reinforcement learning an einem omnidirektionalen mobilen ... · unabh¨anging von der...
TRANSCRIPT

Reinforcement Learning an einem omnidirektionalen
mobilen Roboter
Luca Siciliano Viglieri
Hauptseminar Lernverfahren der Neuroinformatik und Robotik,Universitat Ulm, Abteilung Neuroinformatik, SS 2006
1 Einleitung
Mobile Roboter agieren in komplexen unbekannten Umgebungen wie beispielsweise inBuros und Haushalten. Dabei ist der Roboter mit einer Vielzahl von statischen und be-weglichen Hindernissen konfrontiert. Er muss auf Veranderungen in der Umgebung inEchtzeit reagieren und sich trotzdem mit einer angemessenen Geschwindigkeit bewegen.Globale Pfadplanungsmethoden greifen auf ein Weltmodell zuruck, das mit zahlreichenUnsicherheiten behaftet ist und lange Berechnungszeiten erfordert. Um eine sichere Bewe-gung zwischen den Hindernissen zu ermoglichen, ist daher eine lokale Kollisionsvermeidungnotwendig, die direkt auf den Sensordaten basiert und gezielt arbeitet.Der Robocup stellt eine ideale Testumgebung fur Probleme der Bewegung mobiler Robo-ter dar. In der Middle Size League muss der Roboter vollig autonom, nur auf Basis lokalerSensordaten, navigieren.Im Rahmen dieser Arbeit wurde eine Methode zur Pfadsuche und Kollisionsvermeidungbeschrieben, die ein Umgebungsmodell verwendet.
2 Beschreibung des Problems
2.1 Omnidirektionaler mobile Roboter
Es gibt verschiedene Arten von Robotern, die durch ihren Bewegungmechanismus cha-rakterisiert werden. Roboter konnen sich z.B. durch Rader oder Beine bewegen. JederMechanismus hat seine eigenen Vor- und Nachteile: durch Rader konnen Roboter eine ho-he Geschwindigkeit erreichen und sie verleihen ihnen dazu auch gute Stabilitat. Dennochhaben sie oft Schwierigkeiten mit unebenen Wegen, wie z.B. einer Treppe.Beine geben Robotern grosse Freiheit, machen sie dafur aber langsamer: die humanoidenRoboter, die nur zwei Beine haben, brauchen daher eine sehr gute Kontrolle um stabil zusein.In unserer Testumgebung bewegt sich der Roboter ausschließlich in der Ebene, d.h. in ei-nem zweidimensionalen Raum. Fur den verwendeten Algorithmus fallt die Wahl auf einenradbasierten omnidirektionalen Roboter, um eine einfache und effiziente Kontrolle zu ha-ben. Im Gegensatz zu differezial drive Robotern konnen diese in jede Richtung fahren,
10. Juli 2006

unabhanging von der Orientierung. Um das zu ermoglichen hat der Roboter keine norma-len Rader, sondern die sogenannten OmniWheels. Ihre Besonderheit liegt darin, dass siewie normale Rader rollen konnen, aber, dank am Rand plazierter kleiner Rollen, sich querzur normalen Richtung bewegen konnen. Eine Kombination aus diesen zwei Bewegungenermoglicht dem Rad in jede beliebige Richtung zu fahren. Roboter, die mit OmniWheelausgestattet sind, haben eine grosse Flexibilitat und konnen hohe Geschwindigkeit errei-chen.Besonders zeichnet sie aus, dass sie jede Position in beliebiger Orientierung anfahrenkonnen.
Abbildung 1. Das Omniwheel
Abbildung 2. Der Roboter
Omni-Roboter konnen drei, vier oder mehr Rader haben, aber fur unsere Aufgabe reichenauch drei aus. Sie sind in dem sogenannten deta-array plaziert: die Achsen der Rader sindjeweils in einem Winkel von 120 Grad zur nachsten Achse angeordnet. In Wirklichkeit istder Winkel zwichen den Achsen nicht genau, weswegen ein Parameter δ, das den Fehlerbeschreibt, eingefugt wird. Alle Rader haben die gleiche Entfernung vom Masszentrum,welches ungefahr in der Mitte des Roboters steht. Die Achsen haben jedoch nicht diegleiche Lange: diese Eigenschaft ermoglicht dem Roboter ein Massezentrum abweichendvom Achsenzentrum zu haben.
Abbildung 3. Das Modell des Roboters
2

In der Abbildung 3 wird das Schema des Roboters gezeigt, in der mit L die Achenlange,R der Radius und δ der Winkel dargestellt ist. Die Kinematik wird durch eine Matrixbeschrieben, die einen Vektor mit x und y Koordinaten und einem Winkel in einen Vektormit den Geschwindigkeiten jedes Motors umwandelt.
Matrix:
Mt =1
R
− sin(δ + φ) cos(δ + φ) L1
− sin(δ − φ) − cos(δ − φ) L1
cos(φ) sin(φ) L2
Folgt die Gleichung:
θ1
θ2
θ3
=1
R
− sin(δ + φ) cos(δ + φ) L1
− sin(δ − φ) − cos(δ − φ) L1
cos(φ) sin(φ) L2
xw
yw
φ
Um die Koordinaten x,y und die Orientierung nach der Bewegung jedes Motors zu be-rechen, kann man einfach die Inverse der Matrix berechnen und diese mit dem Vektormultiplizieren.
xw
yw
φ
= M−t 1
θ1
θ2
θ3
2.2 Lernziel
Unsere Hauptaufgabe liegt darin, dass der Roboter lernt von einer Stelle A zu einer Stel-le B zu fahren. Spater werden wir diese Aufgabe mit der Vermeidung von Hindernissenerweitern.Um das Ziel zu erreichen muss der Roboter die richtige Geschwingkeit fur jeden Motoreinsetzen und beachten, dass am Ziel die Orientierung stimmt. Aus diesem Grund benoti-gen wir eine gute und flexible Darstellung des Problems, die uns ermoglicht den richtigenAlgorithmus zu finden. Nutzlich ist die Definition des Target Frames : das ist ein Vektormit den x -,y-Koordinaten und der Orientierung bezuglich des Ziels. In diesem Fall, umBerechnungen zu sparen, ist das Ziel als 0-Vektor reprasentiert, d.h. der Roboter mussdie null-Stelle mit Orientierung null erreichen. In unserer Umgebung werden wir das Zielals Koordinatenzentrum betrachten. Die Position des Roboters in diesem Koordinatesy-stem ist gleich der Entfernung des Roboters vom Ziel. Dieser Abstand wird als Vektor
3
reprasentiert:
RTF =
xTF
yTF
ΦTF
Daraus ergibt sich also, dass die Aufgabe des Roboters darin besteht diesen Abstand zuverringern. Auf diese Weise haben wir das Problem vereinfacht. Nun muss die Maschinenur das Koordinatenzentrum erreichen bzw. die Werte des Abstandsvektors annullieren.
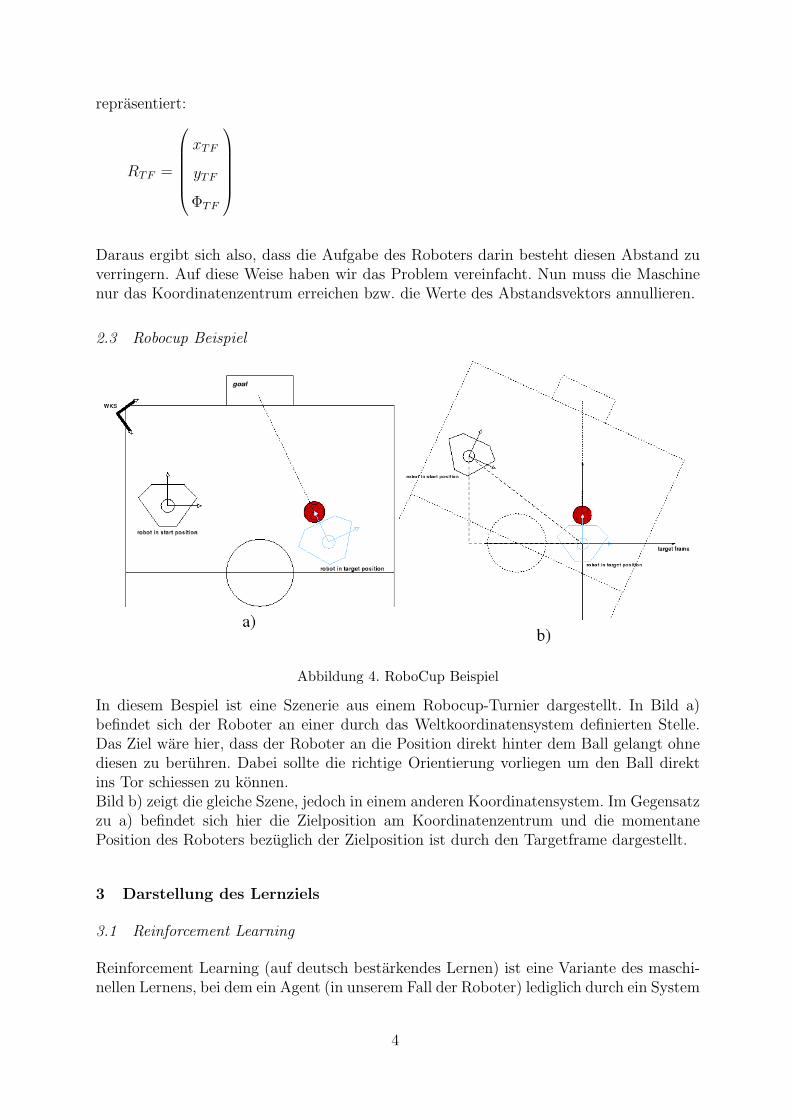
2.3 Robocup Beispiel
Abbildung 4. RoboCup Beispiel
In diesem Bespiel ist eine Szenerie aus einem Robocup-Turnier dargestellt. In Bild a)befindet sich der Roboter an einer durch das Weltkoordinatensystem definierten Stelle.Das Ziel ware hier, dass der Roboter an die Position direkt hinter dem Ball gelangt ohnediesen zu beruhren. Dabei sollte die richtige Orientierung vorliegen um den Ball direktins Tor schiessen zu konnen.Bild b) zeigt die gleiche Szene, jedoch in einem anderen Koordinatensystem. Im Gegensatzzu a) befindet sich hier die Zielposition am Koordinatenzentrum und die momentanePosition des Roboters bezuglich der Zielposition ist durch den Targetframe dargestellt.
3 Darstellung des Lernziels
3.1 Reinforcement Learning
Reinforcement Learning (auf deutsch bestarkendes Lernen) ist eine Variante des maschi-nellen Lernens, bei dem ein Agent (in unserem Fall der Roboter) lediglich durch ein System
4

von Belohnung und Bestrafung lernt seine Strategie zu optimieren. Eine Taktik ist eineFunktion, die jedem Zustand (anschaulich: Position des Agenten in seiner Umgebung)eine Aktion zuordnet. Die optimale Strategie bezuglich eines bestimmten Zustandsraumsist diejenige, die den Nutzen des Agenten maximiert. Dafur muss eine Nutzenfunktiongelernt werden, die jedem Zustand einen Wert zuweist. Jeder Zustand, sowie die Aktio-nen, sollen in einem Markovschen Entscheidungsproblem (auf englisch Markov DecisionProblem) definiert werden.
3.2 Markovsche Entscheidungsprobleme
Fur unsere Arbeit, wird das MDP als eine vierdimensionale Tuple (S, A, T, r) beschrieben,wo:
S : Zustandsmenge (alle moglische Zustande)A : Aktionsmenge (alle moglische Aktionen)T : probabilistische Transitionsfunktion T : S × A × S → [0, 1], die die Wahrscheinlich-
keit einer Transition von Zustand s zum Zustand s’ bezeichnet, wenn eine Aktion adurchgefuhrt wird
r : S × A → R ist die Belohnungsfunktion, die die direkte Belohnung bezeichnet, wenneine Aktion a in dem Zustand s durchgefuhrt wird.
Abbildung 5. Eine markovschen Kette
In unserem Fall verwenden wir ein deterministisches MPD, d.h. die Transitionfunktion Tist entweder 1 oder 0.
3.3 Der Lernalgorithmus
Der Reinforcement Learning Lernalgorithmus soll mit einer Menge von Zustanden undAktionen mit Hilfe der Transitionfunktion und der Belohnungsfunktion eine gute Nut-zenfunktion liefern. Mit gut ist gemeint, wenn diese Funktion den Agenten mit hoherWahrscheinlichkeit zum Ziel bringt. Der Lernalgorithmus hat vier Phasen: Initialisierung,Aktionssuche, Durchfuhren der Aktion und Adaptierung. Das ist der Pseudo-Code:
Init system with initial state s0 ∈ S0
While Not (stop condition) {Choose action
at = minApply
st+1 = f(st, at)
5

AdaptJk+1(st) = r(st, at) + Jk(st+1)
}who
at : ausgesuchte Aktion im Schritt tA(st) : Aktionsmenge im Zustand st
st+1 : nachster Zustandf(st, at) : Funktion, die nach der Aktion at den nachsten Zustand liefert
J(st) : Nutzenfunktion von st die adaptiert werden sollr(st, at) : Kostfunktion, die die Sofortbelohnung liefert
In diesem Algorithmus ist die Zeit diskretisiert, d.h. der Roboter bewegt sich Schrittweise.In jedem Schritt t, erkennt der Roboter den Zustand st und die Aktionsmenge A(st). Umden Zustand zu wechseln sucht die Maschine eine Aktion at. Diese Suche ist abhanging vonder Nutzenfunktion J und funktioniert nach der greedy-Methode, welche die ausgesuchteAktion zu einem kleineren Wert von J(st+1) fuhrt. Dieses Verfahren wird sowohl in derLernphase als auch in der Testphase benutzt.
3.4 Darstellung des Problems
Um unsere Anwendung als MDP zu beschreiben, brauchen wir die Definition von TargetFrame: der Zustand des Roboters ist als Vektor RTF dargestellt und kann st so definiertwerden:
st = RtTF = (xt
TF , ytTF , Φt
TF )T
Mit beliebigen Werten von x, y, Φ hatten wir unendlich viele Zustande. Deswegen be-schranken wir den Raum, den wir Arbeitsraum nennen:
Sw = {s|xTF , yTF ∈ [−1, 1], ΦTF ∈ [−PI, PI]}
Jetzt sind noch die Aktionen die der Roboter durchfuhren kann zu definieren. Der Roboterkann jedes der drei Rader mit einer bestimmten Geschwindigkeit bewegen und hat furjedes Rad drei verschiedene Bewegungsmoglichkeiten: vorwarts fahren, ruckwarts fahrenoder stehen bleiben. Es folgt also daraus, dass der Roboter (3x3x3 = ) 27 verschiedenemogliche Aktionen durchfuhren kann. Die Aktionmenge ist wie folgt definiert:
A = {a = (Θ1, Θ2, Θ3)|Θ1, Θ2, Θ3 ∈ {−v, 0, v}}
wo v die Geschwindigkeit jedes Motors ist, die, um eine glatte Bewegung zu haben, auf10 rad/s gesetzt ist.
Bisher haben wir noch nicht die Belohnung erlautern, die den wichtigsten Teil des Algo-rithmus darstellt. Zu diesem Zweck definieren wir zwei Mengen S+ und S−.
6

Wenn der Roboter einen Zustand der Menge S+ erreicht, so bekommt er eine Belohnung.Erreicht er einen Zustand der Menge S−, so bekommt er eine negative Ruckmeldung.
Unsere Aufgabe besteht darin den Roboter an den null-Punkt zu bringen. Der Zielpunktist deshalb die Menge S+
S+ = {s|xTF , yTF ∈ [−0.05, 0.05], ΦTF ∈ [−0.05, 0.05]}
Zu der Menge S− gehoren die verbotenen Orte, wie beispielsweise die, die zu weit etferntsind, oder jene, an denen sich die Hindernisse (in diesem Fall der Ball) befinden.
S− = {s|s /∈ Sw} fur Aufgabe 1
S− = {s|s /∈ Sw ands ∈ Ball} fur Aufgabe 2
Jetzt sind wir in der Lage, die richtige Kostenfunktion zu definieren.
r(s, a) = r(s) :=
r− if s ∈ S−;
r+ if s ∈ S+;
rtrans else.
4 Approximatoren
Da der Raum kontinuierlich ist wurden wir fur die Nutzenfunktion zu viel Speicher undZeit brauchen. Aus diesem Grund ist es notwending diese Funktion zu approximieren,wofur verschiedene Verfahren zur Verfugung stehen, welche in drei Gruppe aufgeteilt sind:lineare Approximatoren (z.B. grid based approximator), nicht-lineare Approximatoren(z.B.neurale Netze) und adaptive lineare Approximatoren (z.B. regression trees). Ein Beweisdafur, dass diese Algorithmen immer in die Nutenfunktion konvergieren gibt es noch nicht,jedoch haben sie in der Praxis oft Anwendung gefunden, da sich mit Hilfe ihrer Speicherund Zeit sparen lasst. Zur Losung unserer Aufgabe verwenden wir zwei Approximatoren,ein grid-based und ein neurales Netz. Die Ergebnisse dessen werden verglichen.
7
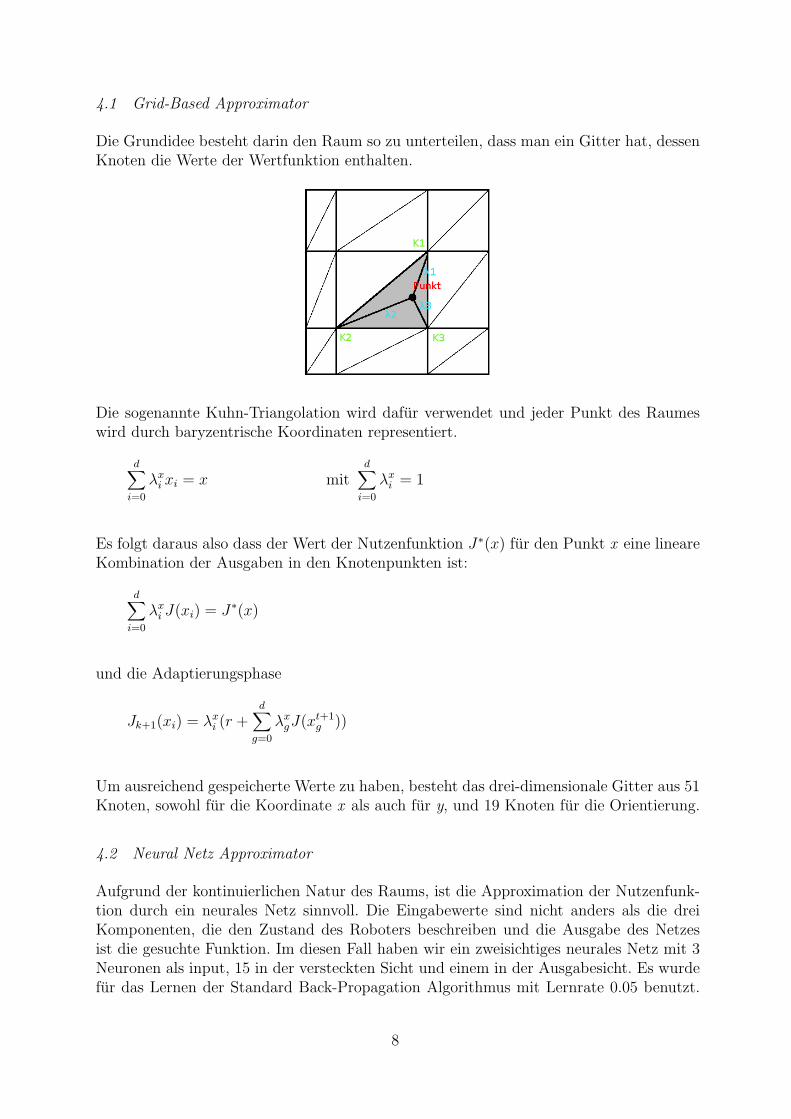
4.1 Grid-Based Approximator
Die Grundidee besteht darin den Raum so zu unterteilen, dass man ein Gitter hat, dessenKnoten die Werte der Wertfunktion enthalten.
Die sogenannte Kuhn-Triangolation wird dafur verwendet und jeder Punkt des Raumeswird durch baryzentrische Koordinaten representiert.
d∑
i=0
λxi xi = x mit
d∑
i=0
λxi = 1
Es folgt daraus also dass der Wert der Nutzenfunktion J∗(x) fur den Punkt x eine lineareKombination der Ausgaben in den Knotenpunkten ist:
d∑
i=0
λxi J(xi) = J∗(x)
und die Adaptierungsphase
Jk+1(xi) = λxi (r +
d∑
g=0
λxgJ(xt+1
g ))
Um ausreichend gespeicherte Werte zu haben, besteht das drei-dimensionale Gitter aus 51Knoten, sowohl fur die Koordinate x als auch fur y, und 19 Knoten fur die Orientierung.
4.2 Neural Netz Approximator
Aufgrund der kontinuierlichen Natur des Raums, ist die Approximation der Nutzenfunk-tion durch ein neurales Netz sinnvoll. Die Eingabewerte sind nicht anders als die dreiKomponenten, die den Zustand des Roboters beschreiben und die Ausgabe des Netzesist die gesuchte Funktion. Im diesen Fall haben wir ein zweisichtiges neurales Netz mit 3Neuronen als input, 15 in der versteckten Sicht und einem in der Ausgabesicht. Es wurdefur das Lernen der Standard Back-Propagation Algorithmus mit Lernrate 0.05 benutzt.
8

Output
Input
Hidden Layer
x y Φ
J
Abbildung 6. Das verwendete neurale Netz
Leider konnen wir nicht die normale Gleichung in der Adaptierungsphase verwenden, son-dern nur eine Variante, die den Unterschied zwischen der alten Ausgabe und dem neuenWert berechnet.
etd := (J(st)− (r(st, at) + J(st+1))2
Diese Ausgabe wird nach dem Back-Propagation Algorithmus benutzt, um die Gewichtezu andern. Was gewunscht wird, ist die Verringerung des Unterschieds zwichen der Ausga-be des Netzes und der Nutzenfunktion. Dies kann durch den klassischen Gradient Abstiegerreichen werden.
5 Ergebnisse
5.1 Aufgabe 1
Zuerst betrachten wir die erste Aufgabe bzw. dass der Roboter das Ziel ohne Berucksich-tigung der Hindernisse erreichen soll. Wir mussen zwei Menge S0 definieren: eine fur dasLernen und eine andere fur das Testen. Fur die beim Lernen benutzte Menge haben wirdie Punkte, die in einem Gitter 5x5x5 im Arbeitsraum liegen und damit eine Anzahl von125 Startpositionen haben. Fur das Testen reicht die gleiche Anzahl von Punkten, aberdieses Mal ist die Lage zufallig gewahlt.
Um die Qualitat der resultierenden Nutzenfunktionen zu prufen, berechnen wir den Mit-telwert der Summe an Erfolgen und den Mittelwert der Kosten fur jede Bahn in jederEpoche. Wichtig ist ,dass keine Adaptierungsphase beim Testen stattfindet.
9
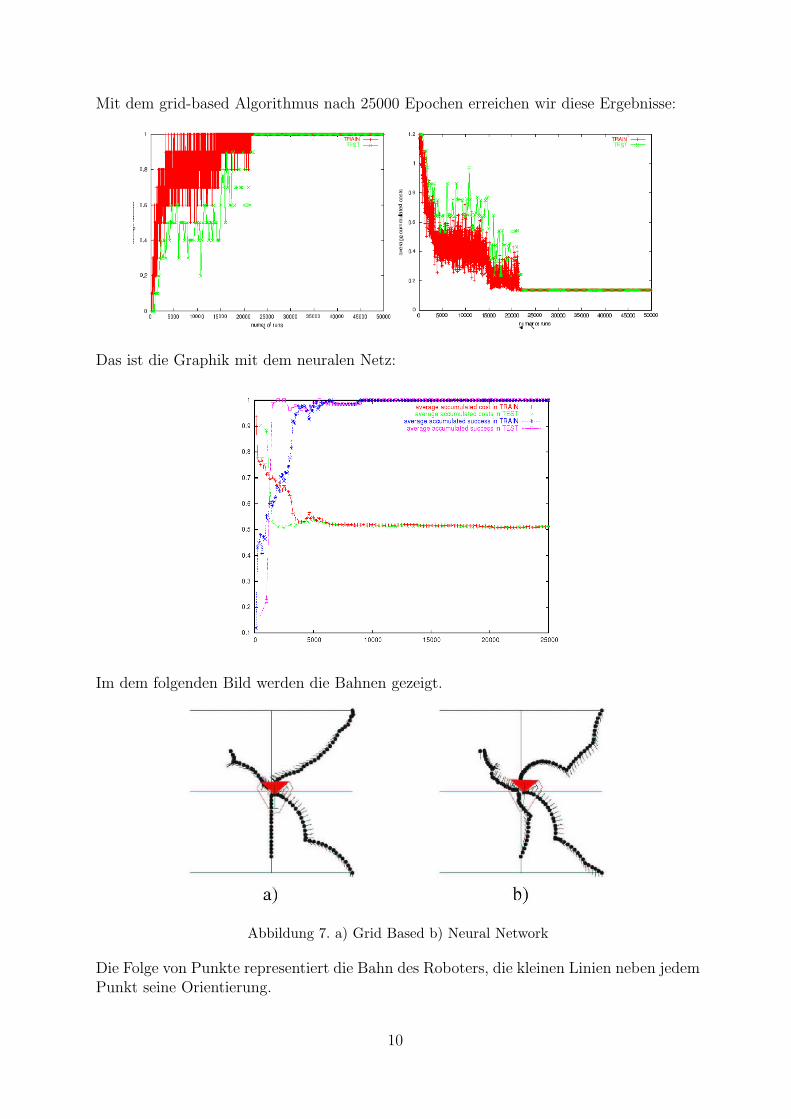
Mit dem grid-based Algorithmus nach 25000 Epochen erreichen wir diese Ergebnisse:
Das ist die Graphik mit dem neuralen Netz:
Im dem folgenden Bild werden die Bahnen gezeigt.
Abbildung 7. a) Grid Based b) Neural Network
Die Folge von Punkte representiert die Bahn des Roboters, die kleinen Linien neben jedemPunkt seine Orientierung.
10
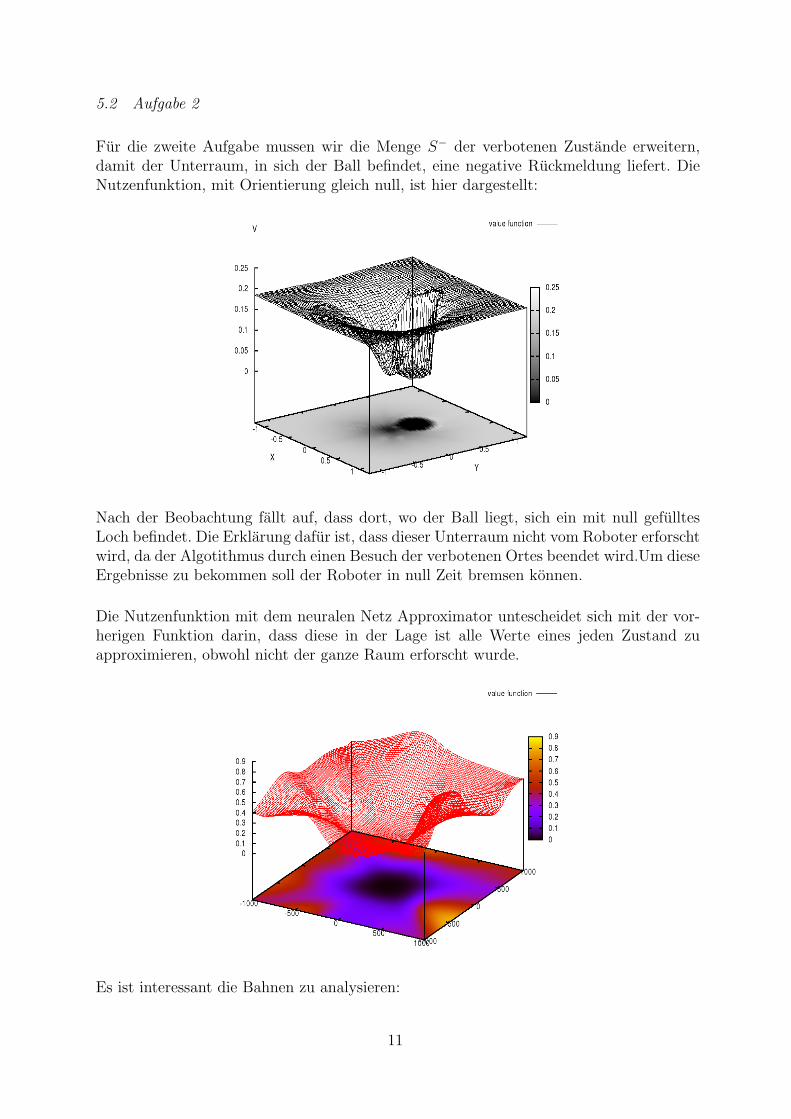
5.2 Aufgabe 2
Fur die zweite Aufgabe mussen wir die Menge S− der verbotenen Zustande erweitern,damit der Unterraum, in sich der Ball befindet, eine negative Ruckmeldung liefert. DieNutzenfunktion, mit Orientierung gleich null, ist hier dargestellt:
Nach der Beobachtung fallt auf, dass dort, wo der Ball liegt, sich ein mit null gefulltesLoch befindet. Die Erklarung dafur ist, dass dieser Unterraum nicht vom Roboter erforschtwird, da der Algotithmus durch einen Besuch der verbotenen Ortes beendet wird.Um dieseErgebnisse zu bekommen soll der Roboter in null Zeit bremsen konnen.
Die Nutzenfunktion mit dem neuralen Netz Approximator untescheidet sich mit der vor-herigen Funktion darin, dass diese in der Lage ist alle Werte eines jeden Zustand zuapproximieren, obwohl nicht der ganze Raum erforscht wurde.
Es ist interessant die Bahnen zu analysieren:
11

Abbildung 8. a) Grid Based b) Neural Network
Der Unterschied zwischen den zwei Approximatoren besteht darin, dass der grid-basedApproximator kurze Bahnen mit viele Korrekturen generiert, der neurale Netz Approxi-mator dagegen flussigere Bewegungen mit langeren Bahnen produziert.
6 Zusammenfassung
Was hier gezeigt wurde, ist eine gute Anwendung von Reinforcement Learning: wir habendamit demonstriert, dass man mit Reinforcement Learning in der Lage ist, schwierigeAufgaben zu losen,z.B. die Kontrolle eines Roboters. Das Ziel, einen omnidirektionalenRoboter durch die Bewegung von drei unabhangigen Radern an eine bestimmten Stelle zubringen, wurde mit Erfolg erreicht. Nach der Definition von statischen verbotenen Stellenwar der Roboter in der Lage Hindernisse zu vermeiden. Unsere letzte Aufgabe ware denLernalgorithmus auf einer echten Maschine laufen zu lassen. Dafur reicht unser Modell derWelt nicht: wir mussen in jedem Moment die aktuelle Geschwindigkeit der Rader kennenund zudem muss das Modell die Beschleunigung und die Verzogerung beschreiben.
Der Nachteil unseres Lernalgorithmus ist, dass er sehr langsam ist. Jede Epoche dauertdurchnittlich 5 Sekunden, und falls wir, wie in dem Beispiel, 25000 davon brauchen, be-kommen wir die approximierte Nutzenfunktion erst nach ungefahr 35 Stunden. Das warezu viel Zeit fur einen Wettbewerb wie Robocup. Weitere Verbesserungen konnte man mitdem Q-Learning Algorithmus oder mit einer Verbesserung der Hardware bekommen.
Literatur
[1] Roland Hafner und Martin Riedmiller:Reinforcement Learning on a Omnidirectional MobileRobot. Submitted to IEEE/RSJ International Conference on Intelligent Robots and Systemsfor Human Security, Health, and Prosperity, 2003.
[2] J. Weisbrod and M. Riedmiller and M. Spott. Fynesse: A hybrid architecture for self-learningcontrol. In I. Cloete and J.M. Zurada, editors, Knowledge Based Neuro Computing. MITPress, 1999
12

[3] Merke, A. and Schoknecht, R..: A Necessary Condition of Convergence in ReinforcementLearning with Function Approximation. In International Conference on Machine Learning(ICML 2002). Morgan Kaufmann (2002).
[4] Wikipedia
[5] Richard S.Sutton and Andrew G.Barto: Reinforcement Learning. A Bradford Book.The MITPress.Cambridge, Massachusetts, London,England
13