über das Kommunikationssystem „RSAP“ des „Instituts für
Psychologische Grundlagenforschung und Forschungsmethoden“ rekrutiert. Die
Versuchspersonen erhielten für ihre Teilnahme am Experiment sogenannte
„Versuchspersonenstunden“, welche sie als Bonuspunkte in Pflichtlehrveranstaltungen im
Fachbereich der Allgemeinen Psychologie an der Universität Wien einsetzen konnten. Es
wurden ausschließlich Versuchspersonen rekrutiert, die über gute Deutschkenntnisse
verfügten, um die korrekte Differenzierung von Wörtern und Pseudo-Wörtern in der
lexikalischen Entscheidungsaufgabe gewährleisten zu können. Die Deutschkenntnisse der
Versuchspersonen wurden vorab schriftlich per E-Mail und im persönlichen Gespräch vor
Beginn der Testung überprüft. Alle Versuchspersonen verfügten zum Zeitpunkt der Testung
nach eigenen Aussagen über ausreichendes Sehvermögen. Sie waren entweder normalsichtig
oder korrigierten ihre Fehlsichtigkeit durch eine Brille oder Kontaktlinsen.
Die Testdaten von 4 Versuchspersonen wurden in der Auswertung der Ergebnisse
nicht berücksichtigt, da diese in den lexikalischen Entscheidungsaufgaben das festgelegte
Fehlerraten-Kriterium nicht erfüllen konnten. Diese 4 Versuchspersonen begingen mehr als
die maximal erlaubten 20% Fehler in den lexikalischen Entscheidungsaufgaben.

SUBLIMINALES SYNTAKTISCHES PRIMING 13
Von den restlichen 31 Versuchspersonen, welche in die Auswertung miteinbezogen
wurden, waren 26 weiblich und 5 männlich. Das Alter dieser Versuchspersonen lag zwischen
18 und 31 Jahren und der Altersdurchschnitt betrug 21,9 Jahre. Drei der Versuchspersonen
waren Linkshänder und 28 Rechtshänder.
2.02 Instrumente und Messgeräte
Die Untersuchung wurde als Computertestung in dem Testraum TR-K 5 der Fakultät
für Psychologie in Wien durchgeführt. In dem Testraum, welcher ruhig und fensterlos war,
standen zwei Computer zur Verfügung. Hinter den beiden Computerbildschirmen stand
jeweils eine Tischlampe, die den Raum künstlich beleuchtete. Die Deckenbeleuchtung blieb
während der Untersuchungsdurchführung ausgeschalten. Durch die schwache und indirekte
Beleuchtung sollten Spiegelungen auf den Computerbildschirmen und potentiell störende
Lichtverhältnisse vermieden werden. Die zwei verwendeten Computerbildschirmtypen waren
15 Zoll große Kathodenstrahlmonitore, auf denen die schriftlichen Instruktionen zu der
Testung und anschließend die Stimuli mit einer Bildwiederholungsrate von 59.1 Hertz (Hz)
präsentiert wurden. Die Stimuli wurden in der Bildschirmmitte in schwarzer Schrift (< 1
cd/m²) auf hellem Hintergrund (24 cd/m²) dargestellt. Die Buchstaben passten in Rechtecke
der Kantenlängen der Höhe 1.1° und der Breite 0.6°. Es wurden Kinnstützen 57 cm vor den
Computerbildschirmen angebracht, um einen konstanten Abstand der Versuchspersonen zu
den Computerbildschirmen und einen zu den Computerbildschirmen gerichteten Blick zu
gewährleisten. Die Antworten bezüglich der lexikalischen Entscheidungen und der
Primesichtbarkeitsaufgabe wurden über den Nummernblock einer Standardcomputertastatur
abgegeben. Die Versuchspersonen starteten jeden Durchgang selbst, indem sie mit dem
rechten Zeigefinger der rechten Hand die Taste #5 drückten. Die lexikalischen
Entscheidungen und die Antworten bezüglich der Primesichtbarkeitsaufgabe gaben die
Versuchspersonen durch das Drücken der Tasten #4 oder #6 mit demselben Finger ab. Durch
Messungen der Reaktionszeit in Millisekunden (ms) und der Fehlerrate in Prozent (%)
wurden die lexikalischen Entscheidungen der Versuchspersonen erfasst.
2.03 Reizmaterial
Als Pronomen-Primes wurden der 1. Fall Singular „ich“ und der 1. Fall Plural „wir“
gewählt. Als Pseudo-Pronomen-Primes wurden die beiden Pseudo-Wörter „mek“ und „mun“
kreiert. Das Pseudo-Wort „mek“ wurde als Pseudo-Pronomen-Prime für den 1. Fall Singular
und das Pseudo-Wort „mun“ als Pseudo-Pronomen-Prime für den 1. Fall Plural eingesetzt.
Die Pseudo-Pronomen-Primes wurden mit der Absicht erstellt, keinen echten Pronomen zu

SUBLIMINALES SYNTAKTISCHES PRIMING 14
ähneln, aber über eine wortähnliche Form zu verfügen und aussprechbar zu sein. Die
Pronomen-Primes und die Pseudo-Pronomen-Primes wurden in der vorliegenden
Untersuchung immer kleingeschrieben dargestellt.
Für die Targets wurden Wortlisten erstellt, welche aus 68 Verben des 1. Fall Singular
und 68 Verben des 1. Fall Plural sowie aus 68 Substantiven im Singular und 68 Substantiven
im Plural bestanden.
Für die Wortlisten wurden zunächst die Verben ausgewählt. Zu jedem dieser Verben
wurden ein Singular- und ein Pluralsubstantiv mit einem oder zwei gleichen
Anfangsbuchstaben und ein Singular- und ein Pluralsubstantiv mit einem oder zwei gleichen
Endbuchstaben ausgewählt. Hierbei wurde beachtet, dass jedes Wort eindeutig als Verb oder
Substantiv sowie als Singular oder Plural klassifiziert werden konnte. Die Liste der Verben
wurde noch um weitere Verben ergänzt, deren erster oder erste beiden Anfangsbuchstabe/n
oder deren letzter oder letzten beiden Endbuchstabe/n mit dem eines bereits gewählten Verbes
übereingestimmt hatten.
Zu jedem echten Wort wurde in weiterer Folge ein Pseudo-Wort entwickelt, indem ein
mittlerer oder zwei mittlere Buchstabe/n des echten Wortes durch einen anderen oder zwei
andere Buchstabe/n ersetzt wurde/n, ein weiterer Buchstabe hinzugefügt wurde oder ein
Buchstabe weggelassen wurde. Beispielsweise wurde aus dem Singular-Verb „BLINKE“ das
Singular-Pseudo-Verb „BLIMKE“ und aus dem Plural-Substantiv „KASSEN“ das Plural-
Pseudo-Substantiv „KATTEN“ kreiert. Alle Pseudo-Wörter verfügten über eine wortähnliche
Form und waren aussprechbar. Die 68 Pseudo-Verben im Singular und 68 Pseudo-Verben im
Plural sowie die 68 Pseudo-Substantive im Singular und die 68 Pseudo-Substantive im Plural
vervollständigten somit die Wortlisten.
Alle Targets und Pseudo-Targets wurden in Anlehnung an die Studie von Sereno
(1991) in Großbuchstaben dargestellt. Alle Umlaute („Ä“, „Ö“, „Ü“) wurden durch den
jeweiligen Vokal samt einem nachgestellten „E“ dargestellt („AE“; „OE“; „UE“).
Die Targets und die Pseudo-Targets sind in alphabetischer Reihenfolge in den
Appendizes A bis D aufgelistet. Im Appendix A sind die Verben in der Form des Infinitivs,
des 1. Fall Singular und des 1. Fall Plural dargestellt. Im Appendix B sind zwei Wortlisten,
die Pseudo-Verben im Singular getrennt von den Pseudo-Verben Plural aufgelistet. Im
Appendix C werden die Substantive ebenfalls in einer Wortliste für die Singulare und in einer
Wortliste für die Plurale dargestellt. Abschließend werden im Appendix D die Pseudo-
Substantive ebenfalls in einer Wortliste für die Singulare und in einer Wortliste für die Plurale
unterteilt aufgezählt.

SUBLIMINALES SYNTAKTISCHES PRIMING 15
2.04 Untersuchungsdesign
Die Untersuchung umfasste 10 Blöcke mit jeweils 84 Durchgängen, also somit
insgesamt 840 Durchgänge. Innerhalb der Blöcke wurde eine Pseudorandomisierung
durchgeführt. Dies bedeutet, dass je Block immer gleich viele Pronomen-Primes und Pseudo-
Pronomen-Primes sowie gleich viele Target-Verben, Target-Substantive, Pseudo-Target-
Verben und Pseudo-Target-Substantive in gleicher kongruenter und inkongruenter Anzahl
präsentiert wurden. Die Bedingungen „Pronomen-Prime und Target-Verb“, „Pronomen-Prime
und Target-Substantiv“, „Pronomen-Prime und Pseudo-Target-Verb“, „Pronomen-Prime und
Pseudo-Target-Substantiv“, „Pseudo-Pronomen-Prime und Target-Verb“, „Pseudo-
Pronomen-Prime und Target-Substantive“, „Pseudo-Pronomen-Prime und Pseudo-Target-
Verb“ sowie „Pseudo-Pronomen-Prime und Pseudo- Target-Substantiv“ wurden somit je
Block gleich oft präsentiert, aber die Präsentationsabfolge dieser Bedingungen verlief
innerhalb der Blöcke randomisiert. Nach jedem Block wurde automatisch eine Pause
eingeleitet.
In jedem Durchgang wurde zunächst zentriert auf dem Computerbildschirm das
Fixationskreuz für 750 ms gezeigt. Anschließend wurde die Vorwärtsmaske, die aus zehn
zufällig gewählten Großbuchstaben (z.B. „BAEAFGIHLT“) bestand, für 200 ms gezeigt,
gefolgt von einem maskierten Pronomen-Prime (z.B. „ich“) oder Pseudo-Pronomen-Prime
(z.B. „mek“), welcher für 30 ms präsentiert wurde. Danach folgte die Rückwärtsmaske für 30
ms, die ebenfalls wie die Vorwärtsmaske aus zehn zufällig gewählten Großbuchstaben
bestand (z.B. „AFCFDZGLZM“). Zum Abschluss wurde ein Target-Verb (z.B. „GEBE“),
Target-Substantiv (z.B. „FLASCHE“), Pseudo-Target-Verb (z.B. „GEJE“) oder Pseudo-
Target-Substantiv (z.B. „FLUSCHE“) in Großbuchstaben präsentiert, bis die
Versuchspersonen eine lexikalische Entscheidung trafen oder 200 ms verstrichen. Alle
Stimuli wurden zentriert auf dem Computerbildschirm dargestellt. Die Inter-Stimulus-
Intervalle (ISI) betrugen 0 ms. Zum Abschluss jedes Durchgangs mussten die
Versuchspersonen entscheiden, ob es sich bei dem maskierten Prime um ein Pronomen-Prime
oder ein Pseudo-Pronomen-Prime handelte. In Abbildung 1 wird ein maskierter syntaktisch
kongruenter Durchgang und in Abbildung 2 ein maskierter syntaktisch inkongruenter
Durchgang dargestellt.

SUBLIMINALES SYNTAKTISCHES PRIMING 16
Abbildung 1. Schematische Darstellung eines maskierten syntaktisch kongruenten
Primingdurchgangs mit einem Pronomen des 1. Fall Singular als Prime und einem Verb des 1.
Fall Singular als Target. Der Pfeil zeigt die zeitliche Reizabfolge an. Die Stimuli in dieser
Abbildung entsprechen nicht dem Maßstab der in der Testung verwendeten Stimuli.
Abbildung 2. Schematische Darstellung eines maskierten syntaktisch inkongruenten
Primingdurchgangs mit einem Pronomen des 1. Fall Plural als Prime und einem Substantiv
des 1. Fall Singular als Target. Der Pfeil zeigt die zeitliche Reizabfolge an. Die Stimuli in
dieser Abbildung entsprechen nicht dem Maßstab der in der Testung verwendeten Stimuli.
+
BAEAFGIHLT
ich
AFCFDZGLZM
GEHE
Zeit
Fixationskreuz; 750 ms
Maske; 200 ms
Maske; 30 ms
Maskierter Prime; 30 ms
Target;
bis Antwort,
max. 200ms
+
BAEAFGIHLT
wir
AFCFDZGLZM
MOND
Zeit
Fixationskreuz; 750 ms
Maske; 200 ms
Maske; 30 ms
Maskierter Prime; 30 ms
Target;
bis Antwort,
max. 200ms

SUBLIMINALES SYNTAKTISCHES PRIMING 17
2.05 Untersuchungsdurchführung
Die Testungen fanden in den Monaten Dezember 2013 und Januar 2014 statt. Da zwei
Computer im Testraum zur Verfügung standen, konnten maximal zwei Versuchspersonen
gleichzeitig an einer Testeinheit teilnehmen. Die Versuchspersonen wurden vor Beginn der
Testung über die Untersuchungsbedingungen aufgeklärt. Sie erhielten eine schriftliche
Probandeninformation und eine Einverständniserklärung, welche sie zur Kenntnis nehmen
und unterschreiben mussten. Danach erhielten sie zur Erläuterung der Aufgaben eine
schriftliche Instruktion auf dem Computerbildschirm, welche bei Verständnisschwierigkeiten
durch mündliche Instruktionen seitens der Testleiterin ergänzt wurde.
Vor Beginn der eigentlichen Testung hatten die Versuchspersonen in einer
Übungsphase die Möglichkeit, das theoretische Verständnis der Aufgabe praktisch
umzusetzen, mit den Tastenkombinationen vertraut zu werden und der Testleiterin bei Bedarf
Verständnisfragen bezüglich der Testung zu stellen. Nach der Übungsphase, die je nach
Versuchsperson unterschiedlich lang ausfiel, aber durchschnittlich 15 Minuten dauerte, wurde
die Testung für beide Versuchspersonen gleichzeitig gestartet. Die Testleiterin verließ mit
dem Beginn der Testung den Testraum, um den Versuchspersonen während der
Untersuchungsdurchführung eine störungsfreie und ruhige Umgebung bieten zu können. Die
Testung beinhaltete nach jedem Block Pausen, welche von den Versuchspersonen in einem
individuellen Zeitausmaß genutzt werden konnten. Aufgrund der individuell langen Pausen
und der individuellen Geschwindigkeiten der Testbearbeitung der einzelnen
Versuchspersonen variierten die Testeinheiten je nach Versuchsperson zwischen 90 und 105
Minuten.
Die Versuchspersonen bearbeiteten im Rahmen der Testung zwei Aufgaben pro
Durchgang. Die erste Aufgabe beinhaltete die lexikalische Entscheidungsaufgabe bezüglich
des Zielreizes und die zweite Aufgabe die Primesichtbarkeitsaufgabe. Die Entscheidungen
gaben die Versuchspersonen in beiden Aufgabenstellungen über die Tastatur ab. Hierbei lag
der rechte Zeigefinger der rechten Hand zu Beginn jedes Durchgangs auf der Taste #5 des
Nummernblocks der Tastatur. Ein Durchgang wurde durch das Drücken dieser Taste gestartet.
Die lexikalischen Entscheidungen gaben die Versuchspersonen durch das Drücken der Tasten
#4 oder #6 mit demselben Finger ab. Bei einer fehlerhaften lexikalischen Entscheidung
erhielten die Versuchspersonen eine entsprechende schriftliche Rückmeldung auf dem
Computerbildschirm. Bei einer Überschreitung des Zeitlimits für die lexikalische
Entscheidung wurden sie ebenfalls entsprechend schriftlich via Computerbildschirm
informiert und aufgefordert, in den folgenden Durchgängen schneller zu antworten.

SUBLIMINALES SYNTAKTISCHES PRIMING 18
Jeder Durchgang beinhaltete neben der lexikalischen Entscheidungsaufgabe zusätzlich
die Primesichtbarkeitsaufgabe. Die Versuchspersonen gaben die Entscheidung, ob es sich bei
dem subliminal dargebotenen Prime um einen Pronomen-Prime oder um einen Pseudo-
Pronomen-Prime handelte, ebenfalls durch Drücken der Tasten #4 und #6 mit demselben
Finger ab. Sie erhielten keine Rückmeldungen zu ihren Entscheidungen in den
Primesichtbarkeitsaufgaben.
Um den möglichen Störfaktor der Antworttendenzen der Versuchspersonen, der durch
die Tastenbelegung hervorgerufen werden könnte, ausschließen zu können, gab es
hinsichtlich der Tastenbelegung zwei Varianten. In der ersten Variante mussten die
Versuchspersonen die Taste #6 für die Antwort „Wort“ drücken und die Taste #4 für die
Antwort „Pseudo-Wort“. In der Primesichtbarkeitsaufgabe mussten sie die Taste #6 für
„Pronomen-Prime“ und die Taste #4 für „Pseudo-Pronomen-Prime“ drücken. In der anderen
Variante galt die umgekehrte Ausführung. Die Versuchspersonen mussten die Taste #4 für die
Antwort „Wort“ drücken und die Taste #6 für die Antwort „Pseudo-Wort“ und in der
Primesichtbarkeitsaufgabe die Taste #4 für „Pronomen-Prime“ und die Taste #6 für „Pseudo-
Pronomen-Prime“. Die Versuchspersonen wurden zufällig einer der beiden Varianten
zugeordnet und die Aufteilung auf diese beiden Varianten wurde über die Versuchspersonen
ausbalanciert.
Eine schematische Abbildung eines Nummernblocks einer Standardcomputertastatur
samt Tastenbelegung in der Testung ist Abbildung 3 zu entnehmen.

SUBLIMINALES SYNTAKTISCHES PRIMING 19
Abbildung 3. Schematische Darstellung der Tastenbelegung des Nummernblocks in der
Testung. Die Versuchspersonen starteten jeden Durchgang, indem sie mit dem rechten Finger
der rechten Hand die Taste #5 (blauer Pfeil) des Nummernblocks drückten. Die lexikalische
Entscheidung bezüglich des Zielreizes gaben sie mit den Tasten #4 und #6 (rote Pfeile) ab.
Anschließend gaben sie ihre Antworten bezüglich des Primes ebenfalls mit dem Drücken der
Tasten #4 und #6 (rote Pfeile) ab. Der Nummernblock in dieser Abbildung entspricht nicht
dem Maßstab des in der Testung verwendeten Nummernblocks.
7
Home 8 9
PgUp
4 5 6
1
End 2 3
PgDn
0
Ins
.
Del
+
Enter
* / Num
Lock -
1

SUBLIMINALES SYNTAKTISCHES PRIMING 20
3. Ergebnisse
Die Ergebnisse der vorliegenden Studie wurden mit dem Programm SPSS
ausgewertet. Das Signifikanzniveau wurde sowohl für die Analyse der Reaktionszeiten als
auch für die Analyse der Fehlerraten bei α = 0,05 festgelegt. Alle Ergebnisse, die einen
Signifikanzwert von p < .05 aufwiesen, wurden folglich als signifikant betrachtet. Die
jeweiligen Grenzen der Signifikanzwerte wurden bei den entsprechenden Effekten nochmals
angeführt. Signifikanzwerte, die unter p < .01 liegen, wurden entsprechend gekennzeichnet.
3.01 Analyse der Reaktionszeiten
Die Reaktionszeiten (RZ) der Versuchspersonen wurden in Millisekunden (ms)
gemessen. Um die durchschnittlichen Reaktionszeiten der Versuchspersonen zu vergleichen,
wurde eine fünffaktorielle Varianzanalyse (ANOVA) mit den Variablen Zielreizwort (Target
vs. Pseudo-Target), grammatikalische Numeri (Singular vs. Plural), morphosyntaktische
Kongruenz (Kongruenz vs. Inkongruenz), Zielwortklasse (Verb vs. Substantiv) und Primereiz
(Pronomen-Prime vs. Pseudo-Pronomen-Prime) gerechnet. In der Bedingung Zielwortklasse
wurden die Verben und Substantive für die Pseudo-Wortbedingung nachgeahmt. Die fünf
Variablen mit je zwei Stufen ergaben somit ein 2 x 2 x 2 x 2 x 2 – Design.
Ein signifikanter Haupteffekt der Variable Zielreizwort, F(1, 30) = 182.69, p < .01, ηp²
= .86, zeigte, dass die Reaktionen auf Targets (Wörter) signifikant schneller waren (RZ = 801
ms) als die Reaktionen auf Pseudo-Targets (Pseudo-Wörter) (RZ = 893 ms) (siehe Abbildung
4).
Abbildung 4. Durchschnittliche Reaktionszeiten (in ms) des signifikanten
Haupteffekts der Variable Zielreizwort. Targets wurden durchschnittlich
um 92 ms schneller erkannt als Pseudo-Targets.
801
893
760
780
800
820
840
860
880
900
920
Targets Pseudo-Targets
Rea
ktio
nsz
eit
in m
s
Zielreizwort

SUBLIMINALES SYNTAKTISCHES PRIMING 21
Einen weiteren signifikanten Haupteffekt wies die Variable Zielwortklasse auf, F(1,
30) = 7.67, p < .05, ηp² = .20. Dieser Haupteffekt zeigt, dass die Reaktionen bei der
Erkennung von Substantiven signifikant schneller waren (RZ = 844 ms) als die Reaktionen
bei der Erkennung von Verben (RZ = 850 ms) (siehe Abbildung 5).
Abbildung 5. Durchschnittliche Reaktionszeiten (in ms) des signifikanten
Haupteffekts der Variable Zielwortklasse. Substantive wurden
durchschnittlich um 6 ms schneller erkannt als Verben.
Ebenfalls ergab sich ein signifikanter Haupteffekt für die Variable grammatikalische
Numeri, F(1, 30) = 17.16, p < .01, ηp² = .36. Dieser weist darauf hin, dass die Reaktionen auf
Singulare signifikant schneller waren (RZ = 842) als die Reaktionen Plurale (RZ = 852) (siehe
Abbildung 6).
844 850
760
780
800
820
840
860
880
900
920
Substantive Verben
Rea
ktio
nsz
eit
in m
s
Zielwortklasse

SUBLIMINALES SYNTAKTISCHES PRIMING 22
Abbildung 6. Durchschnittliche Reaktionszeiten (in ms) des signifikanten
Haupteffekts der Variable grammatikalische Numeri. Singulare wurden
um 10 ms schneller erkannt als Plurale.
Eine signifikante Zweifach-Interaktion ergab sich für die Variablen Zielreizwort und
Primereiz, F(1, 30) = 5.58, p < .05, ηp² = .16. Diese Interaktion deutet darauf hin, dass die
Reaktionen schneller waren, wenn einem Pseudo-Target ein Pseudo-Pronomen-Prime
vorausging (RZ = 891 ms) als wenn einem Pseudo-Target ein Pronomen-Prime vorausging
(RZ = 895 ms). Außerdem lässt sie andeuten, dass die Reaktionen schneller waren, wenn
einem Target ein Pronomen-Prime vorausging (RZ = 800 ms) als wenn einem Target ein
Pseudo-Pronomen-Prime vorausging (RZ = 803 ms). Um diese signifikante Zweifach-
Interaktion aufzuschlüsseln, wurde in weiterer Folge im Rahmen eines Post-hoc-Tests ein t-
Test nach Bonferroni durchgeführt, in welchem durch paarweise Mittelwertvergleiche
herausgefunden werden sollte, welche Mittelwerte in dieser Zweifach-Interaktion sich
signifikant voneinander unterschieden. Beide paarweisen Mittelwertvergleiche zeigten in den
t-Tests keine signifikanten p-Werte (p < .05). Das Signifikanzniveau des Vergleichs, in dem
es zu einer schnelleren Reaktion kam, wenn einem Pseudo-Target ein Pseudo-Pronomen-
Prime vorausging als wenn einem Pseudo-Target ein Pronomen-Prime vorausging, wies eine
Tendenz in Richtung Signifikanz auf, t(30) = -1.78, p = .09, während der andere Vergleich,
nämlich wenn einem Target ein Pronomen-Prime vorausging als wenn einem Target ein
Pseudo-Pronomen-Prime vorausging, keine Signifikanz aufwies, t(30) = -1.03, p = .31.
Demnach wurden Pseudo-Targets, denen Pseudo-Pronomen-Primes vorausgingen mit einer
842 852
760
780
800
820
840
860
880
900
920
Singular Plural
Re
akti
on
sze
it in
ms
Grammatikalische Numeri

SUBLIMINALES SYNTAKTISCHES PRIMING 23
Tendenz in Richtung Signifikanz schneller erkannt als Pseudo-Targets, denen Pronomen-
Primes vorausgingen. Targets, denen Pronomen-Primes vorausgingen, zeigten im Vergleich
zu Targets, denen Pseudo-Pronomen-Primes vorausgingen, keine signifikanten
Reaktionszeitunterschiede (siehe Abbildung 7).
Abbildung 7. Durchschnittliche Reaktionszeiten (in ms) der signifikanten
Interaktion zwischen Zielreizwort und Primereiz. Pseudo-Targets, denen
Pseudo-Pronomen-Primes vorausgingen, wurden mit einer Tendenz in
Richtung Signifikanz schneller erkannt als Pseudo-Targets, denen
Pronomen-Primes vorausgingen. Targets, denen Pronomen-Primes
vorausgingen, zeigten im Vergleich zu Targets, denen Pseudo-Pronomen-
Primes vorausgingen, keine signifikanten Reaktionszeitunterschiede.
Eine weitere signifikante Zweifach-Interaktion ergab sich für die Variablen
Zielreizwort und grammatikalische Numeri, F(1, 30) = 20.70, p < .01, ηp² = .41. In einem
anschließenden Post-hoc-Test wurde ein t-Test nach Bonferroni durchgeführt, der zeigte, dass
dieser signifikante Effekt darauf beruhte, dass Reaktionen signifikant schneller waren, wenn
Pseudo-Targets im Singular gezeigt wurden (RZ = 883 ms) als wenn Pseudo-Targets im
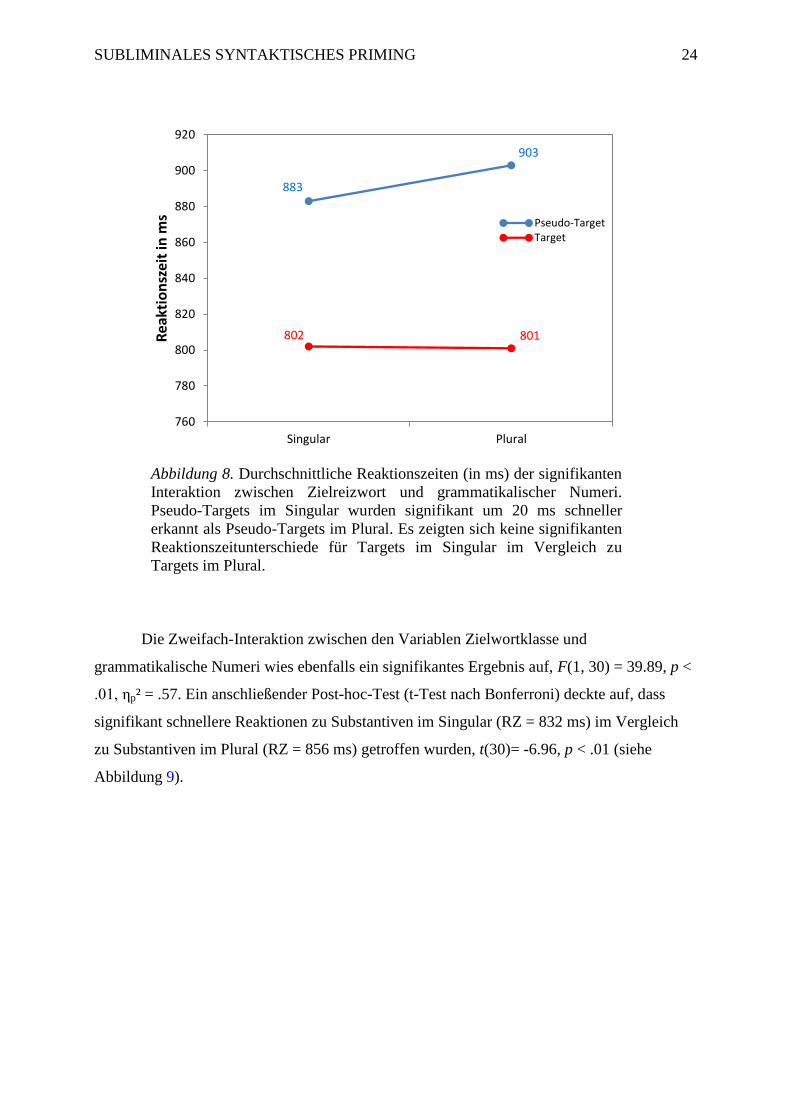
Plural gezeigt wurden (RZ = 903 ms), t(30)= -5.93, p < .01 (siehe Abbildung 8).
891 895
803 800
760
780
800
820
840
860
880
900
920
Pseudo-Pronomen-Primes Pronomen-Primes
Rea
ktio
nsz
eit
in m
s
Pseudo-Target Target
SUBLIMINALES SYNTAKTISCHES PRIMING 24
Abbildung 8. Durchschnittliche Reaktionszeiten (in ms) der signifikanten
Interaktion zwischen Zielreizwort und grammatikalischer Numeri.
Pseudo-Targets im Singular wurden signifikant um 20 ms schneller
erkannt als Pseudo-Targets im Plural. Es zeigten sich keine signifikanten
Reaktionszeitunterschiede für Targets im Singular im Vergleich zu
Targets im Plural.
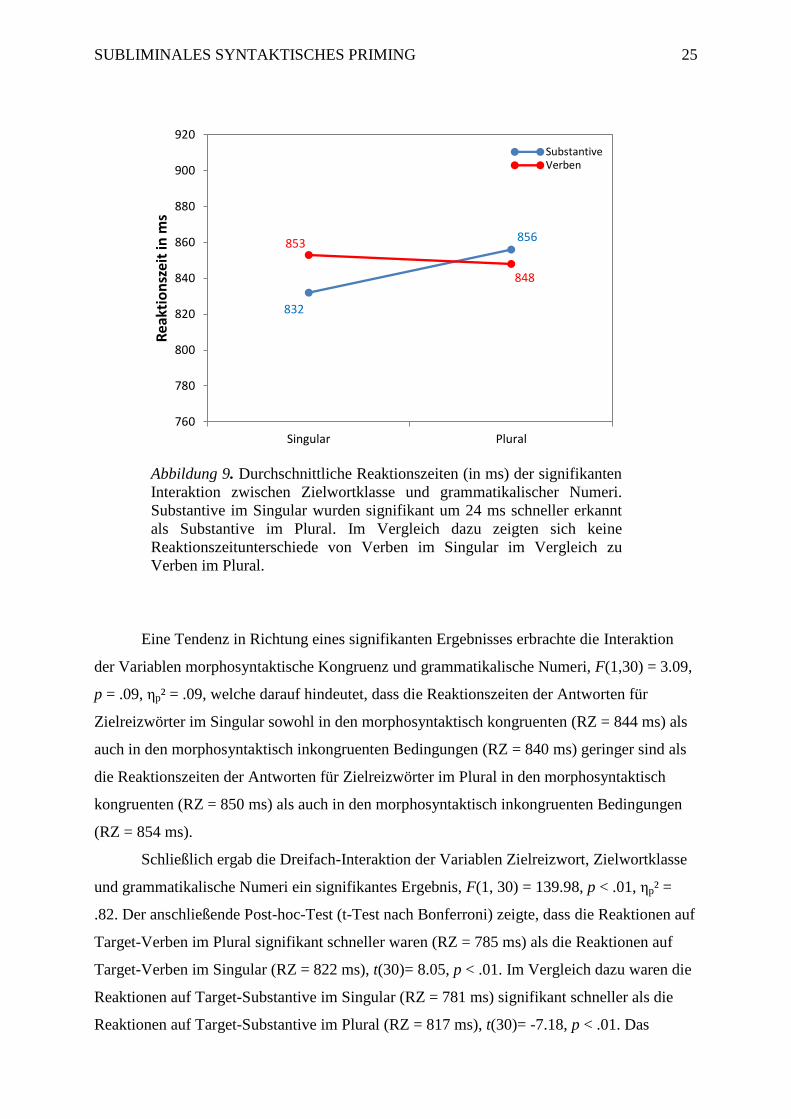
Die Zweifach-Interaktion zwischen den Variablen Zielwortklasse und
grammatikalische Numeri wies ebenfalls ein signifikantes Ergebnis auf, F(1, 30) = 39.89, p <
.01, ηp² = .57. Ein anschließender Post-hoc-Test (t-Test nach Bonferroni) deckte auf, dass
signifikant schnellere Reaktionen zu Substantiven im Singular (RZ = 832 ms) im Vergleich
zu Substantiven im Plural (RZ = 856 ms) getroffen wurden, t(30)= -6.96, p < .01 (siehe
Abbildung 9).
883
903
802 801
760
780
800
820
840
860
880
900
920
Singular Plural
Rea
ktio
nsz
eit
in m
s Pseudo-Target Target
SUBLIMINALES SYNTAKTISCHES PRIMING 25
Abbildung 9. Durchschnittliche Reaktionszeiten (in ms) der signifikanten
Interaktion zwischen Zielwortklasse und grammatikalischer Numeri.
Substantive im Singular wurden signifikant um 24 ms schneller erkannt
als Substantive im Plural. Im Vergleich dazu zeigten sich keine
Reaktionszeitunterschiede von Verben im Singular im Vergleich zu
Verben im Plural.
Eine Tendenz in Richtung eines signifikanten Ergebnisses erbrachte die Interaktion
der Variablen morphosyntaktische Kongruenz und grammatikalische Numeri, F(1,30) = 3.09,
p = .09, ηp² = .09, welche darauf hindeutet, dass die Reaktionszeiten der Antworten für
Zielreizwörter im Singular sowohl in den morphosyntaktisch kongruenten (RZ = 844 ms) als
auch in den morphosyntaktisch inkongruenten Bedingungen (RZ = 840 ms) geringer sind als
die Reaktionszeiten der Antworten für Zielreizwörter im Plural in den morphosyntaktisch
kongruenten (RZ = 850 ms) als auch in den morphosyntaktisch inkongruenten Bedingungen
(RZ = 854 ms).
Schließlich ergab die Dreifach-Interaktion der Variablen Zielreizwort, Zielwortklasse
und grammatikalische Numeri ein signifikantes Ergebnis, F(1, 30) = 139.98, p < .01, ηp² =
.82. Der anschließende Post-hoc-Test (t-Test nach Bonferroni) zeigte, dass die Reaktionen auf
Target-Verben im Plural signifikant schneller waren (RZ = 785 ms) als die Reaktionen auf
Target-Verben im Singular (RZ = 822 ms), t(30)= 8.05, p < .01. Im Vergleich dazu waren die
Reaktionen auf Target-Substantive im Singular (RZ = 781 ms) signifikant schneller als die
Reaktionen auf Target-Substantive im Plural (RZ = 817 ms), t(30)= -7.18, p < .01. Das
832
856 853
848
760
780
800
820
840
860
880
900
920
Singular Plural
Rea
ktio
nsz
eit
in m
s Substantive Verben

SUBLIMINALES SYNTAKTISCHES PRIMING 26
Ergebnis der Dreifach-Interaktion zeigte außerdem, dass Pseudo-Target-Verben im Singular
signifikant schneller erkannt wurden (RZ = 883 ms) als Pseudo-Target-Verben im Plural (RZ
= 911 ms), t(30)= -6.66, p < .01, und dass Pseudo-Target-Substantive ebenfalls im Singular
(RZ = 883 ms) signifikant schneller erkannt wurden als Pseudo-Target-Substantive im Plural
(RZ = 895 ms), t(30)= -3.29, p < .01 (siehe Abbildung 10).
Abbildung 10. Durchschnittliche Reaktionszeiten (in ms) der signifikanten
Interaktion zwischen Zielreizwort, Zielwortklasse und grammatikalische
Numeri. Target-Substantive, Pseudo-Target-Substantive und Pseudo-Target-
Verben wurden signifikant schneller in ihrer Singularform als in ihrer
Pluralform erkannt, während Target-Verben in ihrer Pluralform signifikant
schneller als in ihrer Singularform erkannt wurden.
Es ergaben sich keine signifikanten Haupteffekte für die Variablen
morphosyntaktische Kongruenz und Primereiz, beide Fs < .21, beide ps > .65, und alle
weiteren Interaktionen ergaben ebenfalls keine signifikanten Ergebnisse, Fs < 2.77, ps > .11.
781
817
822
785
883
895 883
911
760
780
800
820
840
860
880
900
920
Singular Plural
Rea
ktio
nsz
eit
in m
s Target-Substantive
Target-Verben
Pseudo-Target-Substantive
Pseudo-Target-Verben

SUBLIMINALES SYNTAKTISCHES PRIMING 27
3.02 Analyse der Fehlerraten
Neben den Reaktionszeiten wurde auch die Korrektheit der Antworten gemessen.
Fehlerraten (FR) geben Aufschluss über die prozentuell inkorrekt gegebenen Antworten. Die
arkussinus transformierten Fehlerraten wurden mittels einer fünffaktoriellen Varianzanalyse
(ANOVA) mit den fünf Variablen Zielreizwort (Target vs. Pseudo-Target), grammatikalische
Numeri (Singular vs. Plural), morphosyntaktische Kongruenz (Kongruenz vs. Inkongruenz),
Zielwortklasse (Verb vs. Substantiv) und Primereiz (Prime vs. Pseudo-Prime) berechnet. In
der Bedingung Zielwortklasse wurden die Verben und Substantive für die Pseudo-
Wortbedingung nachgeahmt. Die fünf Variablen mit je zwei Stufen ergaben somit ein 2 x 2 x
2 x 2 x 2 – Design.
Es ergab sich ein signifikanter Haupteffekt für die Variable Zielwortklasse, F(1, 30) =
4.32, p < .05, ηp² = .13, aus dem hervorging, dass die Versuchspersonen signifikant weniger
Fehler begingen, wenn die Zielreizwörter Substantive waren (FR = 10.0 %) als wenn sie
Verben waren (FR = 11.0 %) (siehe Abbildung 11).
Abbildung 11. Durchschnittliche Fehlerraten (in %) des signifikanten
Haupteffektes der Variable Zielwortklasse. Substantive wurden mit einer
signifikanten, um 1% niedrigeren Fehlerrate erkannt als Verben.
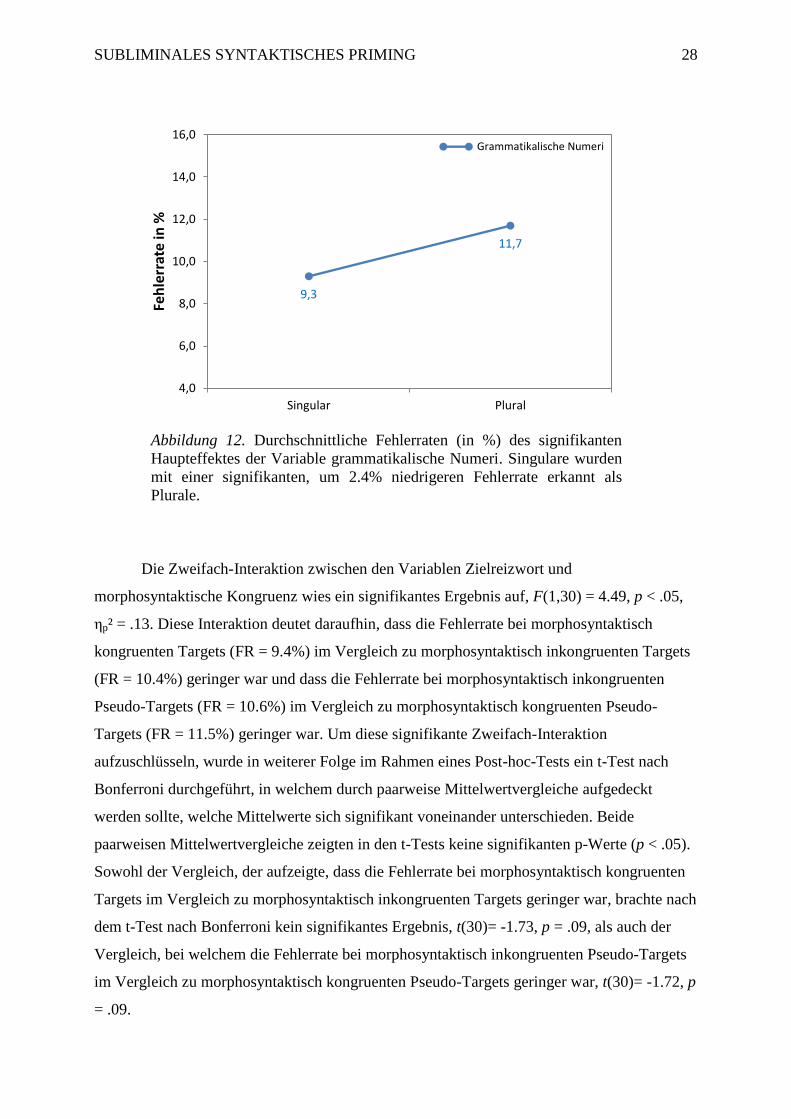
Als ebenfalls signifikant erwies sich der Haupteffekt der Variable grammatikalische
Numeri, F(1,30) = 21.27, p < .01, ηp² = .42. Dieser zeigte, dass die Versuchspersonen eine
signifikant geringere Fehlerrate aufwiesen, wenn Singulare präsentiert wurden (FR = 9.3 %),
als wenn Plurale präsentiert wurden (FR = 11.7%) (siehe Abbildung 12).
10
11
4,0
6,0
8,0
10,0
12,0
14,0
16,0
Substantive Verben
Feh
lerr
ate
in %
Zielwortklasse
SUBLIMINALES SYNTAKTISCHES PRIMING 28
Abbildung 12. Durchschnittliche Fehlerraten (in %) des signifikanten
Haupteffektes der Variable grammatikalische Numeri. Singulare wurden
mit einer signifikanten, um 2.4% niedrigeren Fehlerrate erkannt als
Plurale.
Die Zweifach-Interaktion zwischen den Variablen Zielreizwort und
morphosyntaktische Kongruenz wies ein signifikantes Ergebnis auf, F(1,30) = 4.49, p < .05,
ηp² = .13. Diese Interaktion deutet daraufhin, dass die Fehlerrate bei morphosyntaktisch
kongruenten Targets (FR = 9.4%) im Vergleich zu morphosyntaktisch inkongruenten Targets
(FR = 10.4%) geringer war und dass die Fehlerrate bei morphosyntaktisch inkongruenten
Pseudo-Targets (FR = 10.6%) im Vergleich zu morphosyntaktisch kongruenten Pseudo-
Targets (FR = 11.5%) geringer war. Um diese signifikante Zweifach-Interaktion
aufzuschlüsseln, wurde in weiterer Folge im Rahmen eines Post-hoc-Tests ein t-Test nach
Bonferroni durchgeführt, in welchem durch paarweise Mittelwertvergleiche aufgedeckt
werden sollte, welche Mittelwerte sich signifikant voneinander unterschieden. Beide
paarweisen Mittelwertvergleiche zeigten in den t-Tests keine signifikanten p-Werte (p < .05).
Sowohl der Vergleich, der aufzeigte, dass die Fehlerrate bei morphosyntaktisch kongruenten
Targets im Vergleich zu morphosyntaktisch inkongruenten Targets geringer war, brachte nach
dem t-Test nach Bonferroni kein signifikantes Ergebnis, t(30)= -1.73, p = .09, als auch der
Vergleich, bei welchem die Fehlerrate bei morphosyntaktisch inkongruenten Pseudo-Targets
im Vergleich zu morphosyntaktisch kongruenten Pseudo-Targets geringer war, t(30)= -1.72, p
= .09.
9,3
11,7
4,0
6,0
8,0
10,0
12,0
14,0
16,0
Singular Plural
Feh
lerr
ate
in %
Grammatikalische Numeri

SUBLIMINALES SYNTAKTISCHES PRIMING 29
Beide Vergleiche weisen lediglich eine Tendenz in Richtung Signifikanz auf (siehe
Abbildung 13).
Abbildung 13. Durchschnittliche Fehlerraten (in %) der signifikanten
Interaktion zwischen den Variablen Zielreizwort und morphosyntaktische
Kongruenz. Morphosyntaktisch kongruente Targets wurden mit einer um
1% niedrigeren Fehlerrate erkannt als morphosyntaktisch inkongruenten
Targets während morphosyntaktisch inkongruenten Pseudo-Targets mit
einer um 0.9% niedrigeren Fehlerrate erkannt wurden als
morphosyntaktisch kongruenten Pseudo-Targets. Beide Vergleiche
weisen jedoch lediglich eine Tendenz in Richtung Signifikanz auf.
Eine weiteres signifikantes Ergebnis ergab die Interaktion der Variablen Zielreizwort
und Zielwortklasse, F(1,30) = 17.84, p < .01, ηp² = .37. Der anschließende Post-hoc-Test (t-
Test nach Bonferroni) deckte auf, dass Pseudo-Target-Substantive signifikant weniger Fehler
auslösten (FR = 9.7 %) als Pseudo-Target-Verben (FR = 12.5 %), t(30)= 4.53, p < .01 (siehe
Abbildung 14).
11,5
10,6
9,4
10,4
4,0
6,0
8,0
10,0
12,0
14,0
16,0
Kongruent Inkongruent
Feh
lerr
ate
in %
Pseudo-Target Target

SUBLIMINALES SYNTAKTISCHES PRIMING 30
Abbildung 14. Durchschnittliche Fehlerraten (in %) der signifikanten
Interaktion zwischen den Variablen Zielreizwort und Zielwortklasse.
Pseudo-Target-Substantive wurden mit einer signifikanten, um 2.8%
niedrigeren Fehlerrate erkannt als Pseudo-Target-Verben. Es zeigten sich
keine signifikanten Fehlerratenunterschiede zwischen Target-
Substantiven und Target-Verben.
Die Zweifach-Interaktion der Variablen Zielreizwort und grammatikalische Numeri
ergab ebenfalls ein signifikantes Ergebnis, F(1,30) = 30.69, p < .01, ηp² = .51. Der
anschließende Post-hoc-Test (t-Test nach Bonferroni) deckte auf, dass es zu signifikant
geringeren Fehlerraten führte, wenn Pseudo-Targets im Singular präsentiert wurden (FR = 8.4
%) als wenn Pseudo-Targets im Plural präsentiert wurden (FR = 13.7 %), t(30)= -6.33, p < .01
(siehe Abbildung 15).
9,7
12,5
10,4
9,5
4,0
6,0
8,0
10,0
12,0
14,0
16,0
Substantive Verben
Feh
lerr
ate
in %
Pseudo-Target Target
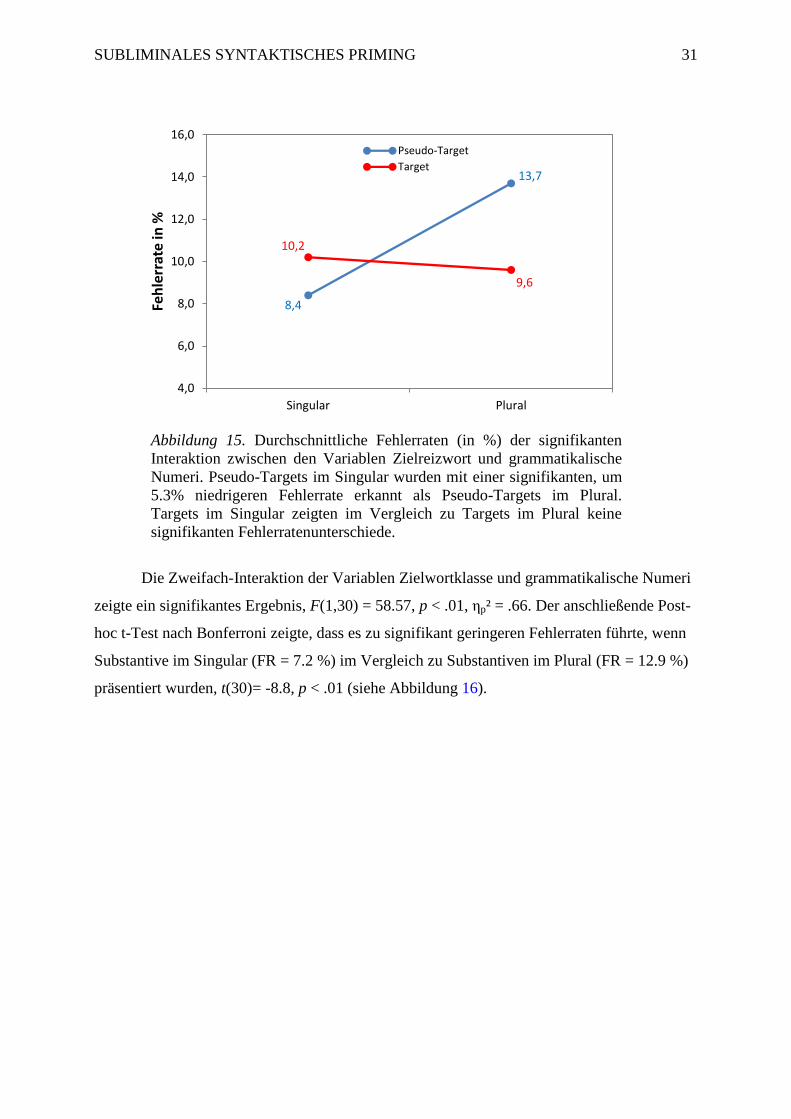
SUBLIMINALES SYNTAKTISCHES PRIMING 31
Abbildung 15. Durchschnittliche Fehlerraten (in %) der signifikanten
Interaktion zwischen den Variablen Zielreizwort und grammatikalische
Numeri. Pseudo-Targets im Singular wurden mit einer signifikanten, um
5.3% niedrigeren Fehlerrate erkannt als Pseudo-Targets im Plural.
Targets im Singular zeigten im Vergleich zu Targets im Plural keine
signifikanten Fehlerratenunterschiede.
Die Zweifach-Interaktion der Variablen Zielwortklasse und grammatikalische Numeri
zeigte ein signifikantes Ergebnis, F(1,30) = 58.57, p < .01, ηp² = .66. Der anschließende Post-
hoc t-Test nach Bonferroni zeigte, dass es zu signifikant geringeren Fehlerraten führte, wenn
Substantive im Singular (FR = 7.2 %) im Vergleich zu Substantiven im Plural (FR = 12.9 %)
präsentiert wurden, t(30)= -8.8, p < .01 (siehe Abbildung 16).
8,4
13,7
10,2
9,6
4,0
6,0
8,0
10,0
12,0
14,0
16,0
Singular Plural
Feh
lerr
ate
in %
Pseudo-Target
Target
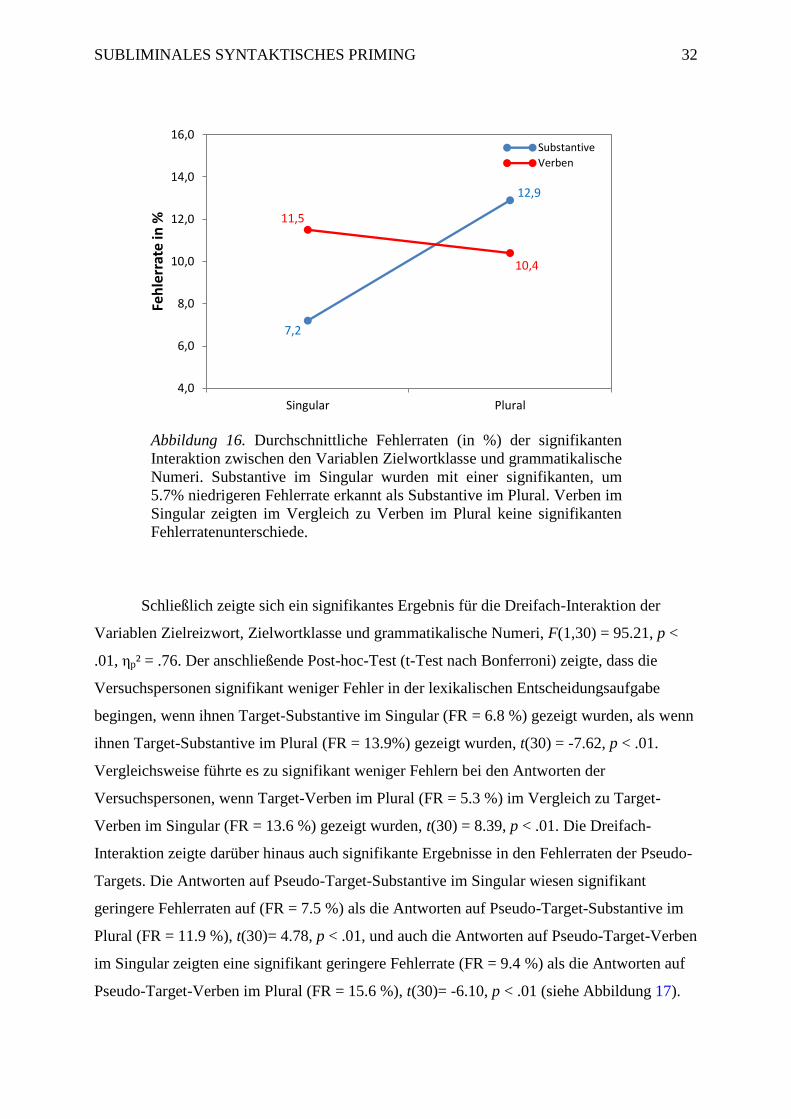
SUBLIMINALES SYNTAKTISCHES PRIMING 32
Abbildung 16. Durchschnittliche Fehlerraten (in %) der signifikanten
Interaktion zwischen den Variablen Zielwortklasse und grammatikalische
Numeri. Substantive im Singular wurden mit einer signifikanten, um
5.7% niedrigeren Fehlerrate erkannt als Substantive im Plural. Verben im
Singular zeigten im Vergleich zu Verben im Plural keine signifikanten
Fehlerratenunterschiede.
Schließlich zeigte sich ein signifikantes Ergebnis für die Dreifach-Interaktion der
Variablen Zielreizwort, Zielwortklasse und grammatikalische Numeri, F(1,30) = 95.21, p <
.01, ηp² = .76. Der anschließende Post-hoc-Test (t-Test nach Bonferroni) zeigte, dass die
Versuchspersonen signifikant weniger Fehler in der lexikalischen Entscheidungsaufgabe
begingen, wenn ihnen Target-Substantive im Singular (FR = 6.8 %) gezeigt wurden, als wenn
ihnen Target-Substantive im Plural (FR = 13.9%) gezeigt wurden, t(30) = -7.62, p < .01.
Vergleichsweise führte es zu signifikant weniger Fehlern bei den Antworten der
Versuchspersonen, wenn Target-Verben im Plural (FR = 5.3 %) im Vergleich zu Target-
Verben im Singular (FR = 13.6 %) gezeigt wurden, t(30) = 8.39, p < .01. Die Dreifach-
Interaktion zeigte darüber hinaus auch signifikante Ergebnisse in den Fehlerraten der Pseudo-
Targets. Die Antworten auf Pseudo-Target-Substantive im Singular wiesen signifikant
geringere Fehlerraten auf (FR = 7.5 %) als die Antworten auf Pseudo-Target-Substantive im
Plural (FR = 11.9 %), t(30)= 4.78, p < .01, und auch die Antworten auf Pseudo-Target-Verben
im Singular zeigten eine signifikant geringere Fehlerrate (FR = 9.4 %) als die Antworten auf
Pseudo-Target-Verben im Plural (FR = 15.6 %), t(30)= -6.10, p < .01 (siehe Abbildung 17).
7,2
12,9
11,5
10,4
4,0
6,0
8,0
10,0
12,0
14,0
16,0
Singular Plural
Feh
lerr
ate
in %
Substantive
Verben
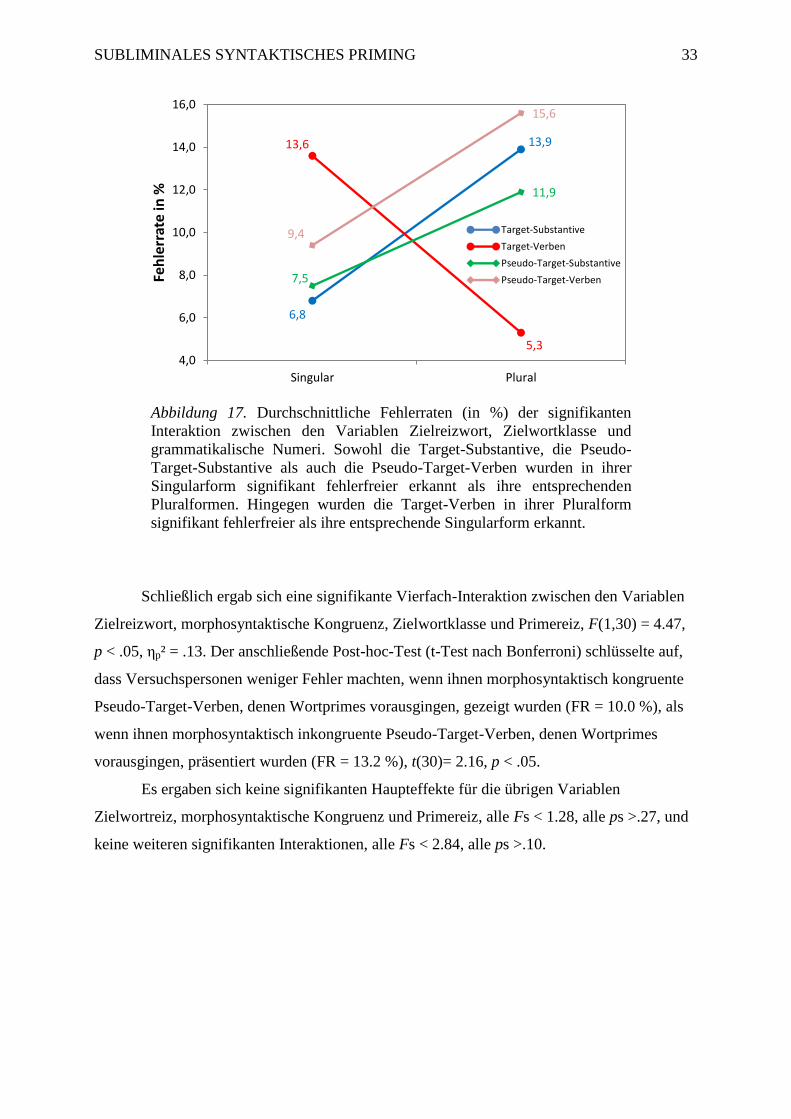
SUBLIMINALES SYNTAKTISCHES PRIMING 33
Abbildung 17. Durchschnittliche Fehlerraten (in %) der signifikanten
Interaktion zwischen den Variablen Zielreizwort, Zielwortklasse und
grammatikalische Numeri. Sowohl die Target-Substantive, die Pseudo-
Target-Substantive als auch die Pseudo-Target-Verben wurden in ihrer
Singularform signifikant fehlerfreier erkannt als ihre entsprechenden
Pluralformen. Hingegen wurden die Target-Verben in ihrer Pluralform
signifikant fehlerfreier als ihre entsprechende Singularform erkannt.
Schließlich ergab sich eine signifikante Vierfach-Interaktion zwischen den Variablen
Zielreizwort, morphosyntaktische Kongruenz, Zielwortklasse und Primereiz, F(1,30) = 4.47,
p < .05, ηp² = .13. Der anschließende Post-hoc-Test (t-Test nach Bonferroni) schlüsselte auf,
dass Versuchspersonen weniger Fehler machten, wenn ihnen morphosyntaktisch kongruente
Pseudo-Target-Verben, denen Wortprimes vorausgingen, gezeigt wurden (FR = 10.0 %), als
wenn ihnen morphosyntaktisch inkongruente Pseudo-Target-Verben, denen Wortprimes
vorausgingen, präsentiert wurden (FR = 13.2 %), t(30)= 2.16, p < .05.
Es ergaben sich keine signifikanten Haupteffekte für die übrigen Variablen
Zielwortreiz, morphosyntaktische Kongruenz und Primereiz, alle Fs < 1.28, alle ps >.27, und
keine weiteren signifikanten Interaktionen, alle Fs < 2.84, alle ps >.10.
6,8
13,9 13,6
5,3
7,5
11,9
9,4
15,6
4,0
6,0
8,0
10,0
12,0
14,0
16,0
Singular Plural
Feh
lerr
ate
in %
Target-Substantive
Target-Verben
Pseudo-Target-Substantive
Pseudo-Target-Verben

SUBLIMINALES SYNTAKTISCHES PRIMING 34
3.03. Primesichtbarkeitsaufgabe
Um die Sichtbarkeit der Primes zu überprüfen, wurde anhand der
Signalentdeckungstheorie das Sensitivitätsmaß d´ (Green & Swets, 1966) berechnet, welches
Aufschluss über die Diskriminationsleistung der Versuchspersonen hinsichtlich der
Pronomen-Primes und der Pseudo-Pronomen-Primes geben sollte. Die Berechnung des
Sensitivitätsmaßes d´ ist eine allgemein übliche Messmethode, um die Primesichtbarkeit zu
überprüfen, da es unabhängig von Urteilstendenzen der Versuchspersonen und unabhängig
von der Wahrscheinlichkeit des Auftretens eines Reizes berechnet wird (vgl. Reingold &
Merikle, 1988, 1990). Hierbei müssen die Versuchspersonen entscheiden, ob ein bestimmtes
Signal vorhanden ist oder nicht. Wenn ein Signal vorhanden ist und die Versuchspersonen
dieses richtigerweise als solches erkennen, wird dies als Treffer gewertet. Wenn kein Signal
vorhanden ist, aber die Versuchspersonen dieses fälschlicherweise als ein solches feststellen,
wird dies als falscher Alarm gewertet. Als korrekte Zurückweisung werden jene Durchgänge
gewertet, bei denen die Versuchspersonen bei keinem vorhandenen Signal auch keines
entdecken und als Verpasser werden jene Durchgänge gezählt, bei denen die
Versuchspersonen trotz vorhandenem Signal dieses nicht entdecken.
In der vorliegenden Studie wurden die Pronomen-Primes als Signale bestimmt. Als
Treffer wurde gewertet, wenn bei Vorhandensein eines Pronomen-Primes (Signal) dieses
korrekterweise von den Versuchspersonen als solches identifiziert wurde. Ein falscher Alarm
lag vor, wenn die Versuchspersonen bei Nichtvorhandensein eines Pronomen-Primes
irrtümlich auf Vorhandensein eines solchen entschieden hatten. Als korrekte Zurückweisung
wurde die Entscheidung gewertet, wenn kein Pronomen-Prime vorhanden war und dieser von
den Versuchspersonen auch nicht als solcher identifiziert wurde. In die Kategorie Verpasser
fielen die Entscheidungen der Versuchspersonen, wenn ein Pronomen-Prime vorhanden war,
aber die Versuchspersonen diesen nicht entdeckten.
Um die individuellen Sensitivitätsmaße d´ der einzelnen Versuchspersonen zu
ermitteln, wurden die jeweiligen Probabilitäten der Treffer und falschen Alarme der
Versuchspersonen herangezogen (vgl. Green & Swets, 1966) und zur Vergleichbarkeit der
Werte einer z-Transformation unterzogen. Anschließend wurde die Differenz dieser Werte
gebildet, indem die z-transformierten falschen Alarme von den z-transformierten Treffern
subtrahiert wurden. Daraus ergab sich für jede Versuchsperson ein individueller Wert d´. Der
Mittelwert dieser Werte wurden berechnet und einem t-Test unterzogen (vgl. Khalid, König &
Ansorge, 2011). Der Wert d´ ergibt Null, wenn es sich um eine Zufallsleistung handelt.
Theoretisch kann der Wert d´ mit zunehmender Diskriminationsleistung unendlich groß

SUBLIMINALES SYNTAKTISCHES PRIMING 35
werden (Khalid et al., 2011). Wenn sich demzufolge der Wert d´ nicht signifikant von Null
unterscheidet, kann angenommen werden, dass sich die Diskriminationsleistung der
Versuchspersonen nicht von einer Zufallsleistung unterscheidet und die Maskierung der
Pronomen-Primes und der Pseudo-Pronomen-Primes erfolgreich war. Ein signifikantes
Ergebnis würde hingegen bedeuten, dass sich die Diskriminationsleistung der
Versuchspersonen von einer Zufallsleistung unterscheidet und die Pronomen-Primes und die
Pseudo-Pronomen-Primes möglicherweise sichtbar waren.
Für die 31 Versuchspersonen konnte ein nicht signifikantes Ergebnis bezüglich der
Diskriminationsleistung nachgewiesen werden, d´ = -0.01, t(30) = -.82, p = .42. Das bestätigt,
dass die Pronomen-Primes und die Pseudo-Pronomen-Primes für die Versuchspersonen nicht
sichtbar waren und die Maskierung somit erfolgreich war.
4. Diskussion
Das Ziel dieser Diplomarbeit war es subliminales syntaktisches Priming zu
untersuchen. Dabei wurde der Einfluss von maskierten Pronomen als Primes (als „Pronomen-
Prime“ bezeichnet) auf die Erkennung von sichtbaren Verben im Vergleich zu sichtbaren
Substantiven als Targets untersucht. Mit Hilfe von lexikalischen Entscheidungsaufgaben
wurde untersucht, ob Verben (als „Target-Verben“ bezeichnet) im Vergleich zu Substantiven
(als „Target-Substantive“ bezeichnet) schneller erkannt wurden, wenn ihnen unbewusst
wahrnehmbare Pronomen-Primes vorausgingen.
Da für die lexikalische Entscheidungsaufgabe neben echten Wörtern auch Pseudo-
Wörter benötigt wurden, wurden sowohl Pseudo-Wörter für die Verben (als „Pseudo-Target-
Verben“ bezeichnet) als auch Pseudo-Wörter für die Substantive (als „Pseudo-Target-
Substantive“ bezeichnet) entwickelt.
Um die Wirkung der Pronomen-Primes im Rahmen der lexikalischen
Entscheidungsaufgabe klar eruieren zu können, wurden Pseudo-Pronomen-Primes als
Vergleichsmaßstab entwickelt. Die Annahme, dass es zu einer Erleichterung der lexikalischen
Entscheidung führen würde, wenn den Target-Verben Pronomen-Primes vorausgehen und es
zu keiner Erleichterung der lexikalischen Entscheidung führen würde, wenn den Target-
Verben Pseudo-Pronomen-Primes vorausgehen, trat nicht ein. Es wurde kein subliminaler
syntaktischer Priming-Effekt nachgewiesen.
Ebenso trat die Annahme, dass lexikalische Entscheidungen unter morphosyntaktisch
kongruenten Bedingungen als auch unter morphosyntaktisch inkongruenten Bedingungen im
Vergleich zu syntaktisch inkongruenten Bedingungen schneller und mit weniger Fehlern

SUBLIMINALES SYNTAKTISCHES PRIMING 36
erfolgen würden, nicht ein. Es zeigte sich dementsprechend auch kein morphosyntaktischer
Priming-Effekt. Es traten jedoch andere signifikante Ergebnisse ein, die im Folgenden näher
diskutiert werden.
Der Haupteffekt der Variable Zielreizwort (Wörter vs. Pseudo-Wörter) zeigte, dass
echte Wörter im Vergleich zu Pseudo-Wörtern generell schneller erkannt wurden. Dieses
Ergebnis kann möglicherweise auf die Vertrautheit der echten Wörter im Vergleich zu den
Pseudo-Wörtern zurückgeführt werden. Die Vertrautheit eines Wortes (engl. „word
familiarity“) ist die relative Leichtigkeit der Wahrnehmung dieses Wortes (Tanaka-Ishii &
Terada, 2011). Beispielsweise können die beiden Wörter „meeting“ (dt. „Treffen“) und
„encounter“ (dt. „Treffen“) im selben Kontext verwendet werden, aber das Wort „meeting“
wird laut Tanaka-Ishii und Terada (2011) kognitiv leichter wahrgenommen als das Wort
„encounter“.
Connine, Mullenix, Shernoff und Yelen (1990) haben gezeigt, dass die Vertrautheit
von Wörtern auch eine Rolle bei lexikalischen Entscheidungsaufgaben spielen kann. Sie
haben in einem Experiment untersucht, ob die Vertrautheit eines Wortes Einfluss auf die
Reaktionsgeschwindigkeit und die Genauigkeit der Antworten in einer lexikalischen
Entscheidungsaufgabe hat. Für das Experiment wurden Wörter ausgewählt, welchen
Bewertungen bezüglich ihrer Vertrautheit zugewiesen wurden. Connine et al. (1990) teilten in
ihrer Studie die Wörter bezüglich ihrer Vertrautheit in vier Kategorien von „am wenigsten
vertraute“ bis zu „sehr vertraute“ Wörter ein. Die Versuchspersonen mussten in einer
lexikalischen Entscheidungsaufgabe beurteilen, ob es sich bei den auf einem
Computerbildschirm präsentierten Reizen um Wörter oder Pseudo-Wörter handelte. Es stellte
sich heraus, dass die Reaktionsgeschwindigkeit abnahm und die Genauigkeit der Antworten
zunahm, je vertrauter die Wörter den Versuchspersonen waren. Hieraus schlossen Connine et
al. (1990), dass Wörter, die stärker vertraut sind, in lexikalischen Entscheidungsaufgaben
schneller erkannt werden, als Wörter, die weniger vertraut sind. Das Ergebnis der Studie von
Connine et al. (1990) könnte einen Erklärungsansatz für das Ergebnis der vorliegenden Studie
bieten, nämlich dass den Versuchspersonen die verwendeten Pseudo-Wörter im Vergleich zu
den echten Wörtern unvertraut erschienen und es dadurch in den lexikalischen
Entscheidungsaufgaben zu signifikant längeren Reaktionszeiten bei den Pseudo-Wörtern kam.
Abgesehen von dem Kriterium der Vertrautheit von Wörtern, gibt es noch das
Kriterium der Häufigkeit (engl. „frequency“) von Wörtern im Sprachgebrauch. Wörter, die
häufig im Sprachgebrach vorkommen, werden schneller erkannt als Wörter, die selten im
Sprachgebrauch vorkommen (vgl. Balota & Chumbley, 1984). Wörter, die häufig im

SUBLIMINALES SYNTAKTISCHES PRIMING 37
Sprachgebrauch vorkommen, werden als hochfrequent bezeichnet während Wörter, die selten
im Sprachgebrauch vorkommen, als niederfrequent bezeichnet werden (Schilling, Rayner &
Chumbley, 1998). Balota und Chumbley (1984) haben in ihrer Studie erklärt, dass
Versuchspersonen in lexikalischen Entscheidungsaufgaben im Grunde zwischen echten
Wörtern, die eine Bedeutung haben, und unbekannten Aneinanderreihungen von Buchstaben,
die keine Bedeutung haben, unterscheiden müssen. Diese Unterscheidung wird laut Balota
und Chumbley (1984) durch zwei Kriterien maßgeblich beeinflusst: Erstens, wie oft die
Versuchsperson ein Wort gesehen hat und zweitens, die Bedeutung des Wortes. Es ist somit
leichter, vertraute oder bedeutungsvolle Wörter, die man öfter gesehen hat, abzurufen als
Wörter, die weniger vertraut oder gar unbekannt sind (vgl. Balota & Chumbley, 1984). In der
vorliegenden Studie wurden die Pseudo-Wörter von echten Wörtern abgeleitet, verfügten über
eine wortähnliche Form und waren aussprechbar. Dadurch, dass es diese Wörter in der
deutschen Sprache aber nicht gab, konnten sie den Versuchspersonen auch nicht geläufig
gewesen sein. Pseudo-Wörter ähneln in ihrem Maß der Vertrautheit stärker echten Wörtern,
die man selten gesehen hat, als echten Wörtern, die man oft gesehen hat (Balota & Chumbley,
1984). In der vorliegenden Studie erschienen die Pseudo-Wörter vermutlich auf den ersten
Blick ungewöhnlich und die Versuchspersonen mussten mehr Zeit in Anspruch nehmen, um
zu entscheiden, ob es sich um ein Pseudo-Wort oder um ein ihnen unbekanntes echtes Wort
handelte. Wörter, die selten im Sprachgebrauch vorkommen, sind schwerer von Pseudo-
Wörtern zu unterscheiden als Wörter, die häufig im Sprachgebrauch vorkommen (vgl. Balota
& Chumbley, 1984). Dies könnte dazu geführt haben, dass in der vorliegenden Studie die
lexikalischen Entscheidungen bei Pseudo-Wörtern im Vergleich zu echten Wörtern
durchschnittlich signifikant langsamer ausfielen.
Der Haupteffekt grammatikalische Numeri (Singular vs. Plural) zeigte, dass
Singularformen signifikant schneller und mit signifikant weniger Fehlern erkannt wurden als
Pluralformen. Es wurden keine signifikanten Unterschiede zwischen Singular- und
Pluralformen erwartet. Bei diesem signifikanten Ergebnis ist darauf zu achten, dass die
Ergebnisse sowohl echte Target-Verben und Target-Substantive als auch Pseudo-Target-
Verben und Pseudo-Target-Substantive beinhalteten.
Die entsprechende Zweifach-Interaktion Zielreizwort (Wörter vs. Pseudo-Wörter) und
grammatikalische Numeri (Singular vs. Plural) zeigte, dass Pseudo-Targets im Singular
signifikant schneller und mit signifikant weniger Fehlern erkannt wurden als Pseudo-Targets
im Plural. Zwischen den Pseudo-Target-Verben und den Pseudo-Target-Substantiven wurden
keine signifikanten Reaktionszeiten- und Fehlerratenunterschiede erwartet. Die gewählten

SUBLIMINALES SYNTAKTISCHES PRIMING 38
Pseudo-Target-Verben wurden von den Target-Verben abgeleitet (z.B. „BLUTEN“ wurde zu
„BLATEN“) und die gewählten Pseudo-Target-Substantive wurden von den Target-
Substantiven abgeleitet (z.B. „DORF“ wurde zu „DOFF“). Möglicherweise hatten die
Wortformen der Pseudo-Targets im Singular insgesamt einen Vorteil gegenüber den
Wortformen der Pseudo-Targets im Plural. Dies könnte mit der Wortlänge der Pseudo-Wörter
in Verbindung stehen.
Wortlängen werden entweder orthografisch durch die Buchstabenanzahl oder
phonologisch durch die Silbenanzahl eines Wortes berechnet (New, Ferrand, Pallier &
Brysbaert, 2006). In der vorliegenden Studie wurde die Wortlänge orthografisch durch die
Buchstabenanzahl berechnet. Es wurde für jede Wortliste (Singularformen und Pluralformen
getrennt) eine durchschnittliche Wortlänge berechnet. Siehe hierzu Appendix A für Verben
im Singular sowie im Plural, Appendix B für Pseudo-Verben im Singular sowie im Plural,
Appendix C für Substantive im Singular sowie im Plural und Appendix D für Pseudo-
Substantive im Singular sowie im Plural. Es ergab sich für Pseudo-Target-Verben im Singular
eine durchschnittliche Wortlänge von 5,18 Buchstaben pro Wort, welche damit kürzer waren
als Pseudo-Target-Verben im Plural, die eine durchschnittliche Wortlänge von 6 Buchstaben
pro Wort aufwiesen (siehe Appendix B). Auch Pseudo-Target-Substantive im Singular hatten
eine durchschnittlich kürzere Wortlänge von 4,85 Buchstaben pro Wort als Pseudo-Target-
Substantive im Plural, die über 5,88 Buchstaben pro Wort verfügten (siehe Appendix D).
Möglicherweise hat die kürzere Wortlänge zu einer schnelleren und fehlerfreieren
Verarbeitung der Pseudo-Targets im Singular im Vergleich zu der Verarbeitung der Pseudo-
Targets im Plural geführt.
Balota, Cortese, Sergent-Marshall, Spieler und Yap (2004) zeigten, dass kürzere
Wortlängen zu einer schnelleren lexikalischen Entscheidung bei Pseudo-Wörtern führen
können. Sie untersuchten in ihrer Studie unter anderem den Einfluss von lexikalischen
Variablen, darunter auch die Länge von Wörtern, und deren Auswirkung auf die
Reaktionsgeschwindigkeit und die Genauigkeit der lexikalischen Entscheidung. Dabei stellten
sie fest, dass bei Pseudo-Wörtern unter anderem die Wortlänge eine starke
Vorhersagevariable für das Abschneiden in lexikalischen Entscheidungen war. Es zeigte sich
in der Studie von Balota et al. (2004), dass die lexikalischen Entscheidungen insbesondere bei
langen Pseudo-Wörtern vergleichsweise langsamer und weniger genau ausfielen. Dieses
Ergebnis der Studie von Balota et al. (2004) kann als Erklärungsansatz für dieses Ergebnis der
vorliegenden Studie herangezogen werden.

SUBLIMINALES SYNTAKTISCHES PRIMING 39
Der Haupteffekt der Variable Zielwortklasse (Substantive vs. Verben) zeigte, dass
Substantive signifikant schneller und mit signifikant weniger Fehlern erkannt wurden als
Verben. Dieser Haupteffekt ist entgegengesetzt zu den genannten Erwartungen, da aufgrund
syntaktischer Kongruenz ursprünglich kürzere Reaktionszeiten und geringere Fehlerraten für
die Verben im Vergleich zu den Substantiven angenommen wurden. Da hier jedoch noch
keine Unterteilung in echte Wörter und Pseudo-Wörter vorgenommen wurde, umfasst die
Kategorie Substantive in diesem Fall Target-Substantive als auch Pseudo-Target-Substantive
und die Kategorie Verben Target-Verben als auch Pseudo-Target-Verben. Es zeigte sich in
der Zweifach-Interaktion Zielwortklasse (Substantive vs. Verben) und grammatikalische
Numeri (Singular vs. Plural), dass Substantive im Singular signifikant schneller und mit
signifikant weniger Fehlern erkannt wurden im Vergleich zu Substantiven im Plural. Bei
diesem signifikanten Ergebnis ist jedoch ebenfalls darauf zu achten, dass die Kategorie
Substantive sowohl Target-Substantive als auch die kategorisierten Pseudo-Target-
Substantive beinhaltete. Wie die entsprechende Dreifach-Interaktion der Variablen
Zielreizwort (Wörter vs. Pseudo-Wörter), Zielwortklasse (Substantive vs. Verben) und
grammatikalische Numeri (Singular vs. Plural) letztlich verdeutlichte, wurden Target-
Substantive, Pseudo-Target-Substantive und Pseudo-Target-Verben in ihrer Singularform
signifikant schneller und mit signifikant weniger Fehlern erkannt als in ihrer entsprechenden
Pluralform. Ausschließlich Target-Verben wurden in ihrer Pluralform signifikant schneller
und mit signifikant weniger Fehlern erkannt als in ihrer entsprechenden Singularform. Wie in
der Zweifach-Interaktion Zielreizwort und grammatikalische Numeri kann auch dieses
Ergebnis möglicherweise auf die Wortlänge zurückgeführt werden. Die Tatsache, dass
Target-Substantive im Singular durchschnittlich über 5 Buchstaben pro Wort und Target-
Substantive im Plural durchschnittlich über 5,9 Buchstaben pro Wort verfügten (siehe
Appendix C), bestätigt diese Annahme. Die Erklärung der Wortlänge gilt allerdings nicht für
die Verben, in deren Fall es sich andersherum verhielt. Target-Verben im Singular verfügten
durchschnittlich über 5,41 Buchstaben pro Wort, während Target-Verben im Plural
durchschnittlich über 6,46 Buchstaben pro Wort verfügten (siehe Appendix A). Dennoch
wurden Target-Verben in ihrer Pluralform signifikant schneller und mit signifikant weniger
Fehlern als in ihre Singularform erkannt. Eine mögliche Erklärung hierfür könnte sein, dass
die Pluralformen der Verben fast immer der Infinitivformen der Verben entsprachen. In der
Wortliste in Appendix A gab es in 68 Fällen nur ein Verb bei dem dies nicht der Fall war
(„sein“ ≠ „sind“). Man könnte hieraus einen Vorteil für die Form der Verben ableiten, die
dem Infinitiv der Verben entsprachen. Diese Erklärung könnte ebenso für den Vorteil der

SUBLIMINALES SYNTAKTISCHES PRIMING 40
Singularformen der Substantive herangezogen werden, da diese in ihrer Singularform dem
Nominativ des jeweiligen Substantivs entsprachen. Somit kann festgehalten werden, dass
sowohl Substantive als auch Verben in der Form, die ihrer Grundform entsprach, signifikant
schneller und mit signifikant weniger Fehlern erkannt wurden als in der Form, die nicht ihrer
Grundform entsprach.
Der Vorteil der Singularformen der Substantive sowie der Vorteil der Verben in den
Pluralformen könnten auch mit den Häufigkeiten der Wörter im Sprachgebrauch in
Verbindung gebracht werden. Balota und Chumbley (1984) haben gezeigt, dass das
Identifizieren von Wörtern mit ihrer Häufigkeit im Sprachgebrauch in der Hinsicht verknüpft
ist, dass hochfrequente Wörter schneller und mit weniger Fehlern erkannt werden als
niederfrequente Wörter. Um die Häufigkeitswerte der in der vorliegenden Studie verwendeten
Wörter miteinander vergleichen zu können, wurden die Häufigkeiten der verwendeten Verben
im Singular, Verben im Plural, Verben in der Infinitivform, Substantive im Singular und
Substantive im Plural von der Webseite „Projekt Deutscher Wortschatz“ (2014) entnommen
und zur Berechnung der Durchschnitte der jeweiligen Wortlisten herangezogen. Wie in
Appendix A zu sehen ist, betrug die durchschnittliche Häufigkeit der Target-Verben in ihrer
Infinitivform als auch der Verben in der Pluralform 10.084,34 und die durchschnittliche
Häufigkeit der Verben in der Singularform 6.891,74. Somit war die durchschnittliche
Häufigkeit der Verben in der Pluralform 1,46-mal höher als die durchschnittliche Häufigkeit
der Verben in der Singularform. Wie in Appendix C zu sehen ist, betrug die durchschnittliche
Häufigkeit der Substantive in der Singularform 6.540,14 und die durchschnittliche Häufigkeit
der Substantive in der Pluralform 2.433,19. Somit war die durchschnittliche Häufigkeit der
Substantive in der Singularform 2,69-mal höher als die durchschnittliche Häufigkeit der
Substantive in der Pluralform.
Es muss allerdings beachtet werden, dass auf der Webseite „Projekt Deutscher
Wortschatz“ (2014) nicht zu allen Wörtern aus den Wortlisten in Appendix A und C
Häufigkeitswerte angezeigt wurden. Für sehr häufige Wörter wie beispielsweise „machen“
erschienen keine Häufigkeitswerte auf der besagten Internetseite und seltene Wörter wie
beispielsweise „juchzen“ wurden gar nicht angezeigt. Zu den 68 Substantiven im Singular gab
es zu 63 eine Häufigkeitsangabe, zu den 68 Substantiven im Plural gab es zu 59 eine
Häufigkeitsangabe, zu den Verben im Plural gab es zu 59 eine Häufigkeitsangabe und zu den
Verben im Singular gab es nur zu 23 eine Häufigkeitsangabe. Die Durchschnittswerte wurden
entsprechend nur mit den zur Verfügung stehenden Häufigkeitswerten berechnet.

SUBLIMINALES SYNTAKTISCHES PRIMING 41
Man kann somit ebenfalls festhalten, dass in der vorliegenden Studie die Wörter, die
höhere Häufigkeitswerte aufwiesen, signifikant schneller und mit signifikant weniger Fehlern
erkannt wurden. Möglicherweise hatten die soeben genannten Häufigkeitswerte einen
Einfluss auf die Reaktionszeiten und die Fehlerraten in den lexikalischen Entscheidungen der
Versuchspersonen.
Balota et al. (2004) haben in ihrer Studie ebenfalls gezeigt, dass es in lexikalischen
Entscheidungsaufgaben eine Interaktion zwischen den Variablen Wortlänge und Häufigkeit
gab. Mit der Zunahme der Häufigkeit der Wörter nahm der hemmende Effekt der Wortlänge
ab (Balota et al., 2004). Dies bedeutet, dass Versuchspersonen bei der Erkennung von
Wörtern, die niederfrequent waren, durch deren Wortlänge in ihrer Reaktionszeit und
Fehlerrate stärker beeinflusst wurden als bei Wörtern, die hochfrequent waren. Je häufiger ein
Wort im Sprachgebraucht vorkam, desto geringer war der Effekt der Wortlänge auf die
Erkennung des besagten Wortes in lexikalischen Entscheidungsaufgaben (vgl. Balota et al.,
2004). Dies trifft auch bei der vorliegenden Studie zu. Der Effekt der Wortlänge wurde bei
Substantiven, Pseudo-Verben und Pseudo-Substantiven beobachtet, jedoch nicht bei Verben.
Verben hatten eine durchschnittliche Häufigkeit von 9.188,85, während Substantive eine
durchschnittliche Häufigkeit von 4.553,99 hatten. Diese Durchschnittswerte wurden durch
Addition sämtlicher Häufigkeitswerte der Verben sowie durch Addition sämtlicher
Häufigkeitswerte der Substantive und durch Division durch deren jeweilige Anzahl ermittelt.
Demnach war die durchschnittliche Häufigkeit von Verben 2,02-mal so hoch wie die
durchschnittliche Häufigkeit von Substantiven. Vermutlich war der Effekt der Wortlänge nach
Balota et al. (2004) bei den Verben verglichen mit den Substantiven, Pseudo-Verben und
Pseudo-Substantiven geringer, während die höhere Häufigkeit der Verben im Sprachgebrauch
eine größere Rolle bei der lexikalischen Entscheidung spielte und zu kürzeren Reaktionszeiten
und geringeren Fehlerraten führte. Da Pseudo-Verben und Pseudo-Substantive keine echten
Wörter sind, haben sie auch keine Häufigkeitswerte. Sie wurden daher vermutlich ähnlich wie
niederfrequente Wörter stärker durch die Wortlänge beeinflusst (vgl. Balota et al., 2004).
Dieses Ergebnis der vorliegenden Studie könnte somit entsprechend der von Balota et al.
(2004) beschriebenen Interaktion zwischen Wortlänge und Häufigkeit begründet werden.
Ebenfalls könnte die Darstellung der Targets mit Umlauten (Ä, Ö, Ü) eine
Auswirkung auf deren Erkennung gehabt haben. In der vorliegenden Studie wurden die
Umlaute der Targets immer als Vokale mit einem nachgestellten „E“ dargestellt (z.B. „AE“
statt „Ä“). Diese Art der Präsentation wurde gewählt, da die Maske aus zehn zufällig
gewählten Großbuchstaben (z.B. „BAEAFGIHLT“) (siehe Kapitel 2.04

SUBLIMINALES SYNTAKTISCHES PRIMING 42
Untersuchungsdesign) bestand, aber keine Umlaute mit Tremata (Ä; Ö; Ü) beinhaltete. Es
konnte nicht davon ausgegangen werden, dass die Targets mit Umlauten ausreichend hätten
maskiert werden können, da sich die Tremata der Vokale über den jeweiligen Großbuchstaben
befunden hätten, wie zum Beispiel bei den Targets „HÄFEN“ und „FÄRBE“. Da somit die
Tremata nicht von der Maske erfasst worden wären, konnte nicht ausgeschlossen werden,
dass ihre Wahrnehmung möglicherweise einen Hinweis auf ein bestimmtes Wort gegeben
hätte. Daher wurden alle Umlaute (Ä, Ö, Ü) durch den jeweiligen Vokal samt einem
nachgestellten „E“ ersetzt, wie zum Beispiel bei den Targets „HAEFEN“ und „FAERBE“.
Die Darstellung mit Vokalen mit einem nachgestellten „E“ könnte den Versuchspersonen, die
eher eine Darstellung mit Umlauten gewohnt sind, weniger geläufig gewesen sein und dazu
geführt haben, dass Versuchspersonen diese Wörter nicht auf Anhieb als echte Wörter
klassifizieren konnten.
In den Wortlisten der Substantive beinhalteten 4 Substantive im Singular und 18
Substantive im Plural einen Umlaut, während in den Wortlisten der Verben 15 Verben im
Singular sowie 18 Verben im Plural einen Umlaut beinhalteten. Möglicherweise hat diese
ungewohnte Darstellung der Umlaute einen Einfluss auf die lexikalische Entscheidung der
Targets gehabt. Bei den Verben beinhalteten ungefähr gleich viele Verben im Singular und im
Plural Umlaute, während es 4,5-mal so viele Substantive im Plural mit Umlauten als im
Singular mit Umlauten gab. Womöglich hatte diese ungewohnte Darstellung einen Einfluss
auf die Ergebnisse, die ergeben hatten, dass Substantive im Singular schneller erkannt wurden
als Substantive im Plural.
Die Zweifach-Interaktion zwischen den Variablen Zielreizwort (Target vs. Pseudo-
Target) und morphosyntaktische Kongruenz (Kongruenz vs. Inkongruenz) zeigte, dass
Targets in morphosyntaktisch kongruenten Bedingungen mit weniger Fehlern erkannt wurden
als Targets in morphosyntaktisch inkongruenten Bedingungen. Dieser Vergleich wies
allerdings nur eine Tendenz in Richtung Signifikanz auf. Beispielsweise wurde die
Kombination aus Pronomen-Prime und Target-Verb „ich GEHE“ tendenziell mit weniger
Fehlern erkannt als die Kombination aus Pronomen-Prime und Target-Verb „ich GEHEN“. Es
gilt in dieser Zweifach-Interaktion allerdings zu beachten, dass in den echten Wörtern neben
den Verben auch die Substantive enthalten waren und somit nicht nur die morphosyntaktische
Kongruenz für Pronomen und Verben zu diesem Ergebnis geführt hatte, sondern auch die
Übereinstimmung der Ein- bzw. Mehrzahl zwischen Pronomen und Substantiven. Somit
wurde beispielsweise genauso die Kombination aus Pronomen-Prime und Target-Substantiv
„ich HAUS“ tendenziell mit weniger Fehlern erkannt als die Kombination aus Pronomen-

SUBLIMINALES SYNTAKTISCHES PRIMING 43
Prime und Target-Substantiv „ich HAEUSER“. Da in dieser Zweifach-Interaktion des
Weiteren nicht zwischen Pronomen-Primes und Pseudo-Pronomen-Primes unterschieden
wurde, wurde beispielsweise die Kombination aus Pseudo-Pronomen-Prime und Target-Verb
„mek GEHE“ tendenziell mit weniger Fehlern erkannt als die Kombination aus Pseudo-
Pronomen-Prime und Target-Verb „mek GEHEN“. Die Pseudo-Pronomen-Primes wurden,
wie im Kapitel 2.03 Reizmaterial beschrieben, so gewählt, dass sie keinem echten Pronomen
ähneln sollten. Der Pseudo-Pronomen-Prime „mek“ ähnelt optisch durch den „hohen“
Buchstaben an dritter Stelle dem Pronomen-Prime „ich“ und der Pseudo-Pronomen-Prime
„mun“ ähnelt optisch durch den „niedrigen“ Buchstaben an dritter Stelle dem Pronomen-
Prime „wir“. Möglicherweise bestand hierdurch für die Versuchspersonen unter subliminalen
Bedingungen ein höheres Verwechslungsrisiko der jeweiligen Prime-Pendants „ich“ und
„mek“ sowie „wir“ und „mun“. Um herauszufinden, ob diese Tendenz in Richtung
Signifikanz sich auf die Bedingung der Kombination Pronomen-Prime und Target-Verb
bezog, wurden die entsprechenden Dreifach- und Vierfach-Interaktionen näher betrachtet. Die
besagten Dreifach- und Vierfach-Interaktionen zeigten keine signifikanten Ergebnisse, welche
auf einen Vorteil für Targets in der morphosyntaktisch kongruenten Bedingung in der
Verbindung mit Pronomen-Primes gegenüber den restlichen Bedingungen schließen lassen
würden.
Ein weiteres interessantes Ergebnis zeigte die Zweifach-Interaktion der Variablen
Zielreizwort (Target vs. Pseudo-Target) und Primereiz (Pronomen-Prime vs. Pseudo-
Pronomen-Prime). Es gab eine Tendenz in Richtung Signifikanz hinsichtlich der
Reaktionszeit, wenn Pseudo-Pronomen vor Pseudo-Targets präsentiert wurden im Vergleich
dazu, wenn Pronomen-Primes vor Pseudo-Targets gezeigt wurden. Diese Tendenz könnte
möglicherweise mit der sogenannten Reaktionsbahnung (engl. „response priming“) erklärt
werden.
Reaktionsbahnung besagt, dass eine Reaktionsbeschleunigung eintritt, wenn einem
Target ein Prime vorausgeht, der dieselbe Reaktion erfordert wie das Target (vgl. Klotz &
Neumann, 1999). In diesem Fall spricht man von einer reaktionskongruenten Bedingung. Es
tritt ebenso eine Reaktionshemmung ein, wenn einem Target ein Prime vorausgeht, der eine
andere Reaktion erfordert als das Target. In diesem Fall spricht man von einer
reaktionsinkongruenten Bedingung. Konkret bedeutet dies, dass die Reaktion auf ein Target
schneller erfolgt, wenn diesem ein Prime vorausgeht, der reaktionskongruent ist und dass die
Reaktion auf ein Target langsamer erfolgt, wenn diesem ein Prime vorausgeht, der
reaktionsinkongruent ist (vgl. Klotz & Neumann, 1999, Vorberg, Mattler, Heinecke, Schmidt

SUBLIMINALES SYNTAKTISCHES PRIMING 44
& Schwarzbach, 2003). In der Studie von Klotz und Neumann (1999) wurde dieser Effekt
anhand eines Beispiels wie folgt erklärt: Target C könnte sowohl Target A als auch Target B
zugewiesen werden. Wenn Target A und Target C beispielsweise derselben Reaktion
zugewiesen worden wären, würde ein Prime, der Target C aktivieren soll, die Reaktion auf
Target A beschleunigen und die Reaktion auf Target B hemmen. Wenn Target B und Target
C derselben Reaktion zugeordnet worden wären, würde ein Prime, der Target C aktivieren
soll, die Reaktion auf Target B beschleunigen und die Reaktion auf Target A hemmen (Klotz
& Neumann, 1999).
Klotz und Neumann (1999) führten in ihrer Studie hierzu neun Experimente mit
geometrischen Stimuli durch und konnten nachweisen, dass Reaktionsbahnung auch unter
subliminalen Bedingungen funktioniert. Hierbei wurden den Versuchspersonen je zwei
geometrische Stimuli präsentiert, die entweder aus einem Target und einem Distraktor oder
zwei Distraktoren bestanden. Je ein geometrischer Stimulus war links und ein geometrischer
Stimulus war rechts auf dem Bildschirm positioniert und die Versuchspersonen mussten per
Tastendruck die Seite bestimmen auf der das Target zu sehen war. In kongruenten
Durchgängen, gingen hierbei dem Target ein kleinerer, dem Target ähnelnder geometrischer
Stimulus voraus und dem Distraktor ein kleinerer, dem Distraktor ähnelnder geometrischer
Stimulus voraus. In inkongruenten Bedingungen war diese Anordnung verkehrt herum. Dies
bedeutet, dass dem Target ein kleinerer, dem Distraktor ähnelnder geometrischer Stimulus
vorausging und dem Distraktor ein kleinerer, dem Target ähnelnder geometrischer Stimulus
vorausging. In neutralen Durchgängen gingen sowohl dem Target als auch dem Distraktor
kleinere, dem Distraktor ähnelnde geometrische Stimuli voraus. Klotz und Neumann (1999)
konnten in ihren Experimenten nachweisen, dass es in den kongruenten Bedingungen zu
signifikant geringeren Reaktionszeiten und zu geringeren Fehlerraten kam als in den
inkongruenten und neutralen Bedingungen. Dies sprach dafür, dass Reaktionsbahnung auch
unter subliminalen Bedingungen eintreten kann.
Entsprechend der Studie von Klotz und Neumann (1999) könnte für die vorliegende
Studie angenommen werden, dass die Reaktionen bei Pseudo-Targets mit vorhergehenden
Pseudo-Pronomen-Primes schneller erfolgt sind als in reaktionsinkongruenten Bedingungen.
Reaktionsinkongruente Bedingungen wären in diesem Fall Pronomen-Primes gefolgt von
Pseudo-Targets. Diese Annahme stützt sich auf die Tatsache, dass sowohl Pseudo-Pronomen-
Primes als auch Pseudo-Targets keine echten Wörter waren, mit derselben Reaktion verknüpft
waren und von den Versuchspersonen als in eine Kategorie zugehörig empfunden wurden. In
der vorliegenden Studie musste in der Hälfte der Fälle beispielsweise die Taste #4 gedrückt

SUBLIMINALES SYNTAKTISCHES PRIMING 45
werden, wenn ein Pseudo-Target gezeigt wurde und die Taste #6 gedrückt werden, wenn ein
Target gezeigt wurde. Wenn ein Pseudo-Target präsentiert und zuvor ein subliminaler
Pseudo-Pronomen-Prime gezeigt wurde, würde die Reaktion auf die Taste #6 zu drücken
beschleunigt werden. Wenn jedoch ein Target präsentiert und zuvor ein subliminaler Pseudo-
Pronomen-Prime gezeigt wurde, würde die Reaktion auf die Taste #4 zu drücken gehemmt
werden und dementsprechend langsamer erfolgen. Diese Annahme gilt ebenfalls für die
Pronomen-Primes, die jedoch eine Reaktionsbeschleunigung bei Targets und eine
Reaktionshemmung mit entsprechend langsamerer Reaktion bei Pseudo-Targets auslösen
würden. Dies ist jedoch in der vorliegenden Studie nicht eingetreten. In der vorliegenden
Studie wurde, wie oberhalb erwähnt, eine Tendenz in Richtung Signifikanz bezüglich der
Ergebnisse in der Bedingung gemessen, in der Pseudo-Pronomen-Primes Pseudo-Targets
vorausgingen. Diese Tendenzen der vorliegenden Studie könnten daher mit der
Reaktionsbahnung erklärt werden.
Ein möglicherweise entscheidender Faktor dafür, dass die Annahmen der vorliegenden
Studie nicht bestätigt werden konnten, war möglicherweise die gewählte Aufgabenstellung. In
der vorliegenden Studie ging es in erster Linie um den Vergleich der Reaktionszeiten und
Fehlerraten von Target-Verben und Target-Substantiven, wenn diesen subliminal präsentierte
Pronomen-Primes vorausgingen. Die Fragestellung, die den Versuchspersonen präsentiert
wurde, war jedoch eine lexikalische Entscheidungsaufgabe, die auf die Wahl zwischen Target
und Pseudo-Target abzielte und keine Klassifizierung zwischen Target-Verben und Target-
Substantiven erforderte. Die lexikalische Entscheidungsaufgabe wurde in der vorliegenden
Studie gewählt, da sowohl in der Studie von Goodman et al. (1981) als auch in der Studie von
Sereno (1991) lexikalische Entscheidungsaufgaben zu signifikanten Ergebnissen bei
syntaktischem Priming geführt hatten. Eine mögliche Erklärung, weshalb die lexikalische
Entscheidungsaufgabe in der vorliegenden Studie nicht zu den erwarteten Resultaten geführt
haben könnte, wäre, dass die Aufgabenstellung an die Versuchspersonen die eigentliche
Fragestellung der Studie nicht ausreichend unterstützt haben könnte.
Laut Kahneman & Treisman (1984) kann man subliminales syntaktisches Priming
entweder der sogenannten „starken automatischen Verarbeitung“ (engl. „strong
automaticity“) oder der sogenannten „schwachen automatischen Verarbeitung“ (engl. „weak
automaticity“) zuordnen. Der Definition von Ansorge et al. (2013) zufolge werden Aktionen
bzw. Reaktionen, die der starken automatischen Verarbeitung entspringen, durch den
Stimulus als solchen ausgelöst und bedürfen keiner Absicht oder vordefinierten
Aufgabenstellung. Diese Prozesse finden quasi unwillkürlich statt sobald der Stimulus, der sie

SUBLIMINALES SYNTAKTISCHES PRIMING 46
auslöst, sich präsentiert bzw. präsentiert wird (Ansorge et al., 2013). Aktionen bzw.
Reaktionen, die der schwachen automatischen Verarbeitung entspringen, können Ansorge et
al. (2013) zufolge zumindest bewusst unterdrückt werden. Einige dieser Prozesse bedürfen
womöglich gar einer entsprechenden Absicht oder Aufgabenstellung (Ansorge et al., 2013).
Es gibt verschiedene Theorien, welcher dieser Verarbeitungsprozesse subliminales
syntaktisches Priming konkret unterliegt. Laut Bargh (1992) ist subliminales Priming generell
der schwachen automatischen Verarbeitung zuzuordnen und unterliegt der sogenannten
„bedingten automatischen Verarbeitung“ (engl. „conditional automaticity“). Konkret heißt
das, dass subliminales syntaktisches Priming von der bereits aufgebauten Absicht bzw. der
konkreten vorgegebenen Aufgabenstellung abhängig ist. Erst mit dem Aufbau einer solchen
Absicht bzw. einer entsprechenden Aufgabenstellung könnte ein subliminaler Stimulus erst
einen konkreten Verarbeitungsprozess einleiten (Ansorge et al., 2013; Ansorge & Neumann,
2005).
In der Studie von Ansorge et al. (2013) war es das Ziel herauszufinden, ob eine starke
oder schwache automatische Form für die Verarbeitung subliminaler syntaktischer Prozesse
verantwortlich ist. Im ersten Experiment der besagten Studie wurden subliminale weibliche
oder männliche Artikel als Primes und sichtbare männliche oder weibliche Substantive als
Targets vorgegeben. Die Versuchspersonen mussten eine Geschlechtsklassifikationsaufgabe
durchführen, in der sie entscheiden mussten, ob es sich bei den sichtbaren Targets um
männliche oder weibliche Substantive handelte. Es zeigte sich, dass die Reaktionen der
Versuchspersonen in kongruenten Bedingungen signifikant schneller als in inkongruenten
Bedingungen waren. Im zweiten Experiment wurde mit Hilfe einer Kontrollfunktion
untersucht, ob der Kongruenz-Effekt tatsächlich abhängig von der Aufgabenstellung war.
Besagte Kontrollfunktion umfasste die Unterscheidung der Targets in die beiden Kategorien
„Geschirr/Besteck“ und „Körperteile“. Es wurden dieselben Stimuli wie im ersten Experiment
verwendet. In der Kontrollvariante gab es keinen Kongruenz-Effekt. Das wurde von Ansorge
et al. (2013) als Bestätigung der bedingten automatischen Verarbeitung gewertet. Im ersten
Experiment hatten die subliminalen Artikel, die ebenfalls männlich oder weiblich waren,
somit einen signifikanten Einfluss auf die Reaktionszeiten der Versuchspersonen in der
Kategorisierungsaufgabe nach Geschlecht. Im zweiten Experiment wurde eine Klassifizierung
in die Kategorien „Geschirr/Besteck“ und „Körperteile“ durchgeführt. Hier hatten die
subliminal präsentierten Artikel, die nichts über die Kategorien „Geschirr/Besteck“ und
„Körperteile“ verrieten, keinen signifikanten Einfluss auf die Reaktionszeiten der

SUBLIMINALES SYNTAKTISCHES PRIMING 47
Versuchspersonen. Im zweiten Experiment waren somit die Kriterien der bedingten
automatischen Verarbeitung nicht erfüllt (Ansorge et al., 2013).
Durch die Wahl der lexikalischen Entscheidungsaufgabe bei der vorliegenden Studie
wurde das soeben geschilderte Kriterium der bedingten automatischen Verarbeitung nicht
erfüllt. Die Versuchspersonen hatten die Aufgabenstellung und somit die konkrete Absicht
zwischen Targets und Pseudo-Targets zu unterscheiden. Die der bedingten automatischen
Verarbeitung entsprechende Aufgabenstellung zum Erreichen des erwarteten Ergebnisses
wäre in diesem Fall jedoch eine Wortklassifikationsaufgabe, nämlich die Unterscheidung
zwischen Target-Verb und Target-Substantiv, gewesen. Da laut Ansorge et al. (2013) die
Aufgabenstellung die Wirkung des subliminalen Stimulus überhaupt erst ermöglicht, kann
davon ausgegangen werden, dass ein Pronomen-Prime als subliminaler Stimulus bei einer
lexikalischen Entscheidungsaufgabe nicht den gewünschten Verarbeitungsprozess einleiten
konnte. Entsprechend der bedingten automatischen Verarbeitung wurde mit der in der
vorliegenden Studie gewählten Aufgabenstellung, der lexikalischen Entscheidungsaufgabe,
bei den Versuchspersonen die Absicht geweckt zwischen Wörtern und Pseudo-Wörtern zu
wählen. Eine Wortklassifikationsaufgabe hätte bei den Versuchspersonen eher die Absicht
geweckt, zwischen Target-Verben und Target-Substantiven zu wählen. Ein Pronomen-Prime
als subliminaler Stimulus hätte bei der Unterscheidung zwischen Target-Verben und Target-
Substantiven möglicherweise den gewünschten Verarbeitungsprozess einleiten können.
In der Studie von Ansorge und Becker (in Vorbereitung) wurde beispielsweise die
sogenannte Wortklassifikationsaufgabe als Aufgabenstellung vorgegeben, bei welcher die
Versuchspersonen entscheiden mussten, ob es sich bei den präsentierten Targets um Verben
oder Substantive handelte. Diese Aufgabenstellung würde in der vorliegenden Studie eher das
Kriterium der bedingten automatischen Verarbeitung erfüllen, da ein Vorteil zwischen den
Verben gegenüber den Substantiven untersucht wurde und eine Wortklassifikationsaufgabe
genau die Unterscheidung dieser beiden Wortklassen erfordern hätte können. Die lexikalische
Entscheidungsaufgabe hingegen weicht als Aufgabenstellung eher von der eigentlichen
Fragestellung der Studie ab und der subliminale Stimulus entfaltete somit laut der bedingten
automatischen Verarbeitung nicht die gewünschte Wirkung bei der Entscheidung zwischen
Target-Verben und Target-Substantiven.
Zusammenfassend kann man festhalten, dass das subliminale syntaktische Priming mit
Pronomen als Primes nicht zu den erwarteten Ergebnissen bezüglich der signifikant kürzeren
Reaktionszeit und der signifikant geringeren Fehlerrate bei der Erkennung von Verben im
Vergleich zu der Erkennung von Substantiven geführt hat. Hierfür wird der in der Diskussion

SUBLIMINALES SYNTAKTISCHES PRIMING 48
zuletzt besprochene Punkt der Aufgabenstellung, die die Voraussetzungen der bedingten
automatischen Verarbeitung nicht erfüllt hat, als entscheidender Faktor angesehen. Die
gewählte Aufgabenstellung war eine lexikalische Entscheidungsaufgabe, die auf die
Unterscheidung von Wörtern und Nicht-Wörtern abzielte. Da es jedoch das Ziel der
vorliegenden Studie war, die Wortklassen Verben und Substantive zu unterscheiden,
entsprach die lexikalische Entscheidungsaufgabe als Aufgabenstellung nicht den Kriterien der
bedingten automatischen Verarbeitung. Erst mit dem Aufbau einer geeigneten
Aufgabenstellung bzw. Absicht kann ein subliminaler Stimulus einen konkreten
Verarbeitungsprozess einleiten (Ansorge & Neumann, 2005). Wenn man somit die
Klassifikation von Verben und Substantiven erfassen möchte, muss die Aufgabenstellung
diese Intention aufbauen. Zukünftig könnte man weitere Forschung in diesem Bereich mit
einer der bedingten automatischen Verarbeitung entsprechenden Aufgabenstellung, wie
beispielsweise einer Wortklassifikationsaufgabe, anstelle der hier gewählten lexikalischen
Entscheidungsaufgabe, fortführen.

SUBLIMINALES SYNTAKTISCHES PRIMING 49
5. Literatur
Ansorge, U. & Becker, S. (in Vorbereitung). Subliminal Word-Class Priming.
Ansorge, U., Kiefer, M., Khalid, S., Grassl, S. & König, P. (2010). Testing the theory of
embodied cognition with subliminal words. Cognition, 116, 303-320. doi:
10.1016/j.cognition.2010.05.010
Ansorge, U. & Neumann, O. (2005). Intentions determine the effect of invisible metacontrast-
masked primes: Evidence for top-down contingencies in a peripheral cueing task.
Journal of Experimental Psychology: Human Perception and Performance, 31, 762-
777.
Ansorge, U., Reynvoet, B., Hendler, J., Oettl, L. & Evert, S. (2013). Conditional automaticity
in subliminal morphosyntactic priming. Psychological Research, 77, 399-421. doi:
10.1007/s00426-012-0442-z
Balota, D. A. & Chumbley, J. I. (1984). Are lexical decisions a good measure of lexical
access? The role of word frequency in the neglected decision stage. Journal of
Experimental Psychology: Human Perception and Performance, 10, 340-357.
Balota, D. A., Cortese, M. J., Sergent-Marshall, S. D., Spieler, D. H. & Yap, M. J. (2004).
Visual word recognition of single-syllable words. Journal of Experimental
Psychology: General, 133, 283-316.
Barber, H. & Carreiras, M. (2005). Grammatical gender and number agreement in Spanish: an
ERP comparison. Journal of Cognitive Neuroscience, 17, 137-153.
Bargh, J. A. (1992). The ecology of automaticity: Toward establishing the conditions needed
to produce automatic processing effects. American Journal of Psychology, 105, 181-
199.
Cambridge Dictionaries Online (2014). Abgerufen am 1. August 2014 von
http://dictionary.cambridge.org/
Colé, P. & Segui, J. (1994). Grammatical incongruency and vocabulary types. Memory &
Cognition, 22, 387-394.
Collins, A. M. & Loftus, E. F. (1975). A spreading-activation theory of semantic processing.
Psychological Review, 82, 407–428.
Connine, M. C., Mullenix, J., Shernoff, E. & Yelen, J. (1990). Word familiarity and frequency
in visual and auditory word recognition. Journal of Experimental Psychology.
Learning, Memory, and Cognition, 16, 1084-1096.

SUBLIMINALES SYNTAKTISCHES PRIMING 50
Forster, K. & Davis, C. (1984). Repetition priming and frequency attenuation in lexical
access. Journal of Experimental Psychology. Learning, Memory, and Cognition, 10,
680-698.
Friederici, A. D. (2002). Towards a neural basis of auditory sentence processing. Trends in
Cognitive Sciences, 6, 78-84.
Goodman, G., McClelland, K. & Gibbs, R. (1981). The role of syntactic context in word
recognition. Memory & Cognition, 9, 580-586.
Green, D. M. & Swets, J. A. (1966). Signal detection theory and psychophysics. New York:
Wiley.
Greenwald, A. G., Draine, S. C. & Abrams, R. L. (1996). Three cognitive markers of
unconscious semantic activation. Science, 273, 1699-1702.
Guajardo, L. F. & Wicha, N. Y. Y. (2014). Morphosyntax can modulate the N400 component:
Event related potentials to gender-marked post-nominal adjectives. NeuroImage, 91,
262–272. doi: 10.1016/j.neuroimage.2013.09.077
Hinojosa, J. A., Albert, J., Fernández-Folgueiras, U., Santaniello, G., López-Bachiller, C.,
Sebastián, M.,… Pozo, M.A. (2014). Effects of negative content on the processing of
gender information: An event-related potential study. Cognitive, Affective, &
Behavioral Neuroscience. doi: 10.3758/s13415-014-0291-x
Hutchison, K. A. (2003). Is semantic priming due to association strength or feature overlap?
A mircoanalytic review. Psychonomic Bulletin & Review, 10, 785-813. doi:
10.3758/bf03196544
Kahneman, D. & Treisman, A. (1984). Changing views of attention and automaticity. In R.
Parasuraman, R. Davies & J. Beatty (Eds.), Varieties of attention (pp. 29–61). New
York: Academic Press.
Khalid, S., König, P. & Ansorge, U. (2011). Sensitivity of different measures of the visibility
of masked primes: Influences of prime-response and prime-target relations.
Consciousness and Cognition, 20, 1473-1488. doi: 10.1016/j.concog.2011.06.014
Kiefer, M. (2002). The N400 is modulated by unconciously perceived masked words: further
evidence for an automatic spreading activation account of N400 priming effects.
Cognitive Brain Research, 13, 27-39.
Kiefer, M. & Brendel, D. (2006). Attentional modulation of unconscious ”automatic”
processes: Evidence from event-related potentials in a masked priming paradigm.
Journal of Cognitive Neuroscience, 18, 184-198.

SUBLIMINALES SYNTAKTISCHES PRIMING 51
Kiefer, M. & Martens, U. (2010). Attentional sensitization of unconscious cognition: task sets
modulate subsequent masked semantic priming. Journal of Experimental Psychology:
General, 139, 464-489.
Kiefer, M. & Spitzer, M. (2000). Time course of conscious and unconscious semantic brain
activations. NeuroReport, 11, 2401-2407.
Kiesel, A. (2009). Unbewusste Wortwahrnehmung. Handlungsdeterminierende
Reizerwartungen bestimmen die Wirksamkeit subliminaler Reize. Psychologische
Rundschau, 60, 215–228. doi:10.1026/0033-3042.60.4.215
Klinger, M. R. & Greenwald, A. G. (1995). Unconscious priming of association judgements.
Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 569-581.
Klotz, W. & Neumann, O. (1999). Motor activation without conscious discrimination in
metacontrast masking. Journal of Experimental Psychology. Human Perception and
Performance, 25, 976-992.
Kutas, M. & Hillyard, S. A. (1980). Reading senseless sentences: Brain potentials reflect
semantic incongruity. Science, 207, 203-205.
Marcel, A. J. (1983). Conscious and unconscious perception: Experiments on visual masking
and word recognition. Cognitive Pychology, 15, 197-237.
Merikle, P. M. & Daneman, M. (1998). Psychological investigations of unconscious
perception. Journal of Consciousness Studies, 5, 5-18.
Meyer, D. E. & Schvaneveldt, R. W. (1971). Facilitation in recognizing pairs of words:
Evidence of dependence between retrieval operations. Journal of Experimental
Psychology, 90, 227-234.
Neely, J. H. (1976). Semantic priming and retrieval from lexical memory: Evidence for
facilitory and inhibitory processes. Memory & Cognition, 4, 648-654.
Neely, J. H. (1977). Semantic priming and retrieval from lexical memory: Roles of
inhibitionless spreading of activation and limited-capacity attention. Journal of
Experimental Psychology: General, 106, 226-254.
New, B., Ferrand, L., Pallier, C. & Brysbaert, M. (2006). Reexamining the word length effect
in visual word recognition: New evidence from English Lexicon Project. Psychonomic
Bulletin & Review, 13, 45-52.
Nicol, J. L. (1996). Syntactic priming. Language and Cognitive Processes, 11, 675-680.
Osterhout, L. & Nicol, J. L. (1999). On the distinctiveness, independence, and time course of
the brain responses to syntactic and semantic anomalies. Language and Cognitive
Processes, 14, 283–317.

SUBLIMINALES SYNTAKTISCHES PRIMING 52
Projekt Deutscher Wortschatz (2014). Abgerufen am 18. April 2014 von http://www.dict.uni-
leipzig.de/
Reingold, E. M. & Merikle, P. (1988). Using direct and indirect measures to study perception
without awareness. Perception & Psychophysics, 44, 563-575.
Reingold, E. M. & Merikle, P. (1990). On the inter-relatedness of theory and measurement in
the study of unconscious processes. Mind and Language, 5, 9 – 28.
Schilling, H. E. H., Rayner, K. & Chumbley, J. I. (1998). Comparing naming, lexical
decision, and eye fixation times: Word frequency effects and individual differences.
Memory & Cognition, 26, 1270-1281.
Seidenberg, M., Waters, G., Sanders, M. & Langer, P. (1984). Pre- and postlexical loci of
contextual effects on word recognition. Memory & Cognition, 12, 315-328.
Sereno, J. A. (1991). Graphemic, associative, and syntactic priming effects at a brief stimulus
onset asynchrony in lexical decision and naming. Journal of Experimental Psychology.
Learning, Memory, and Cognition, 17, 459-477.
Tanaka-Ishii, K. & Terada, H. (2011). Word familiarity and frequency. Studia Linguistica, 65,
96-116. doi: 10.1111/j.1467-9582.2010.01176.x
Tanner, D. & Van Hell, J.G. (2014). ERPs reveal individual differences in morphosyntactic
processing. Neuropsychologia, 56, 289–301.
Vorberg, D., Mattler, U., Heinecke, A., Schmidt, T., Schwarzbach, J. (2003). Different time
courses for visual perception and action priming. Proceedings of the National
Academy of Sciences, USA, 100, 6275-6280.
West, R. F. & Stanovich, K. E. (1986). Robust effects of syntactic structure on visual word
processing. Memory & Cognition, 14, 104-112.
Wright, B. & Garrett, M. (1984). Lexical decision in sentences: Effects of syntactic structure.
Memory & Cognition, 12, 31-45.

SUBLIMINALES SYNTAKTISCHES PRIMING 53
Appendix A
Die in der vorliegenden Studie verwendeten Verben sind in Appendix A in alphabetischer
Reihenfolge aufgelistet. In den runden Klammern hinter den Verben sind die entsprechenden
Häufigkeiten angegeben. Die Häufigkeiten wurden am 18. April 2014 von der Webseite
„Projekt Deutscher Wortschatz“ (2014) entnommen. In den eckigen Klammern hinter den
Verben im Singular sowie hinter den Verben im Plural ist die Anzahl der Buchstaben der
einzelnen Wörter aufgezeigt. Da die Umlaute in der vorliegenden Studie als Vokale mit
nachgestelltem „E“ präsentiert wurden (z.B. „AE“ statt „Ä“), wurde diese Variante bei der
Zählung der Buchstaben berücksichtigt.
Verben im Singular und Plural
Infinitive (nicht verwendet)
1. Fall Singular
1. Fall Plural
BEISSEN (667) BEISSE [6] BEISSEN (667) [7]
BELLEN (160) BELLE (53) [5] BELLEN (160) [6]
BETEN (797) BETE [4] BETEN (797) [5]
SEIN BIN [3] SIND [4]
BLINKEN (230) BLINKE [6] BLINKEN (230) [7]
BLUTEN (305) BLUTE [5] BLUTEN (305) [6]
BRAUCHEN (17322) BRAUCHE (5408) [7] BRAUCHEN (17322) [8]
BRUETEN (404) BRUETE [6] BRUETEN (404) [7]
DUERFEN (32492) DARF (45465) [4] DUERFEN (32492) [7]
DEHNEN (238) DEHNE [5] DEHNEN (238) [6]
DENKEN (13707) DENKE (6225) [5] DENKEN (13707) [6]
DUFTEN (123) DUFTE [5] DUFTEN (123) [6]
FAELSCHEN (169) FAELSCHE [8] FAELSCHEN (169) [9]
FAERBEN (241) FAERBE [6] FAERBEN (241) [7]
FEGEN (259) FEGE [4] FEGEN (259) [5]
FEHLEN (2023) FEHLE [5] FEHLEN (2023) [6]
GAEHNEN (159) GAEHNE (4) [6] GAEHNEN (159) [7]
GEBEN (71035) GEBE (28987) [4] GEBEN (71035) [5]
GEHEN (60649) GEHE (16590) [4] GEHEN (60649) [5]
GRABSCHEN GRABSCHE [8] GRABSCHEN [9]
HEBEN (2371) HEBE [4] HEBEN (23171) [5]
HEISSEN (11035) HEISSE (3669) [6] HEISSEN (11035) [7]
HEILEN (1331) HEILE [5] HEILEN (1331) [6]
HEIZEN (339) HEIZE [5] HEIZEN (339) [6]
HELFEN (18784) HELFE [5] HELFEN (18784) [6]
HERRSCHEN (2207) HERRSCHE [8] HERRSCHEN (2207) [9]
HINKEN (262) HINKE (124) [5] HINKEN (262) [6]
HISSEN (134) HISSE [5] HISSEN (134) [6]
HOFFEN (10725) HOFFE (5251) [5] HOFFEN (10725) [6]
HUEPFEN (446) HUEPFE [6] HUEPFEN (446) [7]
HUNGERN (351) HUNGERE (5) [7] HUNGERN (351) [7]

SUBLIMINALES SYNTAKTISCHES PRIMING 54
Infinitive (nicht verwendet)
1. Fall Singular
1. Fall Plural
HUSCHEN (220) HUSCHE [6] HUSCHEN (220) [7]
JAETEN (45) JAETE [5] JAETEN (45) [6]
JUBELN (587) JUBELE [6] JUBELN (587) [6]
JUCHZEN JUCHZE [6] JUCHZEN [7]
JUCKEN (44) JUCKE [5] JUCKEN (44) [6]
KOENNEN KANN [4] KOENNEN [7]
KENNEN (12184) KENNE (3505) [5] KENNEN (12184) [6]
KOCHEN (1234) KOCHE [5] KOCHEN (1234) [6]
KOMMEN (85579) KOMME (11385) [5] KOMMEN (85579) [6]
LACHEN (2841) LACHE (121) [5] LACHEN (2841) [6]
LAECHELN (3773) LAECHLE [7] LAECHELN (3773) [8]
LAEHMEN (46) LAEHME [6] LAEHMEN (46) [7]
LAUFEN (15312) LAUFE [5] LAUFEN (15312) [6]
MACHEN MACHE (8414) [5] MACHEN [6]
MOEGEN (6170) MAG [3] MOEGEN (6170) [6]
MAHLEN (186) MAHLE (1) [5] MAHLEN (186) [6]
MOECHTEN (12568) MOECHTE [7] MOECHTEN (12568) [8]
SAEHEN SAEHE [5] SAEHEN [6]
SEHEN (68267) SEHE (10431) [4] SEHEN (68267) [5]
SETZEN (27238) SETZE (33) [5] SETZEN (27238) [6]
SIEZEN SIEZE [5] SIEZEN [6]
STAMPFEN (225) STAMPFE [7] STAMPFEN (225) [8]
STEHEN (76201) STEHE (11515) [5] STEHEN (76201)[6]
STERBEN (5972) STERBE (208) [6] STERBEN (5972) [7]
STOCKEN (764) STOCKE [6] STOCKEN (764) [7]
TAETEN TAETE [5] TAETEN [6]
TANZEN (2867) TANZE [5] TANZEN (2867) [6]
TOBEN (586) TOBE [4] TOBEN (586) [5]
TOETEN (2829) TOETE [5] TOETEN (2829) [6]
TRACHTEN (212) TRACHTE [7] TRACHTEN (212) [8]
TRAUEN (2083) TRAUE (390) [5] TRAUEN (2083) [6]
TRAUERN (391) TRAUERE [7] TRAUERN (391) [7]
TRINKEN (3448) TRINKE (320) [6] TRINKEN (3448) [7]
WAGEN (13913) WAGE (406) [4] WAGEN (13913) [5]
WUERGEN (97) WUERGE [6] WUERGEN (97) [7]
WUESSTEN WUESSTE [7] WUESSTEN [8]
WUETEN (129) WUETE [5] WUETEN (129) [6]
Häufigkeit (59 Wörter)
Ø = 10.084,34
Häufigkeit (23 Wörter)
Ø = 6.891,74
Buchstaben/Wort
Ø = 5,41
Häufigkeit (59 Wörter)
Ø = 10.084,34
Buchstaben/Wort
Ø = 6,46
Die durchschnittliche Häufigkeit der Verben im Singular, im Plural als auch in der
Infinitivform ist relativ zu den 400.000 Einträgen in der oben genannten Datenbank unter der
ersten Spalte dargestellt. Wörter, für die es in dieser Datenbank keine Häufigkeiten gab,
wurden bei der Berechnung der durchschnittlichen Häufigkeiten nicht berücksichtigt.

SUBLIMINALES SYNTAKTISCHES PRIMING 55
Die durchschnittliche Anzahl der Buchstaben der Verben in der Infinitivform ist unter der
ersten Spalte zu finden, die durchschnittliche Anzahl der Buchstaben der Verben im Singular
ist unter der zweiten Spalte zu finden und die durchschnittliche Anzahl der Buchstaben der
Verben im Plural ist unter der dritten Spalte angeführt.

SUBLIMINALES SYNTAKTISCHES PRIMING 56
Appendix B
Die in der vorliegenden Studie verwendeten Pseudo-Verben sind in Appendix B in
alphabetischer Reihenfolge aufgelistet. In den eckigen Klammern hinter den Pseudo-Verben
ist die Anzahl der Buchstaben der einzelnen Pseudo-Verben aufgezeigt. Da die Umlaute in
der vorliegenden Studie als Vokale mit nachgestelltem „E“ präsentiert wurden (z.B. „AE“
statt „Ä“), wurde diese Variante bei der Zählung der Buchstaben berücksichtigt.
Pseudo-Verben im Singular
BEKSE [5] HEIFE [5] MAFE [4] WUEZTE [6]
BELE [4] HEITE [5] MAHTE [5] WUTTE [5]
BERRE [5] HELSSE [6] MECHTE [6]
BLATE [5] HEPFE [5] MEG [3]
BLIMKE [6] HERRSE [6] SAUHE [5]
BRAICHE [7] HILKE [5] SETTE [6]
BRUEFE [6] HISPE [5] SIESE [5]
BUN [3] HORRE [5] STAMPE [6]
DALF [4] HUCHE [5] STIHE [5]
DEHSE [5] HUNKERE [7] STOGGE [6]
DENLE [5] JAESE [5] STORBE [6]
DULTE [5] JICKE [5] SUHE [4]
FAEBE [5] JUCKZE [6] TAEFE [5]
FAEMSCHE [8] JUTELE [6] TENZE [5]
FEKE [4] KARN [4] TIETE [5]
FEKLE [5] KEMME [5] TOLE [4]
GAHNE [5] KOCKE [5] TRAHTE [6]
GEJE [4] KONNE [5] TRAMERE [7]
GEKE [4] LACHLE [6] TRIE [4]
GRASCHE [7] LAEHFE [6] TRIMKE [6]
HAPE [4] LAFE [4] WACKE [5]
HEFFE [5]
LICHE [5]
WUERKE [6]
Buchstaben/Wort
Ø = 5,18
Die durchschnittliche Anzahl von Buchstaben der Pseudo-Verben im Singular ist unter der
ersten Spalte angeführt.

SUBLIMINALES SYNTAKTISCHES PRIMING 57
Pseudo-Verben im Plural
BEITSEN [7] HELSSEN [7] MECHTEN [7] WUENEN [6]
BELEN [5] HELZEN [6] MICHEN [6] WUERKEN [7]
BERREN [6] HEPEN [5] MOEKEN [6]
BLATEN [6] HICKEN [6] SAUHEN [6]
BLENKEN [7] HISSEN [6] SEKSEN [6]
BRAICHEN [8] HORREN [6] SEPEN [5]
BRUEFEN [7] HUCHEN [6] SIESEN [6]
DEHSEN [6] HUERFEN [7] SIMD [4]
DELKEN [6] HUNNERN [7] SPOCKEN [7]
DUELFEN [7] JAESEN [6] STAMPEN [7]
DULTEN [6] JECHZEN [7] STEMBEN [7]
FAEBEN [6] JICKEN [6] STIHEN [6]
FAERSCHEN [9] JUBALN [6] TAEFEN [6]
FEKEN [5] KINNEN [6] TENZEN [6]
FIHLEN [6] KOEPPEN [7] TOITEN [6]
GAHNEN [6] KONNEN [6] TOHEN [5]
GEDEN [5] KOSCHEN [7] TRAHTEN [7]
GEFEN [5] LACHON [6] TRALERN [7]
GRASCHEN [8] LACKELN [7] TRAMEN [6]
HEIGEN [6] LAEHFEN [7] TRIMKEN [7]
HERRSEN [7] LAFEN [5] WACKEN [6]
HEIFEN [6]
MAHTEN [6]
WEUSSTEN [8]
Buchstaben/Wort
Ø = 6
Die durchschnittliche Anzahl von Buchstaben der Pseudo-Verben im Plural ist unter der
ersten Spalte angeführt.

SUBLIMINALES SYNTAKTISCHES PRIMING 58
Appendix C
Die in der vorliegenden Studie verwendeten Substantive sind in Appendix C in alphabetischer
Reihenfolge aufgelistet. In den runden Klammern hinter den jeweiligen Substantiven sind die
Häufigkeiten angegeben. Die Häufigkeiten wurden am 18. April 2014 von der Webseite
„Projekt Deutscher Wortschatz“ (2014) entnommen.
In den eckigen Klammern hinter den jeweiligen Substantiven ist die Anzahl der Buchstaben
der einzelnen Wörter aufgezeigt. Da die Umlaute in der vorliegenden Studie als Vokale mit
nachgestelltem „E“ präsentiert wurden (z.B. „AE“ statt „Ä“), wurde diese Variante bei der
Zählung der Buchstaben berücksichtigt.
Substantive im Singular
AEHRE (36) [5] HITZE (2921) [5] SACHE (27959) [5] WURZEL (977) [6]
ARSEN (320) [5] HOPFEN (251) [6] SAND (4565) [4] ZWIEBEL (178) [7]
BEIN (3150) [4] HUF [3] SARG (1093) [4]
BIER (30) [4] HUT [3] SCHWALBE (236) [8]
BLEI (1177) [4] JET [3] SEE [3]
BLUME (902) [5] JUWEL (338) [5] SEIDE (767) [5]
BODEN (22367) [5] KANNE (182) [5] SILBE (347) [5]
DARM (633) [4] KARTON (683) [6] SITTE (637) [5]
DORF (9825) [4] KINN (598) [4] SPATEN (387) [6]
DUENE (118) [5] KOPF (27477) [4] STAB (1030) [4]
FAEHRE (1245) [6] LAGE (35163) [4] STEIN (6206) [5]
FAHNE (1945) [5] LAICH (31) [5] STERN (5390) [5]
FALTER (229) [6] LAKEN (234) [5] TANTE (1867) [5]
FLASCHE (2464) [7] LUKE (247) [4] TASCHE (5384) [6]
GARTEN (5990) [6] MANN (81622) [4] TOPF (1553) [4]
GELD (67311) [4] MARKT (44457) [5] TORTE (249) [5]
GERTE (21) [5] MOND (3109) [4] TRAUBE (223) [6]
HAFEN (5513) [5] OFEN (1108) [4] TRAUM (8592) [5]
HEFE (318) [4] OSTERN (2334) [6] TRUBEL (652) [6]
HELD (3898) [4] RAKETE (1557) [6] WAFFE (4183) [5]
HELM (1031) [4] REBE (51) [4] WARE (5207) [4]
HIRTE (193) [5]
RUBIN [5]
WUESTE (3268) [6]
Häufigkeit (63 Wörter)
Ø = 6.540,14
Buchstaben/Wort
Ø = 5
Die durchschnittliche Anzahl der Buchstaben der Substantive im Singular ist unter der dritten
Spalte angeführt.

SUBLIMINALES SYNTAKTISCHES PRIMING 59
Substantive im Plural
BAECHE (317) [6] HIRTEN (572) [6] RASSEN (782) [6] WUERMER (369) [7]
BEETE (165) [5] HOEFE (530) [5] REBEN (295) [5] ZIEGEN (677) [6]
BIBELN [6] HUEHNER (1020) [7] REHE (269) [4]
BIENEN (724) [6] HUMMELN (141) [7] RIFFE (149) [5]
BIRNEN (414) [6] JETS (4686) [4] RUEBEN (312) [6]
BLUMEN (3412) [6] JUWELEN (355) [7] SACHEN (4572) [6]
BOJEN (75) [5] KASSEN [6] SAECKE (781) [6]
BOOTE (1107) [5] KOERBE (6) [6] SEELEN (1408) [6]
BRITEN (6668) [6] KROETEN (327) [7] SEEN [4]
DAERME (46) [6] KUECHEN (2314) [7] SEITEN (30559) [6]
DIEBE (1462) [5] KULTE (122) [5] SITTEN (1332) [6]
DUENEN (320) [6] LARVEN (674) [6] STAEBE (6) [6]
FAEHRTEN (1693) [8] LATTEN (106) [6] STEINE (3245) [6]
FAHNEN (2100) [6] LEITERN [7] TANTEN (265) [6]
GELDER (5588) [6] MAEGEN (1717) [6] TIERE (13854) [5]
GENE (2755) [4] MASCHEN (280) [7] TOEPFE (351) [6]
GERTEN [6] MEERE (698) [6] TONNEN (17152) [6]
HAEFEN (5513) [6] MENSCHEN [8] TORTEN (145) [6]
HAENDE (10182) [6] MOOSE (361) [5] TRASSEN [7]
HELDEN (6518) [6] NARBEN (540) [6] TREPPEN (1055) [7]
HELME (278) [5] OEFEN (1108) [5] WAAGEN [6]
HIRNE (133) [5]
PFAFFEN [7]
WITZE (998) [5]
Häufigkeit (59 Wörter)
Ø = 2.433,19
Buchstaben/Wort
Ø = 5,9
Die durchschnittliche Häufigkeit der Substantive ist relativ zu den 400.000 Einträgen in der
oben genannten Datenbank unter der ersten Spalte dargestellt. Wörter, für die es in dieser
Datenbank keine Häufigkeiten gab, wurden bei der Berechnung der durchschnittlichen
Häufigkeit nicht berücksichtigt.
Die durchschnittliche Anzahl der Buchstaben der Substantive im Plural ist unter der dritten
Spalte angeführt.

SUBLIMINALES SYNTAKTISCHES PRIMING 60
Appendix D
Die in der vorliegenden Studie verwendeten Pseudo-Substantive sind in Appendix D in
alphabetischer Reihenfolge aufgelistet. In den eckigen Klammern hinter den Pseudo-
Substantiven ist die Anzahl der Buchstaben der einzelnen Pseudo-Substantive aufgezeigt. Da
die Umlaute in der vorliegenden Studie als Vokale mit nachgestelltem „E“ präsentiert wurden
(z.B. „AE“ statt „Ä“), wurde diese Variante bei der Zählung der Buchstaben berücksichtigt.
Pseudo-Substantive im Singular
AEHLE [5] HIGTE [5] SAA [3] WURMEL [6]
ARZEN [5] HILM [4] SALD [4] ZWIEFEL [7]
BAIN [4] HIPFEN [6] SALG [4]
BIHR [4] HITTE [5] SCHMALBE [8]
BLAI [4] JAT [3] SEIKE [5]
BLAJE [5] JUMEL [5] SICHE [5]
BOSEN [5] KAPF [4] SIFBE [5]
DOENE [5] KARNE [5] SINTE [5]
DOFF [4] KARTAN [6] SPATON [6]
DURM [4] KILN [4] STAIN [5]
FAEHTE [6] LAICK [5] STARN [5]
FAHGE [5] LAKIN [5] STEB [4]
FALTOR [6] LAWE [4] TAPF [4]
FLUSCHE [7] LIKE [4] TAUTE [5]
GARMEN [6] MAEN [4] TESCHE [6]
GEFTE [5] MALKT [5] TOKTE [5]
GEND [4] MEND [4] TRAIBE [6]
HALEN [5] OFAN [4] TRAIM [5]
HEND [4] OSSERN [6] TRUKEL [6]
HEPE [4] RAKOTE [6] WANFE [5]
HET [3] RIWE [4] WAPE [4]
HIF [3]
RUPIN [5]
WUERTE [6]
Buchstaben/Wort
Ø = 4,85
Die durchschnittliche Anzahl der Buchstaben der Pseudo-Substantive im Singular ist unter der
ersten Spalte angeführt.

SUBLIMINALES SYNTAKTISCHES PRIMING 61
Pseudo-Substantive im Plural
BAICHE [6] HILNE [5] RAGGEN [6] WUEKMER [7]
BEESE [5] HILTEN [6] REPE [4] ZIEKEN [6]
BIBOLN [6] HUEGNER [7] REPEN [5]
BIELEN [6] HUMBELN [7] RIMME [5]
BILNEN [6] JEGS [4] RUHBEN [6]
BLIMEN [6] JUNELEN [7] SAAN [4]
BOKEN [5] KATTEN [6] SAECHE [6]
BONTE [5] KROEFEN [7] SEEFEN [6]
BRUTEN [6] KUERBE [6] SEFTEN [6]
DAELME [6] KUFTE [5] SICHEN [6]
DIHBE [5] KUHCHEN [7] SIDDEN [6]
DUEKEN [6] LADDEN [6] STAIBE [6]
FAEHRMEN [8] LAITERN [7] STAINE [6]
FAHKEN [6] LARMEN [6] TARTEN [6]
GEFE [4] MAEKEN [6] TIEPFE [6]
GELTER [6] MEELE [5] TIHRE [5]
GERKEN [6] MEMSCHEN [8] TOLTEN [6]
HAEMDE [6] MESCHEN [7] TONKEN [6]
HAIFEN [6] MOOTE [5] TRAFFEN [7]
HELKEN [6] NALBEN [6] TREBBEN [7]
HERME [5] OETEN [5] WAAKEN [6]
HIEFE [5]
PFATTEN [7]
WISTE [5]
Buchstaben/Wort
Ø = 5,88
Die durchschnittliche Anzahl der Buchstaben der Pseudo-Substantive im Plural ist unter der
ersten Spalte angeführt.

SUBLIMINALES SYNTAKTISCHES PRIMING 62
Curriculum Vitae
Persönliche Daten
Name: Reyhan Vurgun
Geburtsdatum: 22.04.1988
Geburtsort: Holzminden
Staatsbürgerschaft: Deutschland
Familienstand: Ledig
Bildungsweg
Seit Sommersemester 2009 Diplomstudium der Psychologie an der Universität Wien
26.06.2007 Allgemeine Hochschulreife
2000 – 2007 Campe-Gymnasium, Holzminden
1998 – 2000 Orientierungsstufe Astrid-Lindgren, Holzminden
1994-1998 Grundschule an den Teichen, Holzminden
Psychologische Praktika
01.07.2013 – 09.08.2013 Sechswöchiges Praktikum in der medizinischen Klinik mit
dem Schwerpunkt Psychosomatik an der Charité in Berlin
Praktika
02.01.2008 – 07.03.2008 Kaufmännisch verwaltendes Praktikum bei der Firma
Stiebel Eltron, Holzminden
Berufserfahrung
2012 Tätigkeit als Parkbetreuerin bei der Organisation „Die
Kinderfreunde“, Wien
2008 Au Pair in Harpenden, Hertfordshire, Großbritannien
2007 – 2009 Öffentlichkeitsarbeit für den Rettungsdienst „Die
Johanniter“, Deutschland

SUBLIMINALES SYNTAKTISCHES PRIMING 63
Ehrenamtliche Tätigkeiten
2003 – 2005 Trainerin einer Basketballmannschaft für Kinder im Alter
von 7 bis 12 Jahren, Holzminden, Deutschland
2002 – 2005 Leitung einer türkischen Mädchengruppe im Alter von 14
bis 17 Jahren, Holzminden, Deutschland
Kenntnisse und Fähigkeiten
Sprachkenntnisse
Deutsch
Türkisch
Englisch
Französisch
EDV Kenntnisse
Microsoft Office
SAP
SPSS
Adobe Photoshop
Führerschein Klasse B
Hobbies
Reisen
Lesen
Basketball
Tanzen